
Nvidia und Stanford zeigen 3D-GANs, die noch bessere synthetische Bilder und erstmals 3D-Rekonstruktionen generieren können.
Die unter anderem für Deepfakes eingesetzten Generative Adversarial Networks erzeugen mittlerweile fotorealistische Bilder von Personen, Tieren, Gebirgszügen, Stränden oder Nahrung. Eines der stärksten Systeme stammt von Nvidia und trägt den Namen StyleGAN. Dieses System und ähnliche KI-Modelle sind jedoch auf aktueller Hardware nicht in der Lage, mit 3D-Repräsentationen zu arbeiten.
Solche 3D-Repräsentationen haben zwei Vorteile: Sie helfen, mehrere Bilder einer synthetischen Person aus unterschiedlichen Blickwinkeln zu generieren und können außerdem als Grundlage für ein 3D-Modell der Person dienen.
Denn in traditionellen 2D-GANs zeigen Bilder aus unterschiedlichen Blickwinkeln der gleichen synthetischen Person häufig Veränderungen in der Darstellung: mal ist ein Ohr anders, ein Mundwinkel verzieht sich oder die Augenpartie sieht anders aus.
Nvidias jüngste StyleGAN-Variante StyleGAN3 erreichte zwar eine höhere Stabilität, ist jedoch noch immer weit von einem natürlichen Ergebnis entfernt. Das Netzwerk speichert keine 3D-Informationen und kann die Darstellung aus mehreren Blickwinkeln daher nicht stabil halten.
Drei Ebenen statt NeRFs und Voxel
Andere Methoden wie etwa Googles Neural Radiance Fields (NeRFs) können dagegen 3D-Repräsentationen lernen und anschließend neue Blickwinkel mit hoher Stabilität in der Darstellung generieren.
NeRFs setzen dafür auf neuronale Netze, in denen sich im Training eine implizite 3D-Repräsentation des gelernten Objekts bildet. Der Gegenentwurf zur gelernten impliziten Repräsentation sind die expliziten Repräsentationen eines Voxel-Gitters.
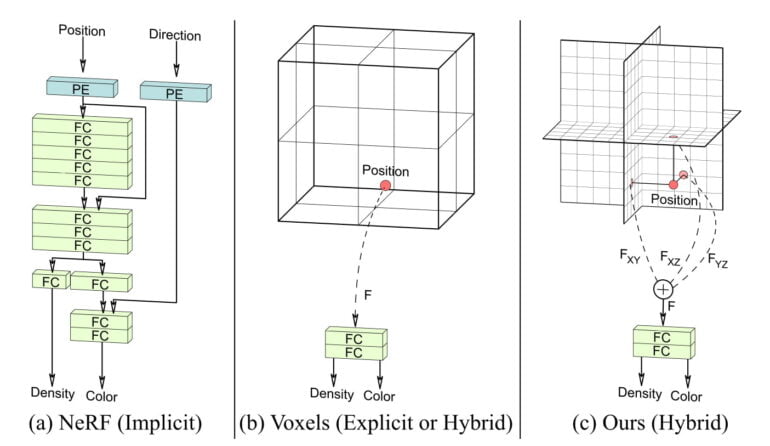
Beide Methoden haben Vor- und Nachteile: Blickwinkelanfragen an Voxel-Gitter sind schnell bearbeitet, bei NeRFs dauern diese je nach Architektur bis zu mehreren Stunden. Voxel-Gitter sind dagegen bei hohen Auflösungen sehr speicherhungrig, während NeRFs durch ihre implizite 3D-Repräsentation als eine Funktion speichereffizient sind.
Forschende der Stanford University und von Nvidia zeigen nun einen hybriden Ansatz (Efficient Geometry-aware 3D Generative Adversarial Networks, EG3D), der explizite und implizite Repräsentationen vereint, dadurch schnell ist und effizient mit der Auflösung skaliert.

Nvidias 3D-GAN EG3D braucht nur ein Bild
Das Team setzt auf eine 3D-Repräsentation in drei Ebenen statt auf ein vollständiges Voxel-Gitter. Das Drei-Ebenen-Modul ist hinter ein StyleGAN2-Generatornetz geschaltet und speichert die Ausgaben des Generators.
Ein Neural Renderer dekodiert die gespeicherten Informationen und gibt sie an ein Super-Resolution-Modul weiter. Das skaliert das 128 mal 128 Pixel kleine Bild auf 512 mal 512 Pixel. Die Bilder enthalten außerdem die in den drei Ebenen repräsentierten Tiefeninformationen.
Video: via Matthew Aaron Chan
Das Ergebnis ist ein 3D-GAN, das konsistente Bilder etwa einer Person aus verschiedenen Blickwinkeln und ein 3D-Modell generieren kann. EG3D kann zudem eine passende 3D-Rekonstruktion aus einem einzigen Bild erzeugen. Die Qualität der Ergebnisse übertrifft in den gezeigten Beispielen die anderer GANs und auch anderer Methoden wie NeRFs.
Video: via Matthew Aaron Chan
Die Forschenden weisen auf Einschränkungen bei feinen Details wie einzelne Zähne hin und planen ihre Künstliche Intelligenz dort zu verbessern. Es sei zudem möglich, einzelne Module auszutauschen und das System so etwa für die gezielte Generierung von Bildern via Text umzurüsten.
Zuletzt warnt das Team vor potenziellem Missbrauch von EG3D: Die 3D-Rekonstruktion anhand eines einzigen Bildes könne potenziell für Deepfakes genutzt werden. Weitere Informationen und Beispiele gibt es auf der Projektseite von EG3D.




