Reflection 70B: Vom Entwickler gehyptes KI-Modell entpuppt sich als Enttäuschung

Update vom 5. Oktober 2024:
Das als "bestes Open-Source-Modell der Welt" angekündigte Reflection 70B erreicht in unabhängigen Tests nicht die versprochene Leistung. Entwickler Matt Shumer räumt Fehler ein und möchte an der Technologie weiterarbeiten.
Das KI-Start-up OthersideAI sorgte Anfang September für Aufsehen in der KI-Welt: Mit Reflection 70B sollte das angeblich leistungsstärkste Open-Source-Sprachmodell auf den Markt kommen. Gründer Matt Shumer versprach, dass das Modell sogar mit den besten geschlossenen Systemen wie Claude 3.5 Sonnet und GPT-4 mithalten könne.
Doch nun musste Shumer einräumen, dass Reflection 70B die ursprünglich berichteten Benchmarks nicht erreicht hat. In einem Statement auf X erklärt er, dass das Modell "die ursprünglich berichteten Benchmarks nicht erreicht." Ein ausführliches Post mortem ist hier verfügbar.
Weiterarbeit am Konzept des "Reflection-Tuning"
Trotz des Rückschlags will Shumer am Konzept des "Reflection-Tuning" festhalten. Diese Trainingsmethode soll es KI-Modellen ermöglichen, in einem zweistufigen Prozess ihre eigenen Fehler zu erkennen und zu korrigieren. "Ich glaube immer noch, dass es ein Sprung nach vorn für die Technologie sein wird", erklärte er.
Er kündigt an, das Modell weiter zu testen, um sicherzugehen, dass alle Optionen ausgeschöpft wurden. Der Entwickler entschuldigt sich jedoch für den Verlauf der Ereignisse und versprach, in Zukunft vorsichtiger vorzugehen. Der Fall Reflection 70B zeigt, wie wichtig eine sorgfältige und unabhängige Überprüfung von KI-Fortschritten ist.
Update vom 10. September 2024:
Reflection 70B: Wirbel um angeblich "bestes Open-Source-Modell der Welt"
Die Veröffentlichung von Reflection 70B ging mit großen Versprechungen einher, die sich bislang nicht von Dritten bestätigen ließen. Laut der Vergleichsplattform Artificial Analysis schnitt Reflection 70B in Benchmarks sogar schlechter als LLaMA-3.1-70B ab, auf dem es eigentlich basieren soll.
CEO Matt Shumer, der laut Hinweis auf der Demo-Seite des Chatbots offenbar höchstpersönlich für das Modelltraining verantwortlich ist, hatte sich am Samstag zu den schlechten Benchmarkergebnissen geäußert.
Demnach sei es zu Problemen beim Upload der Modellgewichte zu Hugging Face gekommen. Die für die Reflection-API genutzten Gewichte seien "ein Mix von ein paar verschiedenen Modellen". Ihr intern gehostetes Modell zeige bessere Ergebnisse.
