
Ein einziges Bild genügt dem neuesten Modell von Stability AI, um nahezu perfekte Ansichten eines Objekts aus verschiedenen Blickwinkeln zu generieren.
Stability AI hat mit Stable Video 3D (SV3D) ein neues generatives Modell vorgestellt, das auf Stable Video Diffusion basiert. Wie aus einem Blogeintrag des Unternehmens hervorgeht, soll SV3D die Qualität, Konsistenz und Kontrollierbarkeit bei der Generierung von 3D-Inhalten aus Einzelbildern deutlich verbessern.
SV3D gibt es in zwei Varianten: SV3D_u erzeugt Orbitalvideos auf Basis von Einzelbildeingaben ohne spezifizierte Kamerasteuerung. Die erweiterte Variante SV3D_p unterstützt sowohl Einzelbilder als auch 3D-Objekte als Eingabe und ermöglicht so die Erzeugung von Videos entlang vorgegebener Kamerapfade. Die Auflösung der resultierenden Videos ist mit 576 x 576 Pixeln bei 21 Bildern pro Sekunde allerdings noch vergleichsweise gering.
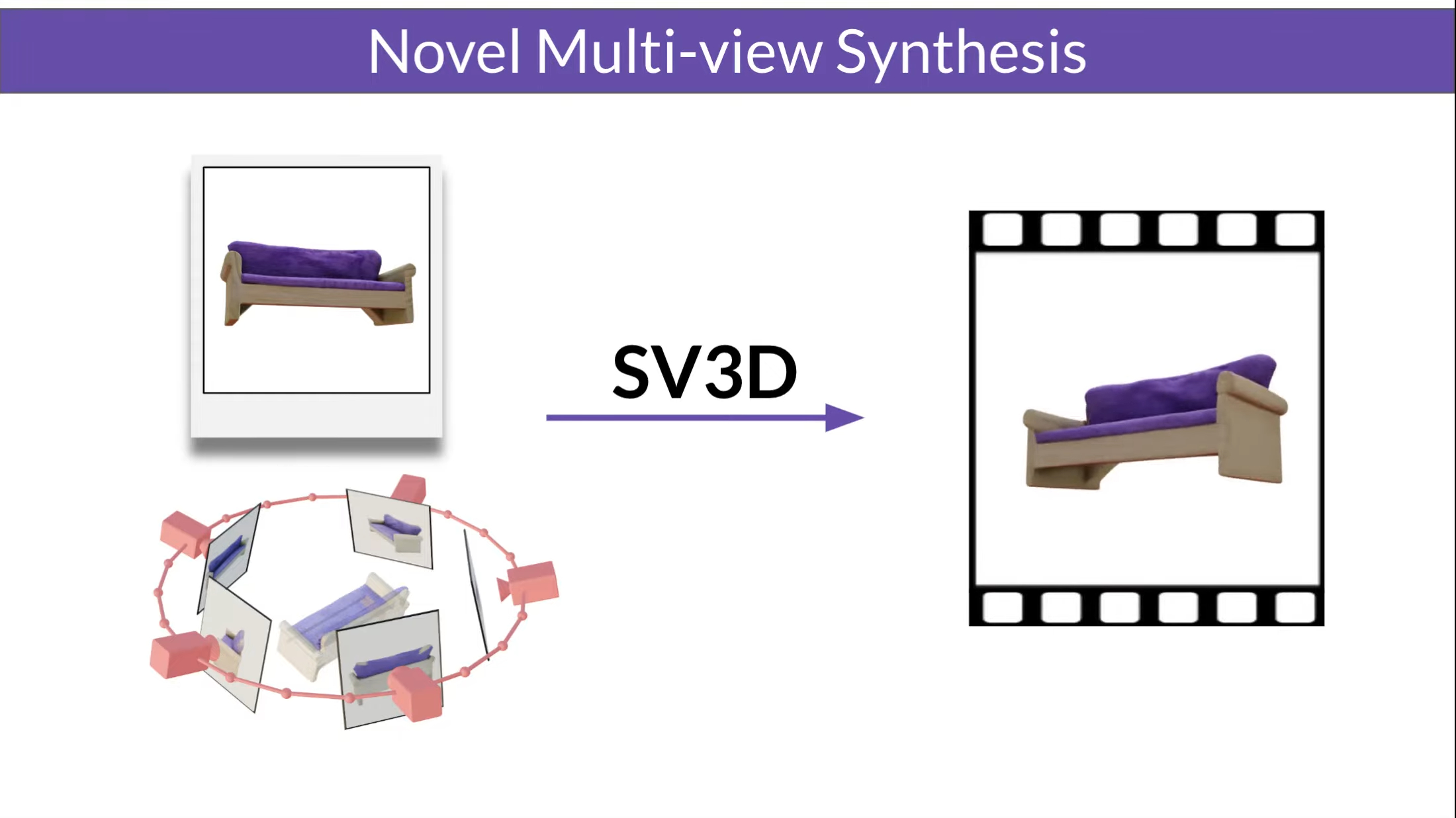
Der Einsatz von Videodiffusionsmodellen im Gegensatz zu Bilddiffusionsmodellen, wie sie etwa bei Stability AIs erst im Dezember veröffentlichten Zero123 zum Einsatz kommen, bietet nach Angaben des Unternehmens große Vorteile bei der Generalisierung und Ansichtskonsistenz der generierten Ausgaben.
Diese Eigenschaft zeigt sich eindrucksvoll im folgenden Beispiel, in dem SV3D im Vergleich zu bisherigen Methoden detaillierte 3D-Ansichten aus einem einzigen Foto erzeugt.

Die Verarbeitungspipeline von SV3D ist komplex und beinhaltet unter anderem die Erstellung sogenannter Neural Radiance Fields (NeRF), die in den letzten Jahren schon für große Fortschritte bei 3D-Objektgenerierung gesorgt haben. Hinzu kommt ein Beleuchtungsmodell, das den korrekten Lichteinwurf je nach Betrachtungswinkel sicherstellen soll.
SV3D kann ab sofort für kommerzielle Zwecke über die kürzlich eingeführte Stability-AI-Mitgliedschaft genutzt werden. Für die nicht-kommerzielle Nutzung stehen die Modellgewichte auf Hugging Face zum Download bereit.
Tatsächlich scheint SV3D einen Meilenstein für konsistente 3D-Ansichten aus Einzelbildern darzustellen, von dem vor allem Medienschaffende im Bereich der Animation, Game Design und VR profitieren könnten.
Das Londoner KI-Start-up hat in den letzten Monaten einige visuelle Modelle auf hohem Niveau vorgestellt, darunter Stable Diffusion 3 für Text-zu-Bild, Stable 3D für Text-zu-3D und Stable Video Diffusion für Text-zu-Video.

Die Entwicklungen, die häufig Open-Source veröffentlicht werden, kosten allerdings auch viel Ged. Zuletzt hatte Intel die Arbeiten maßgeblich finanziert, weiteres Einkommen stammt aus der Veräußerung der KI-Bildplattform Clipdrop.



