Saba ist Mistrals erstes KI-Sprachmodell für sprachliche und kulturelle Nuancen
Das französische KI-Start-up Mistral AI hat mit Mistral Saba ein neues KI-Sprachmodell vorgestellt, das speziell auf die Bedürfnisse des Nahen Ostens und Südostasiens zugeschnitten ist.
Während größere, universelle Modelle oft Schwierigkeiten haben, die Feinheiten verschiedener Kulturen und Sprachen adäquat abzubilden, setzt Mistral Saba auf einen fokussierten Ansatz. Das Modell wurde entwickelt, um die sprachlichen Nuancen, den kulturellen Hintergrund und das regionale Wissen dieser Gebiete zu erfassen und so präzisere und relevantere Ergebnisse zu liefern als allgemeine Sprachmodelle.
Mit 24 Milliarden Parametern ist es deutlich kleiner als viele andere Modelle, bietet aber laut Mistral AI dennoch eine höhere Genauigkeit und Geschwindigkeit bei gleichzeitig geringeren Kosten. Damit dürfte es eine ähnliche Architektur wie das kürzlich veröffentlichte Mistral-Modell Small 3 vorweisen.
Klein und effizient
Diese Effizienz ermöglicht auch den Einsatz auf weniger leistungsstarker Hardware, sogar auf Systemen mit nur einer GPU, wobei Geschwindigkeiten von mehr als 150 Token pro Sekunde erreicht werden könnten. Darüber hinaus könnte Mistral Saba als Grundlage für die Entwicklung noch spezifischerer regionaler Anpassungen dienen.
Die Sprachunterstützung von Mistral Saba umfasst Arabisch und viele Sprachen indischen Ursprungs, mit besonderer Stärke in südindischen Sprachen wie Tamil und Malayalam. Diese breite Abdeckung trage zur Vielseitigkeit des Modells in den multinationalen und eng vernetzten Regionen des Nahen Ostens und Südostasiens bei, heißt es.
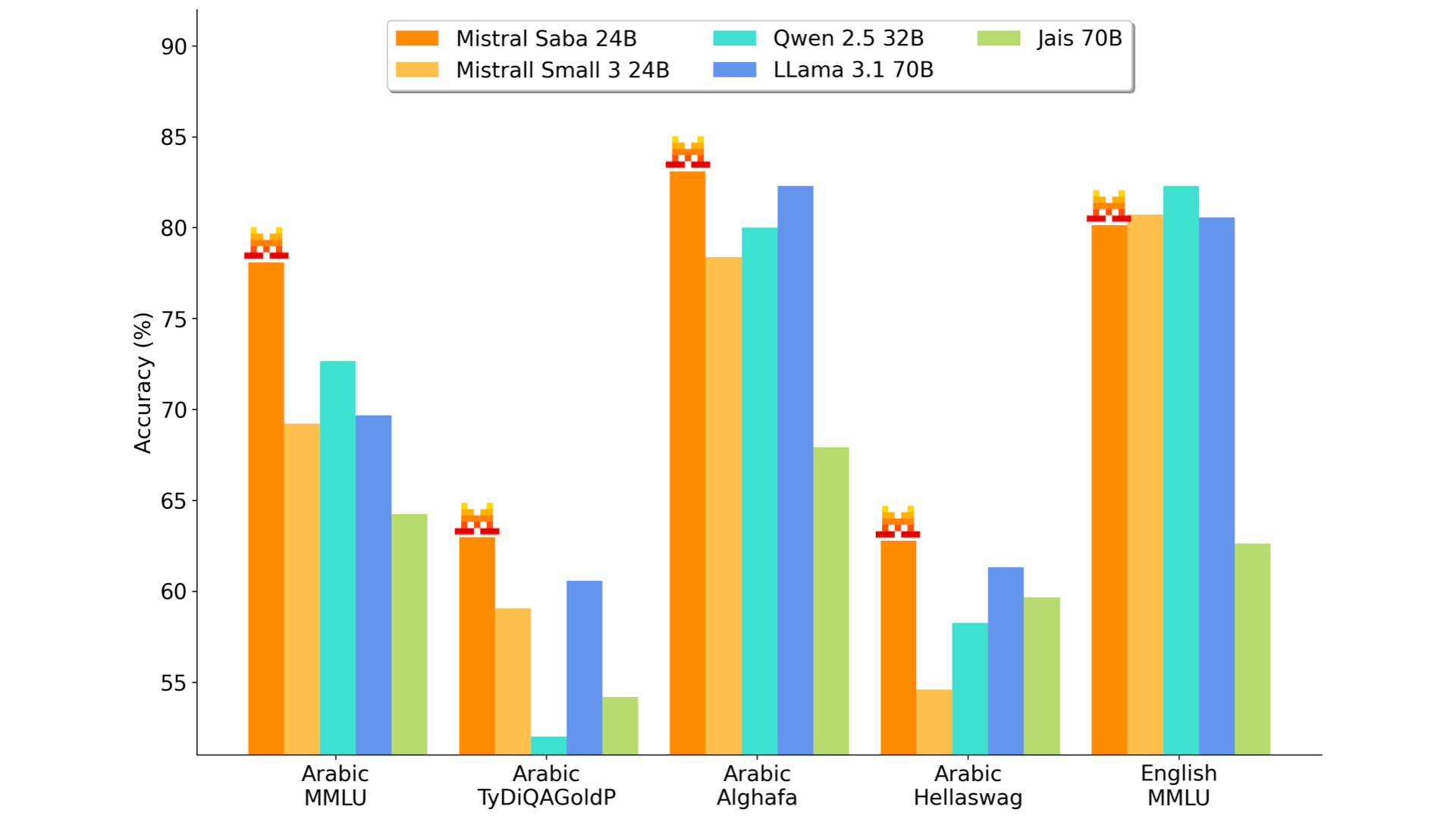
Mistral Saba findet laut dem Unternehmen bereits Anwendung in verschiedenen Bereichen. So werde es beispielsweise zur Entwicklung virtueller Assistenten eingesetzt, die in der Lage sind, natürliche Unterhaltungen auf Arabisch zu führen.
Durch Finetuning könne Mistral Saba außerdem zu einem Spezialisten in bestimmten Fachgebieten wie Energie, Finanzmärkten oder Gesundheitswesen werden und so fundierte Einblicke im jeweiligen kulturellen und sprachlichen Kontext liefern.
