Qwen2.5-1M: Open-Source-Modell kann bis zu 1 Million Token verarbeiten

Alibabas Qwen-Team hat seine Qwen2.5-Serie mit Qwen2.5-7B-Instruct-1M und Qwen2.5-14B-Instruct-1M um zwei Open-Source-Modelle mit Kontextfenstern von bis zu einer Million Token erweitert.
Kürzlich hatten die Forschenden bereits das Kontextfenster von Qwen2.5-Turbo auf eine Million Token verlängert. Dieses Modell ist jedoch nur per API nutzbar. Die neuen Qwen-Versionen sind demnach die ersten als Open Source verfügbaren Sprachmodelle, die einen so großen Kontext unterstützen. Die Qwen2.5-Serie wurde erstmals im September 2024 eingeführt.
Qwen2.5-1M zeigt starke Leistung bei langen Kontexten
Das Modell nutzt einen als "Sparse Attention" bezeichneten Ansatz, bei dem nur die wichtigsten Teile des Kontexts für die Verarbeitung berücksichtigt werden. Dadurch kann es Eingaben mit einer Million Token drei bis siebenmal schneller verarbeiten als herkömmliche Methoden. Die Ausgabelänge liegt bei 8.000 Token.
Die Qwen2.5-1M-Modelle wurden in verschiedenen Benchmarks für Aufgaben mit bis zu einer Million Token Kontext getestet. In einem Benchmark, bei dem versteckte Zahlen aus extrem langen Dokumenten abgerufen werden mussten, erzielten sowohl Qwen2.5-14B-Instruct-1M als auch Qwen2.5-Turbo zuvor eine Genauigkeit von 100 Prozent.
Das kleinere Qwen2.5-7B-Instruct-1M-Modell schnitt mit nur wenigen Fehlern ebenfalls beeindruckend ab. Es ist jedoch wichtig anzumerken, dass diese Art von Benchmark nicht unbedingt die tatsächliche Leistung in realen Anwendungen widerspiegelt. Er prüft nur, ob bestimmte Informationen gefunden werden, eine Art teures Strg+F, und nicht, ob das Modell etwa bei einer Abwägungsfrage den gesamten Inhalt berücksichtigt.
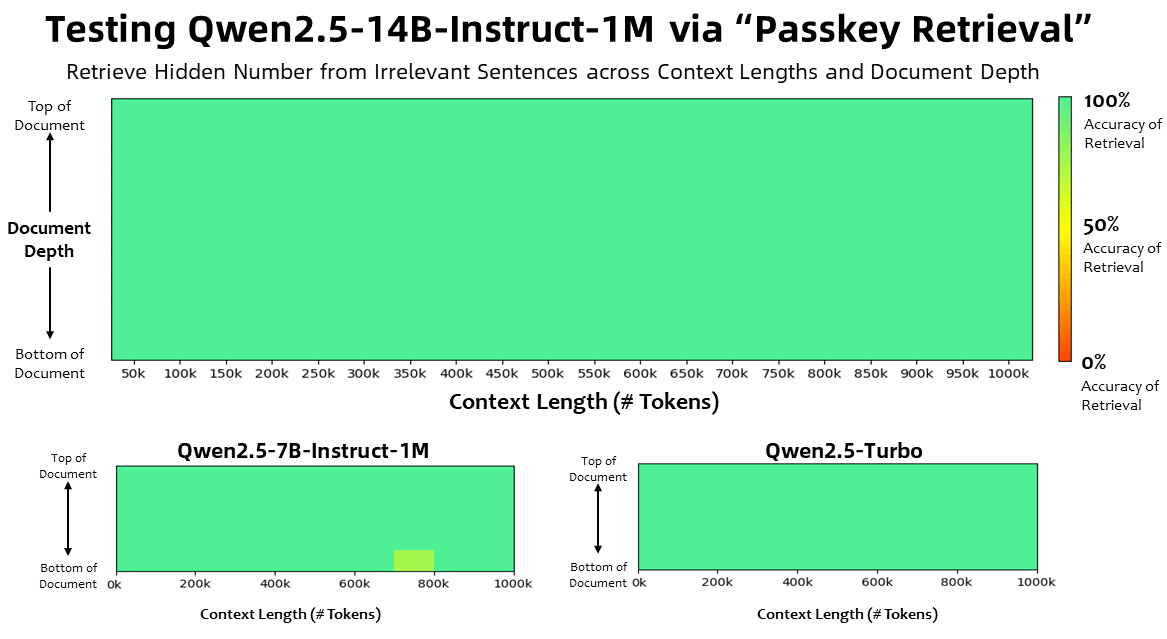
Der Nutzen solch großer Kontextfenster ist im Vergleich zu den in vielen Fällen zielführenderen RAG-Architekturen, die externe Daten aus Vektordatenbanken zur Inferenz heranziehen, aber mit Kontextfenstern in der Größenordnung von 128.000 Token auskommen, bisher nicht wirklich erwiesen.