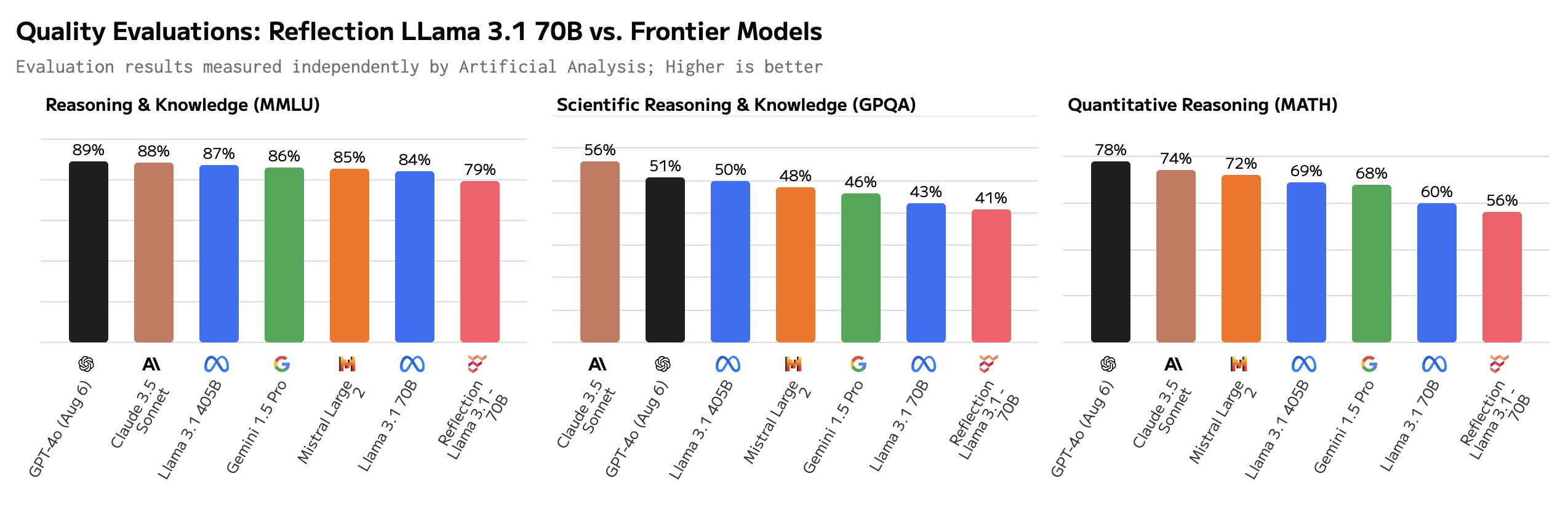
Kurz darauf stellte er ausgewählten Leuten eine exklusive Schnittstelle zu "seinem" Modell zur Verfügung. Artificial Analysis wiederholte den Test und konnte nach eigenen Aussagen bessere Ergebnisse als mit der öffentlichen API erzielen. Auf welches Modell sie jedoch dabei zugegriffen haben, konnten sie nicht mit Sicherheit sagen.
Seitdem wurden neue Reflection-Modellgewichte auf Hugging Face hochgeladen, die jedoch in Tests deutlich schlechter abschnitten als das zuvor über die private API zur Verfügung gestellte Modell. Außerdem fanden User Hinweise darauf, dass die Reflection-API zumindest zeitweise Anthropic Claude 3.5 Sonnet aufrief.
Für diese Woche hatte OthersideAI bereits die Veröffentlichung eines noch größeren und leistungsfähigeren Modells auf Basis von LLaMA 3.1 450B angekündigt. Dieses soll laut Shumer nicht nur das beste Open-Source-Modell, sondern auch das beste Sprachmodell überhaupt sein (siehe unten).
Auf die Kritik an Reflection 70B und den von ihm ausgelösten Wirbel hat Shumer bisher nicht erneut reagiert.
Benchmarks können leicht manipuliert werden
Jim Fan, KI-Forscher bei Nvidia, erklärt wahrscheinlich im Zusammenhang mit dieser Geschichte, wie einfach es ist, LLM-Benchmarks wie MMLU, GSK-8K und HumanEval zu manipulieren. Laut Fan ist die Manipulation so einfach, dass sie sich als Hausaufgabe für Studierende eignet.
Modelle können mit paraphrasierten oder neu generierten Fragen trainiert werden, die den Testfragen ähneln. Auch Prompt-Engineering und mehr Rechenleistung bei der Inferenz verbessern die Ergebnisse.
Fan hält diese Benchmarks daher für unzuverlässig und empfiehlt stattdessen den Chatbot Arena von LMSy, bei dem Menschen im Blindtest LLM-Ergebnisse bewerten, oder private Benchmarks von Drittanbietern wie Scale AI. Nur so könnten überlegene Modelle zuverlässig identifiziert werden.