Ein weiterer Anwendungsbereich ist die Erstellung von kulturell relevantem Content, wobei das Modell sein Verständnis lokaler Redewendungen und kultureller Referenzen nutzt, um authentisch klingende Inhalte zu generieren.
Keine Open-Source-Veröffentlichung
Das Modell kann sowohl über eine kostenpflichtige API als auch von Mistral lokal in der Infrastruktur des Kunden bereitgestellt werden. Wie viele andere Modelle von Mistral ist es jedoch nicht Open Source.
Dementsprechend ist auch unklar, wie genau Mistral bei der Entwicklung vorgegangen ist. Es ist davon auszugehen, dass zunächst ein für die gewünschten Sprachen optimierter Datensatz zusammengestellt wurde.
Große Sprachmodelle lernen Sprachen durch das Verarbeiten massiver Textdatensätze und bilden dabei statistische Beziehungen zwischen Wörtern und Sätzen. Sie entwickeln sozusagen ein universelles Sprachverständnis, das ihnen ermöglicht, verschiedene Sprachen zu generieren und zu verarbeiten. Der Löwenanteil (93 Prozent) des Trainingsdatensatzes von GPT-3 - für neuere OpenAI-Modelle sind keine Details bekannt - ist auf Englisch.
Dieses breite Verständnis ist jedoch oft oberflächlich. Die Modelle erfassen zwar die allgemeine Grammatik und Semantik, verfehlen aber oft die feinen Nuancen, die ein Muttersprachler benötigt. Ein Modell wie Saba soll genau diese Lücke schließen.
Einen ähnlichen Ansatz verfolgt das Forschungsprojekt OpenGPT-X, das mit Teuken-7B im November ein Sprachmodell veröffentlichte, das zu etwa 50 Prozent auf nicht-englischen Daten trainiert wurde. Auch OpenAI hat beispielsweise bereits ein spezifisches GPT-4-Modell für Japanisch veröffentlicht, das Projekt EuroLingua für den europäischen Sprachraum, der deutsche Verein Laion mit LeoLM für die deutsche Sprache.
Diese Optimierungen bedeuten jedoch nicht notwendigerweise, dass ein KI-Modell, das auf eine Zielsprache fein abgestimmt ist, diese Sprache besser beherrscht als ein Modell, das nicht fein abgestimmt ist. Die Fähigkeiten des Basismodells sind entscheidender als die Feinabstimmung auf eine Sprache.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.