
Logan Kilpatrick, der bei OpenAI für die Beziehungen zu den Entwicklern zuständig ist, sieht Prompt Engineering als "Fehler und nicht als Funktion".
Prompting als Fähigkeit sei nicht anders als die Fähigkeit, effizient mit Menschen zu sprechen. Die "harte Arbeit", einen Prompt im Detail zu formulieren, müsse von KI-Systemen übernommen werden.
Das wiederum werte die drei Fähigkeiten Lesen, Schreiben und Sprechen auf. Zwar könne man mit speziellen Prompts gelegentlich fünf Prozent mehr Leistung erzielen. Der Aufwand für gute Ergebnisse würde aber in Zukunft um den Faktor 10 sinken, so dass sich spezielle Prompts nicht mehr lohnen würden.
OpenAI hat bereits bei der Veröffentlichung von DALL-E 3 deutlich gemacht, dass es komplexe Prompts eher als hinderlich ansieht: Die konkreten, sehr detaillierten Prompts schreibt die Bild-KI einfach selbst auf Basis der Nutzerwünsche. Bei der Veröffentlichung der Software hat OpenAI explizit darauf hingewiesen, dass komplexe Prompts nicht mehr notwendig seien.
Prompting überflüssig? Big AI macht’s nicht vor
Kilpatricks Prognose steht in krassem Gegensatz zu der Art und Weise, wie Big AI derzeit selbst Sprachmodelle und deren Fortschritte präsentiert: Hier spielt Prompting eine ganz wesentliche Rolle, um Bestwerte in Benchmarks zu erzielen.
So nutzte Google bei der Vorstellung von Gemini Ultra ein komplexes Prompting-Verfahren, um im viel beachteten Sprachverständnis-Benchmark MMLU einen neuen Bestwert zu erzielen.
Dabei wurde das eigene Modell Gemini Ultra mit GPT-4 mit einem alternativen, weniger leistungsfähigen Prompting-Verfahren verglichen, was Google Kritik einbrachte.
Kurz darauf konterten Microsoft und OpenAI mit einem noch komplexeren Prompt: Dank einer adaptierten Variante des für medizinische Zwecke entwickelten "Medprompt" schlug GPT-4 Gemini Ultra im MMLU erneut.
Aber Medprompt selbst ist wiederum ein anschauliches Beispiel für die Bedeutung guter Prompts: Es konnte die Trefferquote von GPT-4 im MedQA-Datensatz auf über 90 Prozent anheben, mit einer Leistungssteigerung von etwa acht Prozent.

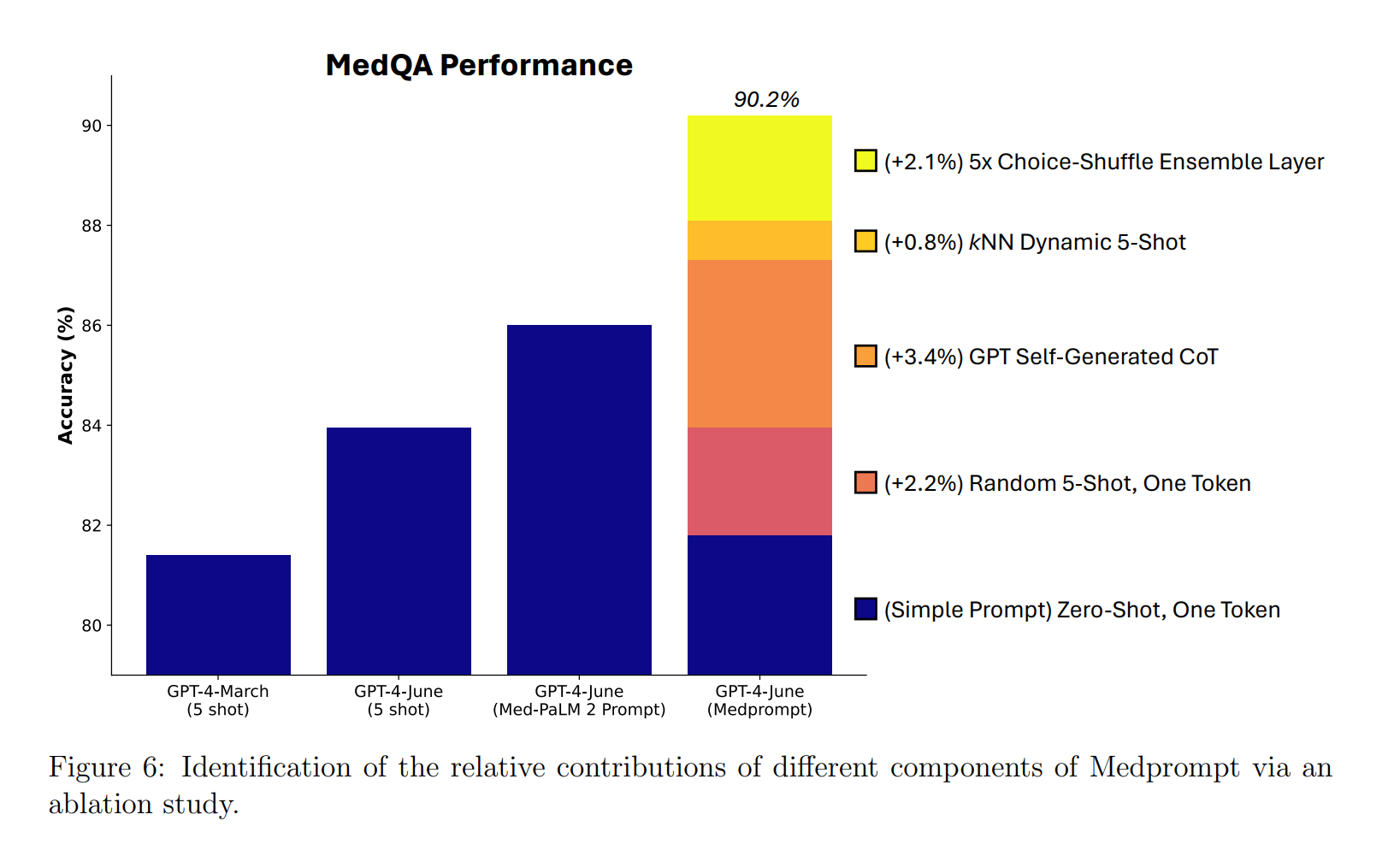
In der Praxis können diese acht Prozent den Unterschied zwischen "unbrauchbar" und "brauchbar" ausmachen, wenn es um die Genauigkeit bei der Beantwortung medizinischer Fragen geht.
Auf der anderen Seite, und das ist das Zukunftsszenario, das Kilpatrick meint: Wenn GPT-5 und Co. in diesem Beispiel von Haus aus deutlich an der 90-Prozent-Marke liegen, verliert ein Verfahren wie Medprompt an Relevanz.



