
Forscher der UC Berkeley stellen Starling-7B vor, ein offenes Large Language Model (LLM), das mit Reinforcement Learning from AI Feedback (RLAIF) trainiert wurde.
Reinforcement Learning from AI Feedback (RLAIF) nutzt das Feedback von KI-Modellen, um andere KI-Modelle zu trainieren und deren Leistung zu verbessern. Im Fall von Starling-7B soll RLAIF die Nützlichkeit und Sicherheit von Chatbot-Antworten erhöhen. Das Modell basiert auf einem verfeinerten Openchat 3.5, der wiederum Mistral-7B als Basis verwendet.
Das Trainingsparadigma ist unter anderem von ChatGPT bekannt, allerdings mit einem entscheidenden Unterschied: Hier verbessern Menschen den Output des KI-Modells (RLHF). Im Vergleich dazu ist das KI-Feedback billiger, schneller, wahrscheinlich transparenter und besser skalierbar - wenn es funktioniert.
Um das Modell mit RLAIF zu trainieren, erstellten die Forscher den neuen Datensatz Nectar, der aus 183.000 Chat-Prompts mit jeweils sieben Antworten besteht - insgesamt 3,8 Millionen paarweise Vergleiche. Die Antworten stammen von verschiedenen Modellen wie GPT-4, GPT-3.5-instruct, GPT-3.5-turbo, Mistral-7B-instruct und Llama2-7B.
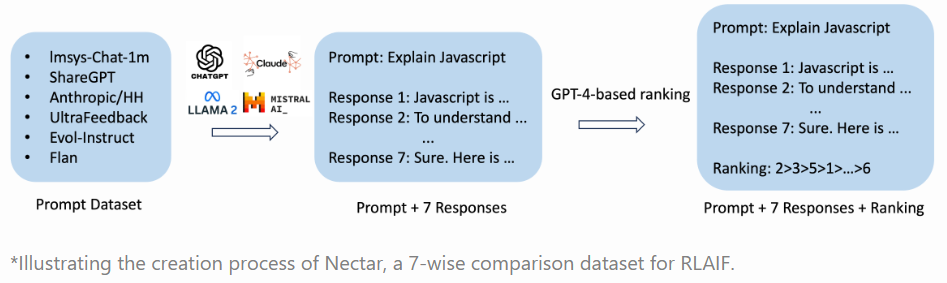
Die Qualität der synthetischen Antworten wurde von GPT-4 bewertet, wobei die Forscherinnen und Forscher einen speziellen Ansatz entwickelten, um die Vorliebe von GPT-4, die ersten und zweiten Antworten besonders positiv zu bewerten, zu umgehen.
Starling-7B erzielt starke Benchmark-Ergebnisse
Die Forscher verwendeten zwei Benchmarks, MT-Bench und AlpacaEval, die GPT-4 für die Bewertung verwenden, um die Leistung ihres Modells zu beurteilen.
Starling-7B übertrifft die meisten Modelle in MTBench mit Ausnahme von OpenAIs GPT-4 und GPT-4 Turbo und erreicht in AlpacaEval Ergebnisse auf dem Niveau kommerzieller Chatbots wie Claude 2 oder GPT-3.5.
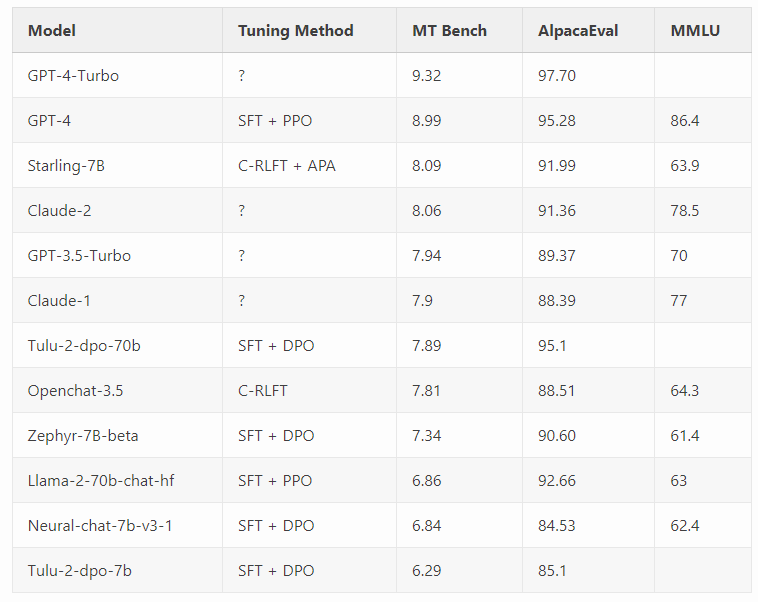
Die Forschenden schreiben, dass RLAIF in erster Linie die Hilfsbereitschaft und die Sicherheit des Modells verbessere, nicht aber seine grundlegenden Fähigkeiten wie wissensbasierte Fragen, Mathematik oder Codierung. Diese seien statisch oder würden durch RLAIF sogar minimal verschlechtert.
