Stable Video 4D generiert bewegliche 3D-Modelle aus Videos

Stability AI hat Stable Video 4D vorgestellt, ein neuartiges Diffusionsmodell, das aus einem einzelnen Video dynamische 3D-Inhalte erstellt. Dazu kombiniert es zwei ältere Durchbrüche.
Stable Video 4D knüpft an den Erkenntnissen des im März veröffentlichten Stable Video 3D von Stability AI an, das zunächst Objekte aus Bildern in neuen Perspektiven generiert und daraus statische 3D-Objekte abstrahiert. Stable Video 4D hebt diese Technologie jedoch auf die nächste Stufe, indem es sich bewegende 3D-Videoinhalte (auch 4D genannt) aus einer einzigen, flachen Videoeingabe generiert.
Video: Stability AI
40 Sekunden für 8 Ansichten
Die Anwendung soll möglichst wenig Hürden bieten: Nutzer:innen können ein Video eingeben, die gewünschten 3D-Kamerapositionen festlegen und Stable Video 4D produziert in wenigen Momenten acht neuartige Videos, die den angegebenen Kameraansichten folgen und eine umfassende Perspektive des Subjekts aus mehreren Blickwinkeln bieten.
Laut Stability AI benötigt Stable Video 4D für Videos mit jeweils 5 Frames über 8 Ansichten mit einer Auflösung von 576 x 576 Pixeln etwa 40 Sekunden, wobei der 4D-Optimierungsprozess etwa weitere 20 bis 25 Minuten dauert. Das ist zwar immer noch ein hoher Zeitbedarf, aber schon deutlich kürzer als bei früheren Methoden, die Stunden in Anspruch nahmen.
Video: Stability AI
Kombination von Stable Video Diffusion und Stable Video 3D
Eine der Haupterrungenschaften von Stable Video 4D ist die Fähigkeit, mehrere neuartige Videos gleichzeitig zu generieren und dabei ein konsistentes Objekterscheinungsbild über mehrere Ansichten und Zeitstempel hinweg zu gewährleisten.
Das gelingt, indem die Forschenden ein Video- sowie ein Multi-View-Diffusionsmodell miteinander kombinieren, in diesem Fall Stable Video Diffusion und Stable Video 3D. Die Wissenschaftler:innen sagen, dass dieser Ansatz mit jedem Attention-basierten Diffusionsmodell funktionieren sollte.
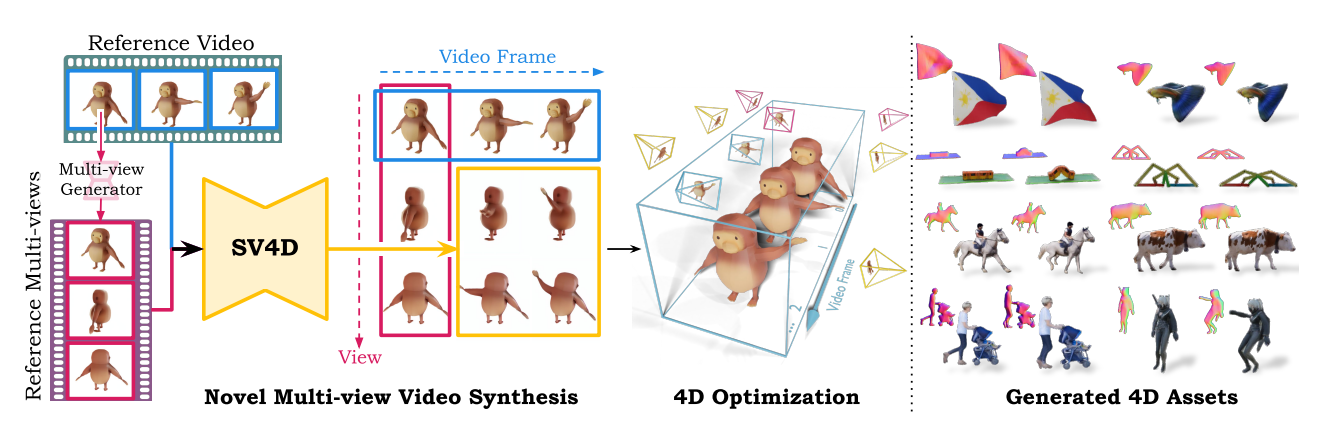
Ein leistungsstarkes 4D-Modell zu entwickeln, scheiterte bislang in den Augen der Forschenden auch an dem Mangel eines umfangreichen Trainingsdatensatzes. Diese Erkenntnis führte sie zu der Zusammenstellung von ObjaverseDy, den sie vom bestehenden Objaverse-Datensatz abgeleitet und auf passende Inhalte gefiltert haben. Die SV4D-Modellgewichte wurden mit den vortrainierten SVD- und SV3D-Gewichten initialisiert und nutzten so die erlernten Vorkenntnisse aus großen Video- und 3D-Datensätzen.
In Benchmarks mit mehreren Datensätzen übertraf SV4D bestehende Methoden sowohl bei der Synthese neuartiger Ansichtsvideos als auch bei der 4D-Optimierung. Die generierten Ergebnisse zeigten im Vergleich zum bisherigen Stand der Technik eine überlegene visuelle Qualität, Gleichmäßigkeit und Konsistenz über verschiedene Perspektiven hinweg. Unterschiede zwischen den Methoden fallen im folgenden Beispiel etwa vor allem am Rucksack des Wanderers oder am Fahrradfahrer auf.
Video: Stability AI
Potenzial für Spiele, Videos und VR
Das Unternehmen arbeitet daran, das Modell so zu verfeinern, dass es neben den synthetischen Datensätzen, mit denen es derzeit trainiert wird, eine größere Bandbreite an realen Videos verarbeiten kann. Anwendungsbereiche für Stable Video 4D sieht das Unternehmen vor allem in der Spieleentwicklung, der Videobearbeitung und der virtuellen Realität.
Stable Video 4D ist ab sofort auf Hugging Face verfügbar und stellt angesichts des leichten Qualitätsvorsprungs gegenüber alternativen Methoden wohl den neuen Stand der Technik in diesem Bereich dar. Dennoch sind Handhabung und Auflösung noch weit entfernt vom alltäglichen Einsatz bei Spielefirmen oder Filmproduktionen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.