In anspruchsvolleren Benchmarks wie RULER, LV-Eval und LongbenchChat übertrafen die 1M-Modelle ihre Gegenstücke mit 128K-Token-Kontext in den meisten Aufgaben mit langem Kontext, insbesondere bei Sequenzen mit mehr als 64K Token.

Das Qwen2.5-14B-Instruct-1M-Modell erreichte als erstes Modell der Qwen-Serie die 90-Punkte-Marke im RULER-Benchmark und übertraf durchweg GPT-4o mini in mehreren Datensätzen. Damit bietet es eine leistungsstarke Open-Source-Option für Aufgaben mit langem Kontext.
Bei kurzen Texten erzielten die 1M-Modelle ähnliche Ergebnisse wie die 128K-Versionen, was zeigt, dass ihre Fähigkeiten durch die Optimierung für lange Kontexte nicht beeinträchtigt wurden.
Alibaba beschreibt mehrere Schlüsseltechniken für das Training der 1M-Modelle, darunter die Verwendung synthetischer Daten, eine schrittweise Erweiterung der Kontextlänge und mehrstufiges überwachtes Feintuning.
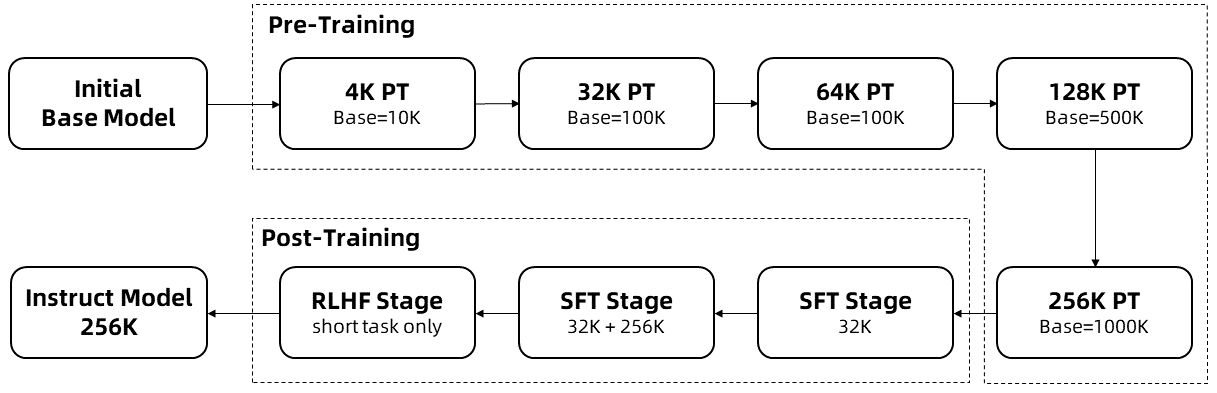
Für die Inferenz setzt Alibaba auf Methoden zur Längenextrapolation, die es ermöglichen, die Kontextlänge ohne zusätzliches Training um mindestens das Vierfache zu erweitern.
Weiterer KI-Druck aus China
Kürzlich hat Alibaba mit Qwen Chat eine ChatGPT-ähnliche Oberfläche vorgestellt, über die sich verschiedene Alibaba-Modelle wie auch die 14B-Variante mit ihrem Millionen-Kontext ausprobieren lassen. Alternativ steht eine Demo auf Hugging Face bereit.
Neben Alibabas Qwen macht gerade das chinesische Unternehmen Deepseek momentan von sich reden. Die ebenfalls quelloffen entwickelten Sprachmodelle üben mit deutlich niedrigeren Kosten Druck auf etablierte US-Anbieter aus.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.