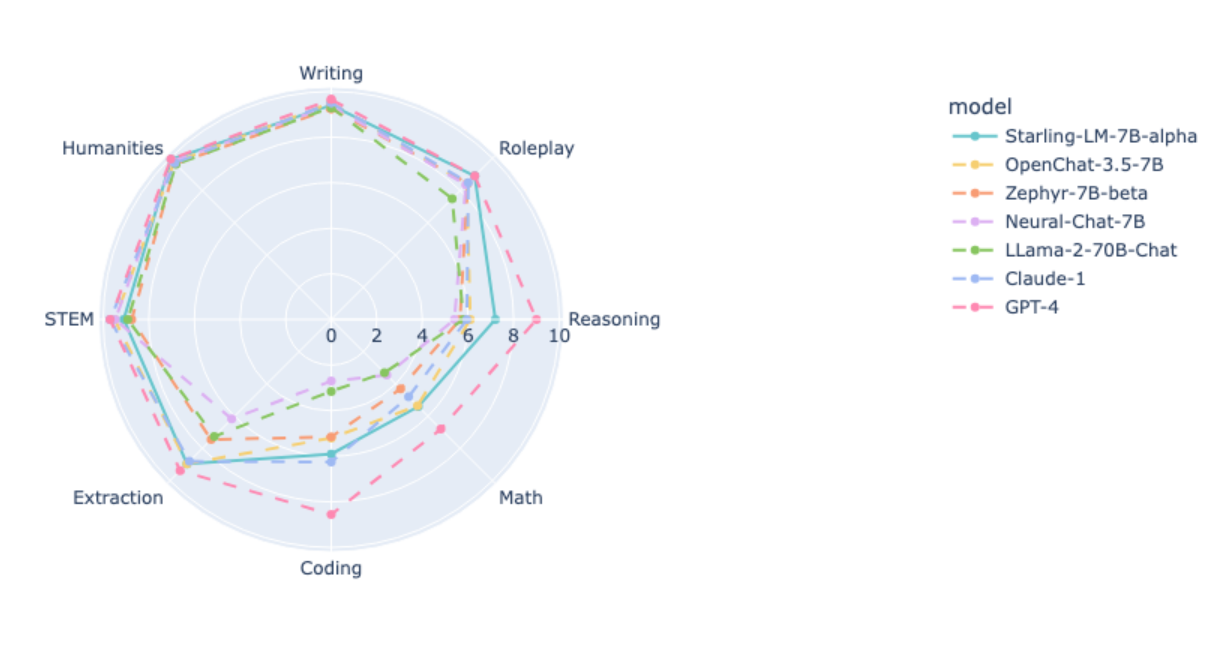
Wie üblich sind die Benchmark-Ergebnisse nur begrenzt aussagekräftig. Sie sind jedoch vielversprechend für die Anwendung von RLAIF, auch wenn die Forscher einschränken, dass menschliche Beurteiler andere Präferenzen haben könnten als GPT-4, das in den oben genannten Benchmarks urteilte.

Wie andere kleine und große LLMs hat Starling-7B Schwierigkeiten mit Aufgaben, die logisches Denken oder Mathematik erfordern, und halluziniert. Außerdem ist es anfällig für Jailbreaks, da es nicht explizit für diese Szenarien trainiert wurde.
Ein nächster Schritt könnte daher sein, den Nectar-Datensatz mit qualitativ hochwertigen menschlichen Feedback-Daten zu erweitern, um das Modell noch besser an die Bedürfnisse des Menschen anzupassen.
Die Forscher veröffentlichen den Nectar-Datensatz, das damit trainierte Belohnungsmodell Starling-RM-7B-alpha und das Sprachmodell Starling-LM-7B-alpha auf HuggingFace unter einer Forschungslizenz. Code und Paper folgen in Kürze. Wer den LLM im Chatmodus testen möchte, kann dies in der Chatbot-Arena tun.