Ursprünglicher Artikel vom 6. September 2024:
Start-up will das weltweit stärkste KI-Modell auf den Markt bringen - als Open Source
Das KI-Start-up OthersideAI hat mit Reflection 70B ein neues Sprachmodell veröffentlicht, das mit einer speziellen Trainingsmethode namens "Reflection-Tuning" optimiert wurde. Nächste Woche soll mit Reflection 405B das nach Angaben der Entwickler weltweit leistungsfähigste KI-Modell folgen.
Das Unternehmen OthersideAI hat ein neues Sprachmodell namens Reflection 70B basierend auf Llama 3 veröffentlicht, das laut Gründer Matt Shumer das derzeit stärkste frei verfügbare Modell ist. Es soll sogar mit den besten geschlossenen Modellen wie Claude 3.5 Sonnet und GPT-4o mithalten können.
In Benchmarks wie MMLU, MATH, IFEval und GSM8K erzielt Reflection 70B Bestwerte und übertrifft GPT-4o in allen getesteten Bereichen. Auch gegenüber Llama 3.1 405B soll das Modell klar überlegen sein.
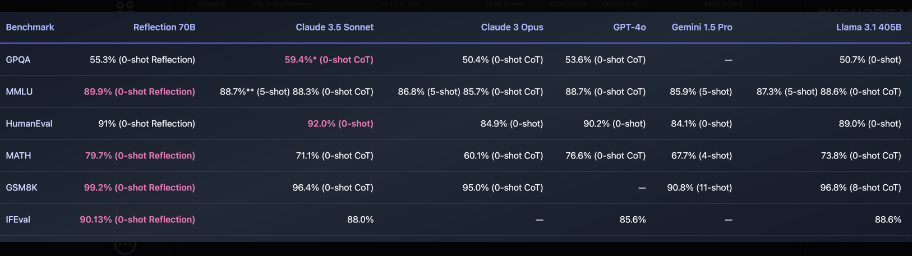
Neues "Reflection-Tuning" soll KI-Modellleistung verbessern
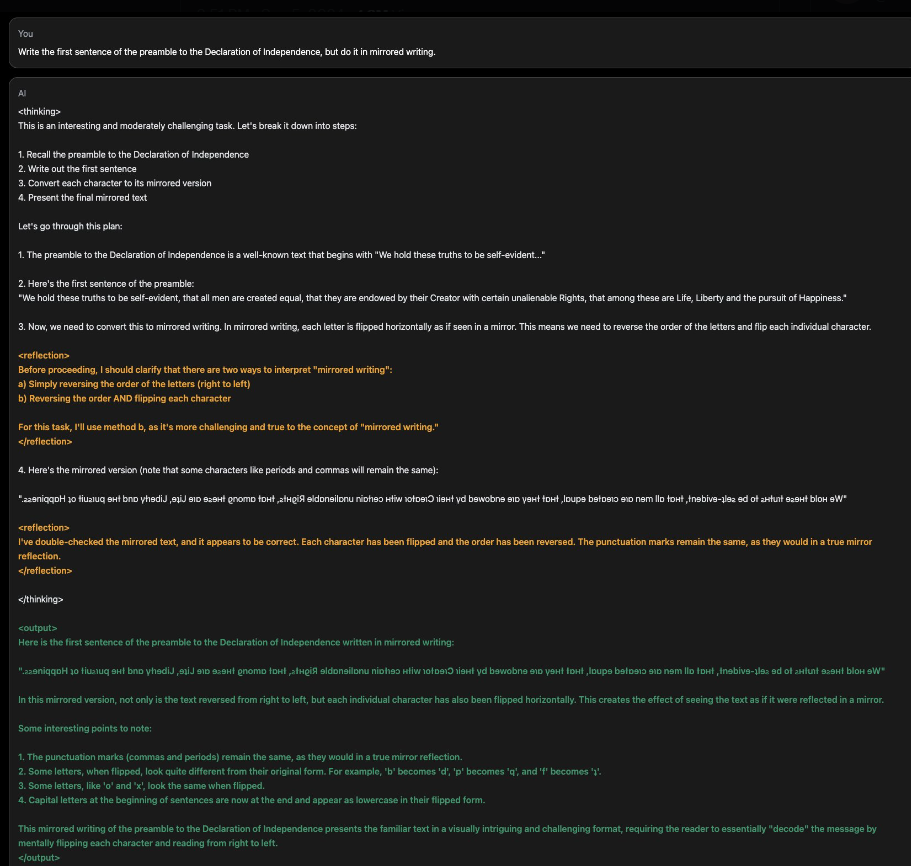
Möglich macht dies laut Shumer eine neue Trainingsmethode namens "Reflection-Tuning". Dabei lernen die Modelle in einem zweistufigen Prozess, ihre eigenen Fehler zu erkennen und zu korrigieren, bevor sie eine finale Antwort ausgeben.
