Studie bestätigt OpenAIs Dominanz bei KI-Assistenz dank GPT-4

Es gibt zahlreiche kommerzielle Angebote und Open-Source-Modelle für generative Text-KIs. Ein speziell für Assistenzaufgaben entwickelter Benchmark zeigt nun, dass GPT-4 in diesem Segment herausragt.
"AgentBench" ist ein standardisierter Test, der speziell für die Assistenzfunktion großer Sprachmodelle in "realistischen pragmatischen Missionen" entwickelt wurde. Alle Tests finden in interaktiven Echtzeitumgebungen statt. Dadurch soll der Benchmark für das, was er messen soll, besonders geeignet sein: Wie gut ein großes Sprachmodell eine Vielzahl von Alltagsaufgaben in den insgesamt acht folgenden Bereichen bewältigen kann.
- Betriebssystem: Hier müssen die LLMs Aufgaben erledigen, die mit der Benutzung eines Computer-Betriebssystems zusammenhängen.
- Datenbank: In dieser Umgebung geht es darum, wie gut LLMs mit Datenbanken umgehen können.
- Wissensgraph: In dieser Umgebung wird geprüft, wie gut LLMs mit Wissensgraphen arbeiten können. Wissensgraphen sind wie ein Netzwerk, das verschiedene Dinge miteinander verbindet und Wissen in einer für Menschen lesbaren Weise darstellt.
- Digitales Kartenspiel: Hier wird getestet, wie gut LLMs digitale Kartenspiele verstehen und Strategien entwickeln können.
- Querdenker-Rätsel: Diese Herausforderung testet, wie kreativ LLMs bei der Lösung von Problemen sein können. Hier müssen sie originell denken.
- Budgets: In diesem Szenario geht es um Aufgaben, die in einem Haushalt anfallen, basierend auf dem Alfworld-Datensatz.
- Internet-Shopping: Dieses Szenario testet, wie gut LLMs bei Aufgaben im Zusammenhang mit Online-Einkäufen abschneiden.
- Web-Browsing: Auf der Grundlage des Mind2Web-Datensatzes wird überprüft, wie gut LLMs Aufgaben erledigen können, die mit der Nutzung des Internets zusammenhängen.
Video: AgentBench
GPT-4 mit großem Abstand das fähigste KI-Modell
Insgesamt testete das Forscherteam der Tsinghua University, der Ohio State University und der UC Berkeley 25 große Sprachmodelle verschiedener Hersteller sowie Open-Source-Modelle.
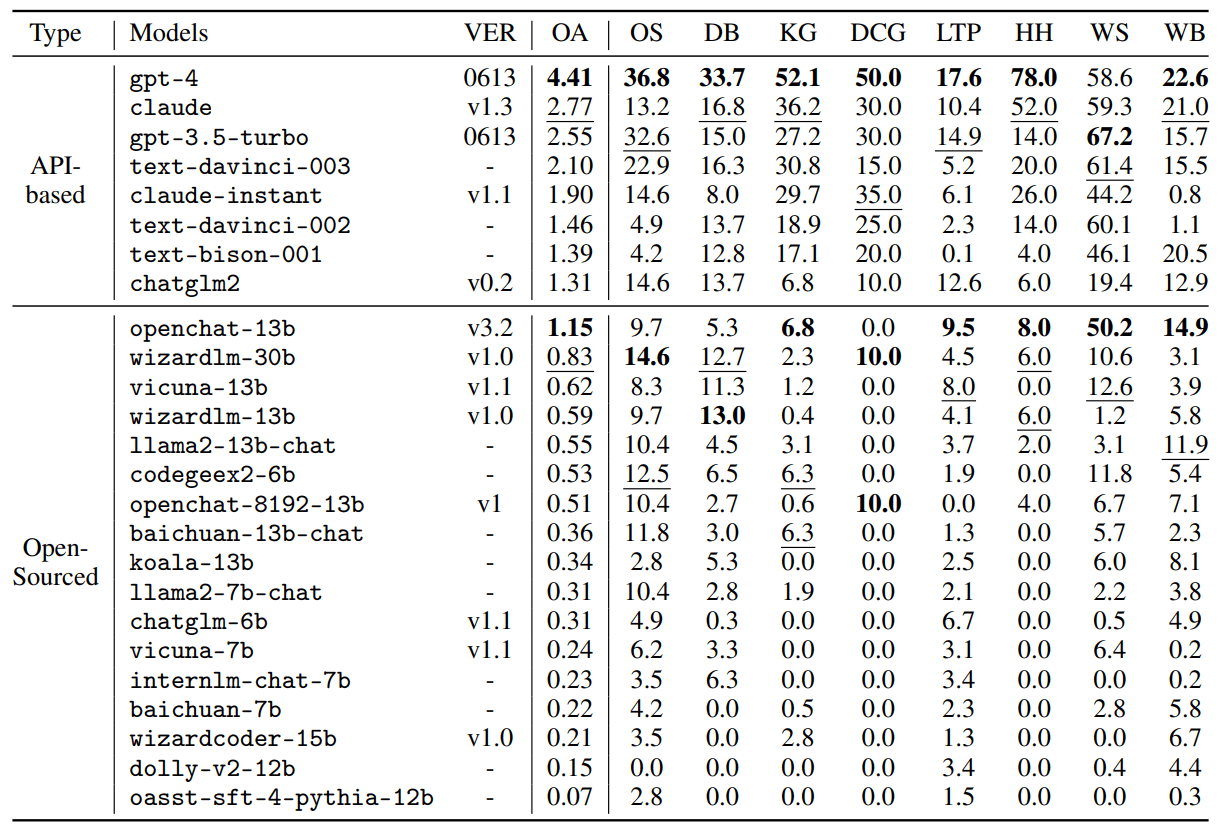
Das Ergebnis: OpenAIs GPT-4 erzielte die höchste Gesamtpunktzahl von 4,41 und lag in fast allen Disziplinen vorn. Lediglich bei der Aufgabe Web-Shopping schnitt GPT-3.5 am besten ab.
