Sprachmodelle können große Dokumente laut neuem Benchmark nicht zuverlässig verarbeiten

Die Anbieter großer Sprachmodelle werben damit, dass ihre Modelle zum Teil riesige Datenmengen verarbeiten können. Wie gut oder schlecht sie das tun, sagen sie nicht. Forschende stellen nun einen neuen Benchmark vor.
Große Sprachmodelle (LLMs) wie GPT-4 oder Claude 3 können theoretisch Texte mit Hunderttausenden von Wörtern verarbeiten. Das klingt beeindruckend, sagt aber wenig darüber aus, wie gut die Modelle die Inhalte tatsächlich verstehen und nutzen können.
Der "Needle In A Haystack (NIAH)" Test misst die Fähigkeit eines Modells, einzelne Informationen aus langen Texten präzise zu extrahieren. Führende Modelle wie Claude 3 Opus erreichen eine Genauigkeit von über 99 Prozent. Auch Google und OpenAI verwenden den NIAH-Test als Benchmark für die Leistungsfähigkeit ihres eigenen Kontextfensters.
Dieser Test sagt jedoch nichts darüber aus, ob LLMs auch Zusammenhänge verstehen und große Texte sinnvoll zusammenfassen oder analysieren können. In der Praxis gibt es je nach Anwendungsfall oft effizientere Suchfunktionen in großen Textdaten als LLMs - etwa die einfache Stichwortsuche mit "Strg + F".
LLM-Schlussfolgerungen auf großen Datenmengen sind noch lange nicht ausgereift
Forschende des Shanghai AI Laboratory und der Tsinghua University stellen nun mit NeedleBench einen neuen zweisprachigen (Englisch und Chinesisch) Benchmark vor, der die Kontext-Fähigkeiten von LLMs umfassender überprüft.
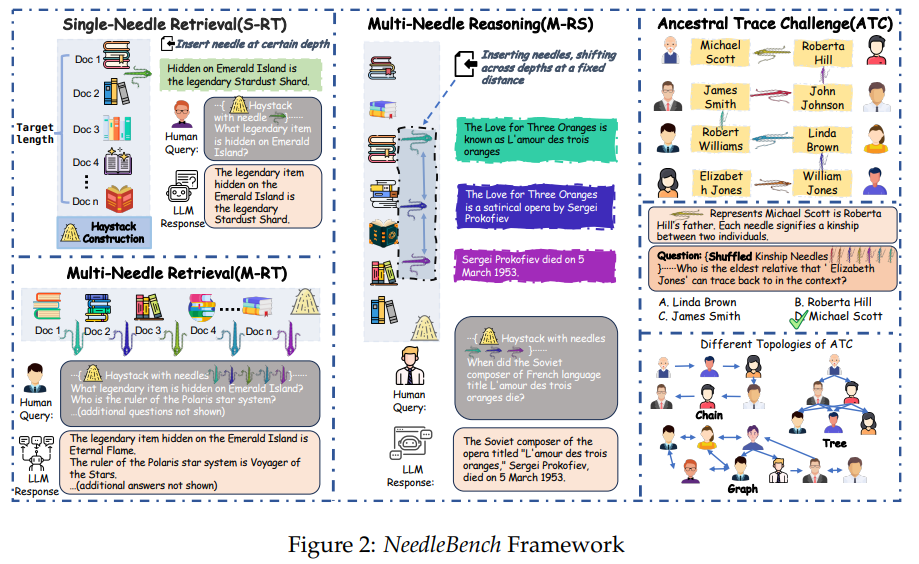
Er umfasst verschiedene Aufgaben, die die Fähigkeiten von LLMs zur Informationsextraktion und zum logischen Schlussfolgern in langen Texten auf die Probe stellen. NeedleBench deckt mehrere Längenintervalle ab (4k, 8k, 32k, 128k, 200k, 1000k und darüber hinaus) und verschiedene Texttiefenbereiche.