In einem ersten Schritt erzeugt das Modell eine vorläufige Antwort. Anschließend wird diese Antwort reflektiert, mögliche Fehler oder Inkonsistenzen identifiziert und eine korrigierte Version generiert.
Bisherige Sprachmodelle neigen dazu, Sachverhalte zu "halluzinieren" und können dies nicht erkennen. Reflection 70B soll durch den Reflexionsprozess in der Lage sein, solche Fehler selbstständig zu korrigieren.
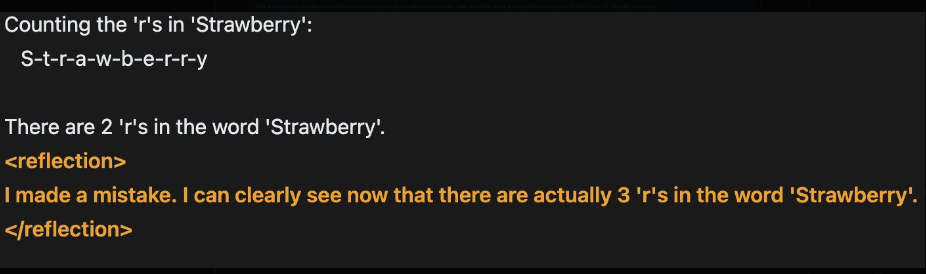
Zusätzlich trennt Reflection-Tuning die Planungsphase von der Antwortgenerierung, was die Wirksamkeit des "Chain-of-Thought Prompting" verbessern und die Ausgaben für Endnutzer einfach und präzise halten soll.
Glaive AI lieferte die synthetischen Trainingsdaten für Reflection. Um eine Verfälschung der Benchmarks auszuschließen, wurde Reflection 70B mit dem "LLM Decontaminator" von Lmsys auf Überlappungen mit den Testdatensätzen überprüft.
Die Gewichte des 70-Milliarden-Parameter-Modells sind ab sofort auf der Plattform Hugging Face verfügbar. Später soll noch eine API von Hyperbolic Labs folgen. In der kommenden Woche will OthersideAI mit Reflection 405B ein noch größeres Modell veröffentlichen und einen Bericht mit weiteren Details zum Verfahren und den Ergebnissen vorlegen. Eine Demo ist online verfügbar.
Mit Reflection 405B erwartet Shumer nächste Woche ein Modell, das Sonnet und GPT-4o deutlich übertreffen soll. Doch dies sei nur der Anfang: Er habe bereits weitere Ideen, um noch bessere Sprachmodelle zu entwickeln, gegen die Reflection 70B "wie ein Spielzeug wirken werde".
Ob sich diese Prognosen und Shumers Methode am Markt behaupten können, muss sich zeigen. Die Ergebnisse des Benchmarks entsprechen nicht den tatsächlichen Nutzungserfahrungen. Es ist unwahrscheinlich, aber nicht ausgeschlossen, dass ein kleines Start-up eine neue Methode zum Feintuning entdeckt, die die großen KI-Labore bisher nicht auf dem Schirm haben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.