Das Modell Claude des Mitbewerbers Anthropic folgt mit einer Gesamtpunktzahl von 2,77 knapp vor dem freien Modell GPT-3.5 Turbo von OpenAI. Der Durchschnitt der kommerziellen Modelle liegt bei 2,24 Punkten.
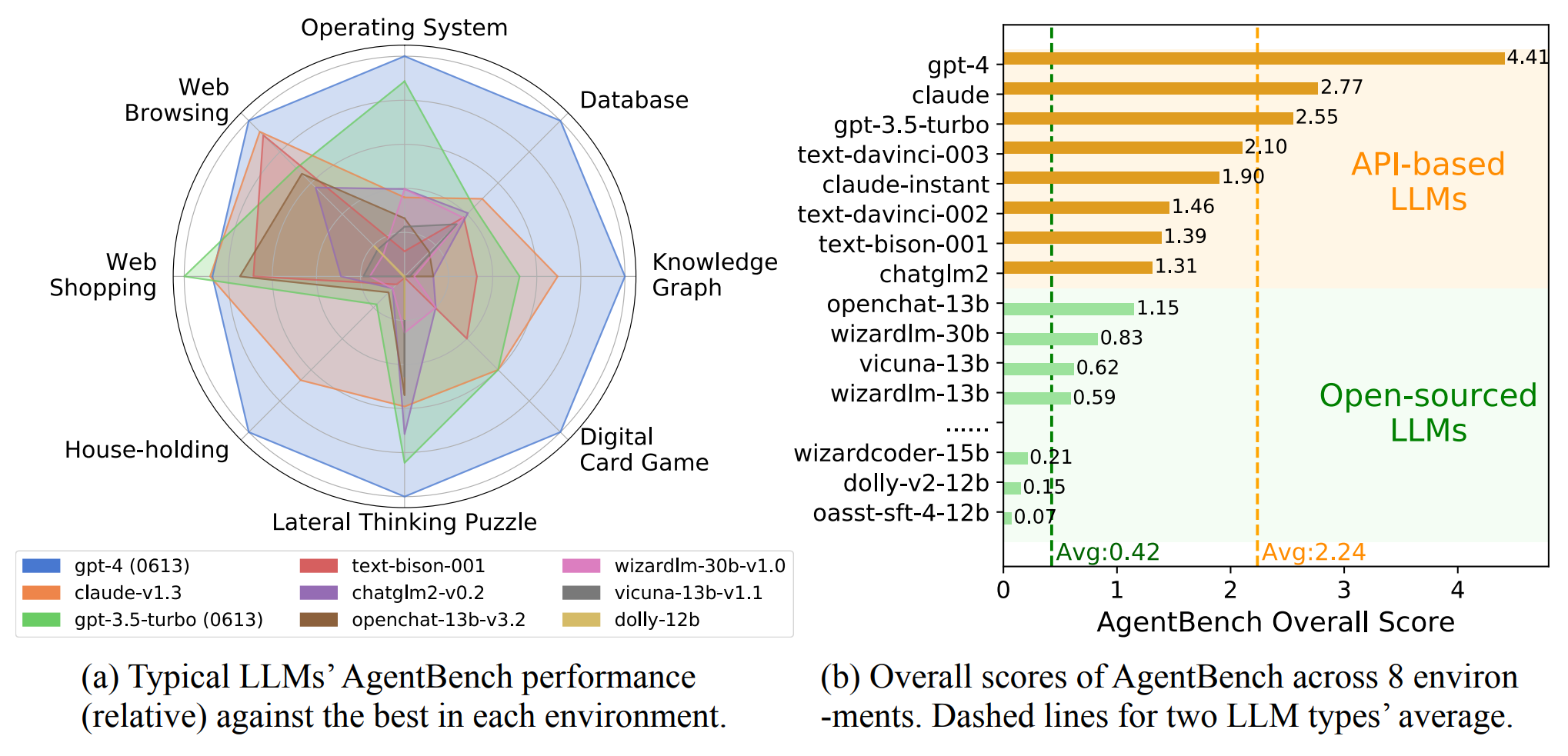
Noch deutlicher ist der Abstand von GPT-4 und generell der kommerziellen Modelle zu den Open-Source-Modellen: Hier beträgt die durchschnittliche Leistung nur 0,42 Punkte. Die Open-Source-Modelle versagen in der Regel bei allen komplexen Aufgaben und liegen weit hinter GPT-3.5. Am besten schneidet OpenChat auf Basis von Llama-13B mit 1,15 Punkten ab.
Wir stellen fest, dass Spitzen-LLMs immer besser in der Lage sind, komplexe reale Aufgaben zu bewältigen. Ihre Open-Source-Konkurrenten haben im Vergleich noch einen weiten Weg vor sich.
Aus dem Paper
In der vorläufigen Ergebnisliste fehlen zahlreiche kommerzielle Modelle wie PaLM 2 von Google, Claude 2 oder die Modelle von Aleph Alpha sowie weitere Open-Source-Modelle.
Das Forschungsteam stellt der Forschungsgemeinschaft daher ein Toolkit, die Datensätze und die Benchmark-Umgebung für zukünftige Leistungsvergleiche bei Github zur Verfügung. Weitere Informationen und eine Demo gibt es auf der Projektwebseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.