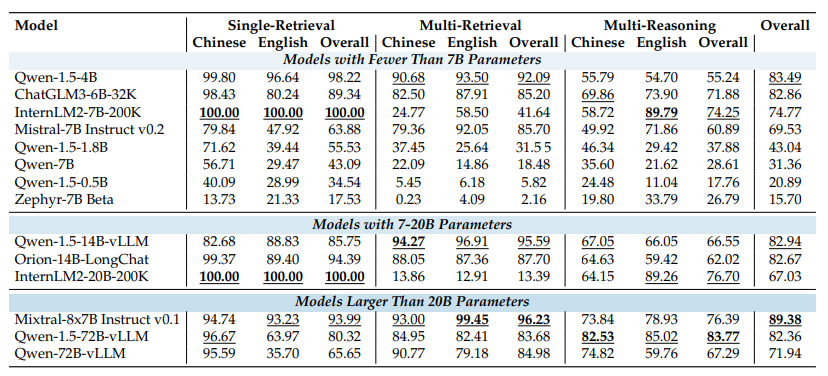
Besonders interessant ist dabei der "Multi-Needle Reasoning Task (M-RS)". Er beschreibt, was man von Sprachmodellen eigentlich erwartet: sinnvolle Schlüsse aus verstreuten Informationen in großen Dokumenten unter Berücksichtigung aller Daten zu ziehen, um komplexe Fragen zu beantworten. Diesen M-RS-Aufgaben führten die Forschenden mit verschiedenen Open-Source-Modellen durch (Ergebnisse siehe Grafik unten).
Um auch die kontextabhängige Leistung großer API-Modelle zu testen, haben die Forscher die Ancestral Trace Challenge (ATC) entwickelt, bei der das Modell in der Lage sein muss, die Verwandtschaftsbeziehungen von Personen anhand verschiedener Textdaten korrekt zu beschreiben. Ziel ist es, die Fähigkeit von LLMs zu testen, mehrstufige logische Herausforderungen zu bewältigen, wie sie in realen Szenarien mit langen Kontexten auftreten können.
Die API-Modelle von OpenAI und Anthropic schnitten in der Ancestral Trace Challenge am besten ab. Aber auch ihre Leistung nahm mit zunehmender Datenmenge und Komplexität der Aufgabe rapide ab. Unter den Open-Source-Modellen schnitt das große Sprachmodell DeepSeek-67B am besten ab.
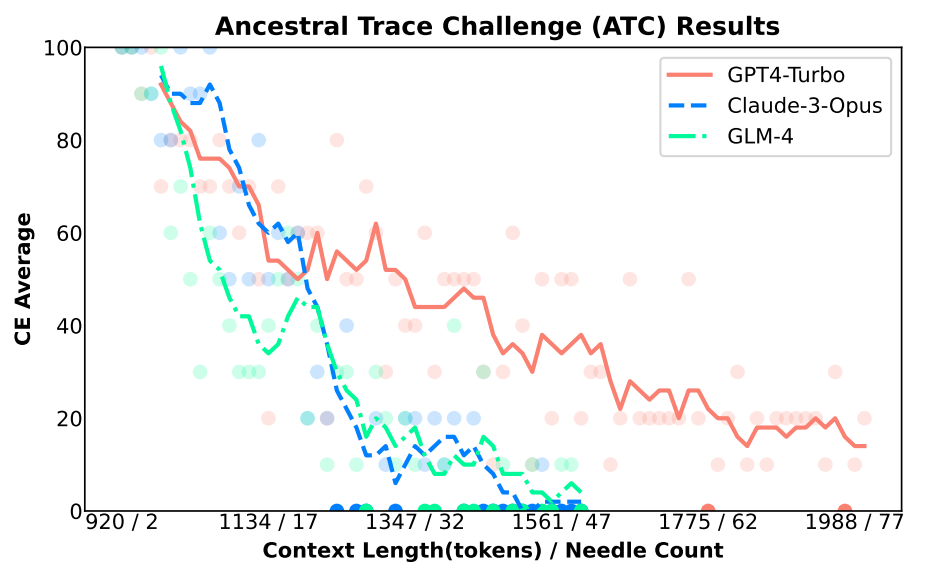
Die Ancestral Trace Challenge zeigt eine Diskrepanz zwischen den Werbeaussagen der LLM-Anbieter und den tatsächlichen Fähigkeiten ihrer Modelle. Während Firmen wie Google damit werben, weit über eine Million Token verarbeiten zu können, zeigt NeedleBench, dass die Modelle bereits bei wenigen tausend Token an ihre Grenzen stoßen, wenn es darum geht, komplexe Informationen aus langen Texten zu extrahieren und logisch zu verknüpfen.
"Unsere Ergebnisse deuten darauf hin, dass aktuelle LLMs für praktische Anwendungen mit langen Kontexten noch erheblich verbessert werden müssen", fassen die Forscher zusammen. Skripte, Code und Datensätze stellen sie auf Github zur Verfügung.
Interessante Teilergebnisse der Studie sind, dass viele Open-Source-Modelle grundsätzlich etwas besser abschneiden, wenn zuerst der Quellinhalt und dann der Prompt folgt, dass Chain-of-Thought-Prompting die Ergebnisse verbessert und die Aufgaben generell von größeren Modellen besser gelöst werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.