Der Sprung von 2D zu 3D stellt die bisherigen Diffusion-Methoden vor Herausforderungen. RenderDiffusion scheint jedoch vielversprechend, da es anhand eines einzelnen 2D-Bilds eine 3D-Szene rendern kann.
Bei 2D-Bildern haben Diffusion-Methoden über die letzten Monate große Fortschritte erzielt. Nach und nach verzeichnen Forschende auf diesem Weg auch Erfolge für 3D-Objekte. Google etwa zeigte kürzlich 3DiM, das aus 2D-Bildern 3D-Ansichten generieren kann.
Diffusionsmodelle erreichen derzeit sowohl bei der bedingten als auch bei der unbedingten Bilderzeugung die beste Leistung, so die Forscher:innen mehrerer britischer Universitäten und Adobe Research. Bislang unterstützten diese Modelle aber keine konsistente 3D-Generierung oder die Rekonstruktion von Objekten aus einer einzigen Perspektive.

Angepasste Architektur für das 3D-Entrauschen
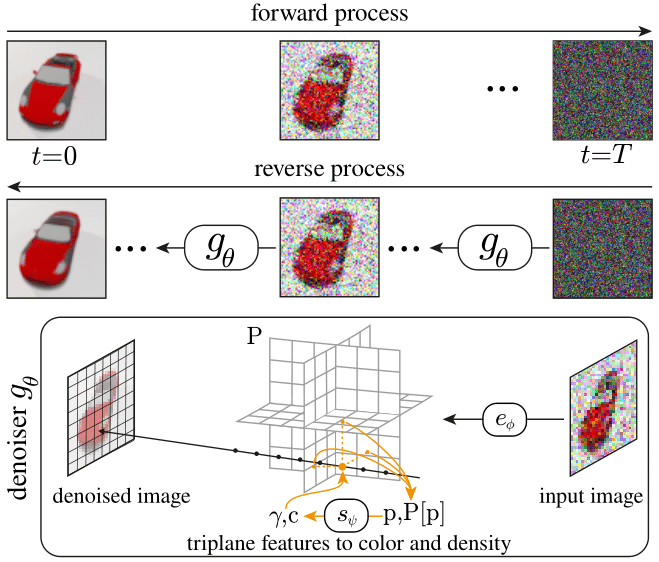
In ihrem Paper stellen die Forscher:innen RenderDiffusion vor. Dabei handele es sich um das erste Diffusionsmodell für 3D-Generierung und Inferenz, das nur mit monokularer 2D-Supervision trainiert werden könne. Das Modell kann aus einem einzigen 2D-Bild Ende-zu-Ende eine 3D-Szene generieren, ohne etwa auf Multiview-Daten wie bei Gaudi zurückzugreifen.
Herzstück der Methode sei eine angepasste Architektur zum Entrauschen (Denoising) des Ausgangsbildes. In jedem Schritt erzeuge die Methode eine dreidimensionale, volumetrische 3D-Repräsentation einer Szene.
Die resultierende 3D-Darstellung könne schließlich aus jedem Blickwinkel gerendert werden. Der diffusionsbasierte Ansatz ermögliche zudem die Verwendung von 2D-Inpainting zur Bearbeitung von 3D-Szenen.
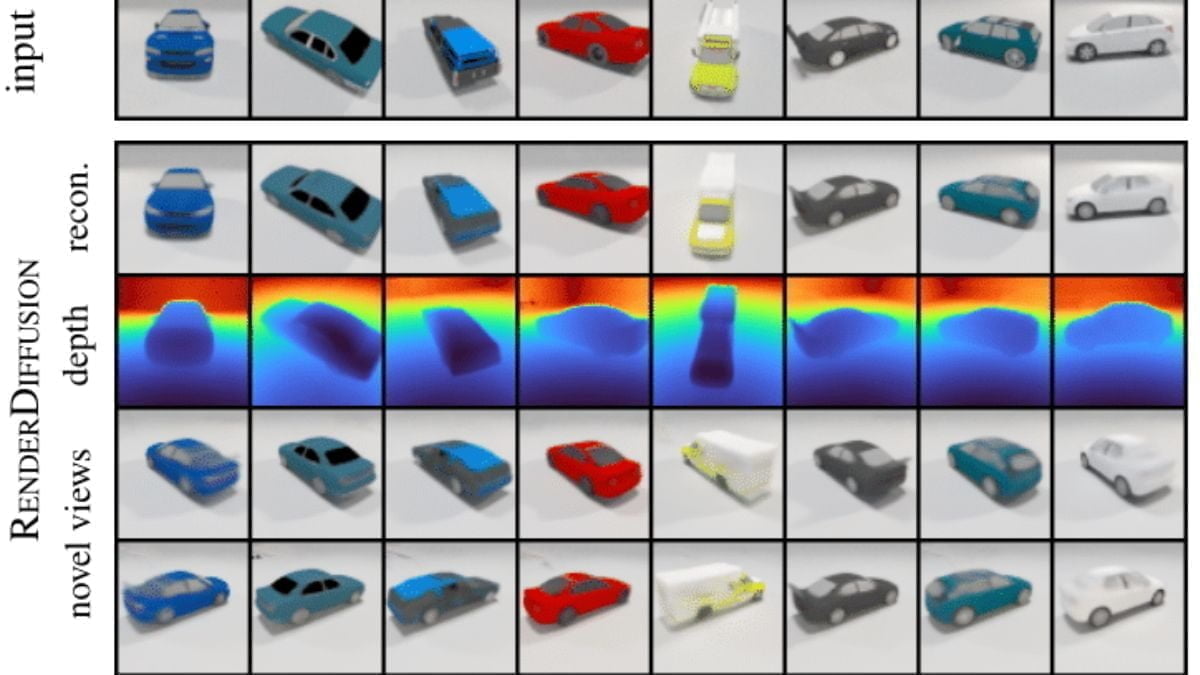
Im Vergleich zu ähnlichen generativen 3D-Modellen wie dem GAN-basierten EG3D und PixelNeRF, das allerdings den Umweg über Multiview-Ansichten von 2D-Eingabebildern geht, produziere RenderDiffusion zum Eingabebild originalgetreuere 3D-Objekte, die zudem schärfer und detaillierter seien.
Ein wesentlicher Nachteil von RenderDiffusion sei, dass Trainingsbilder mit Kameraparametern beschriftet sein müssten. Zudem sei die Generierung über verschiedene Objektkategorien schwierig.
Diese Einschränkungen könnten durch die Schätzung von Kameraparametern und Objektbegrenzungsrahmen sowie durch ein objektzentriertes Koordinatensystem aufgehoben werden. Auf diese Weise könnten auch Szenen mit mehreren Objekten darin generiert werden.

RenderDifussion soll ein Grundstein für "3D-Generierung in großem Maßstab" sein
Die Forscher:innen sind von ihrem Resultat überzeugt: "Wir glauben, dass unsere Arbeit eine vollständige 3D-Generierung in großem Maßstab ermöglicht, wenn sie auf massiven Bildsammlungen trainiert wird, wodurch die Notwendigkeit großer 3D-Modellsammlungen für die Supervision umgangen werden kann."
Zukünftige Arbeiten könnten Objekt- und Material-Editierung ermöglichen, um einen "ausdrucksstarken 3D-bewussten 2D-Bildbearbeitungs-Workflow zu ermöglichen."
Noch ist im zugehörigen GitHub-Repository kein Code zu finden, der eine Reproduktion der Ergebnisse erlauben würde. Das soll sich jedoch in naher Zukunft ändern. Das Team will auch verwendete Datensätze veröffentlichen.