Studie: "Reinforcement Learning via Self-Play" ist der Schlüssel zum Reasoning in Sprachmodellen

Ein Forschungsteam schlägt ein neues Framework namens RLSP vor, das Suchverhalten in großen Sprachmodellen stimuliert und so zu besseren Schlussfolgerungen führt. Die Modelle zeigen interessante emergente Eigenschaften.
Laut Forschern des MIT, der Cornell University, der University of Washington und Microsoft Research könnte ein Framework namens "Reinforcement Learning via Self-Play" (RLSP) der Schlüssel sein, um großen Sprachmodellen (LLMs) die Fähigkeiten beizubringen, die in Modellen wie OpenAIs o1, o3, Deepseeks R1 oder Googles Gemini Thinking beobachtet werden. RLSP verwandelt LLMs in "Large Reasoning Models" (LRMs), die während der Inferenz mehr Zeit und Rechenleistung aufwenden, um qualitativ hochwertigere Ergebnisse zu erzeugen.
Das RLSP-Framework besteht aus drei Schritten: Zunächst wird Supervised Fine-Tuning (SFT) mit menschlichen oder synthetischen Reasoning-Demonstrationen durchgeführt, wann immer möglich. Dann wird eine Erkundungsbelohnung (Exploration-Reward-Signal) verwendet, um vielfältige und effiziente Reasoning-Verhaltensweisen zu fördern. Zuletzt erfolgt RL-Training mit einem Outcome-Verifizierer, um Korrektheit sicherzustellen und Reward Hacking zu verhindern.
Die Forscher testeten RLSP empirisch im Bereich Mathematik. Bei Llama-Modellen konnte RLSP die Leistung im MATH-500-Testdatensatz um 23 % steigern. Bei AIME 2024 Mathematikproblemen verbesserte sich Qwen2.5-32B-Instruct dank RLSP um 10 %. Selbst mit der einfachsten Erkundungsbelohnung, die das Modell dazu bringt, mehr Zwischenschritte auszugeben, zeigten die Modelle emergente Verhaltensweisen wie Backtracking, Erkundung von Ideen und Verifikation.
Diese Ergebnisse decken sich weitgehend mit den Erkenntnissen, die das Team hinter Deepseek R1 und R1-Zero sowie kürzlich Forscher von IN.AI, der Tsinghua University und der Carnegie Mellon University berichtet haben.
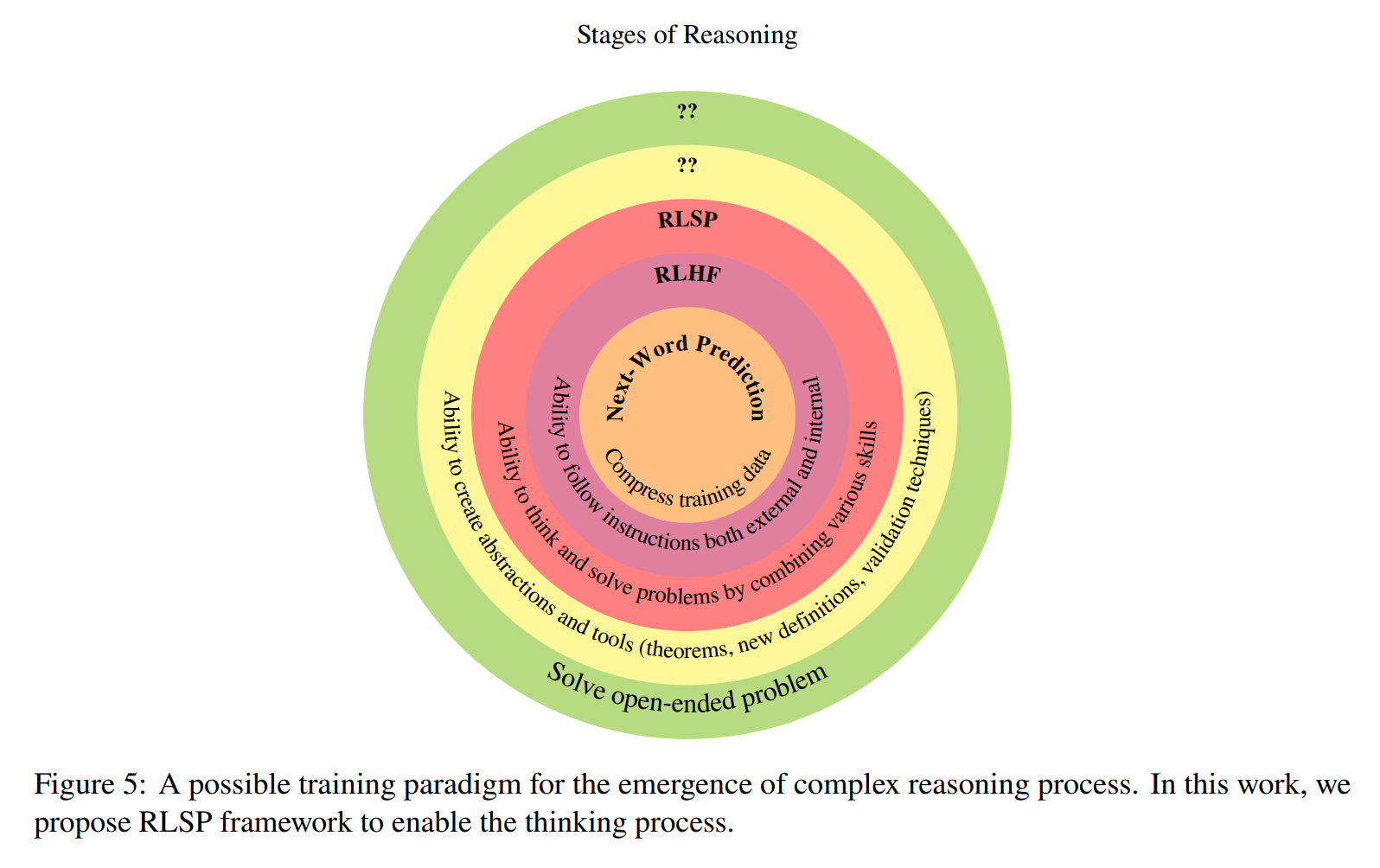
Der interessanteste Beitrag der Arbeit ist laut den Forschern das Verständnis der emergenten Eigenschaften von Modellen, die mit RLSP trainiert wurden. Selbst ohne überwachtes Lernen (SFT), aber mit minimaler Erkundungsbelohnung, lernen alle Modelle in den Bereichen Code und Mathematik mehrere interessante Suchverhaltensweisen.
Sie zeigen verschiedene emergente Eigenschaften wie die Erkundung alternativer Möglichkeiten, Gegenprüfung, Backtracking und Selbstkorrektur. RLSP ermöglicht solche emergenten Suchverhaltensweisen über mehrere Modellfamilien, -größen und Domänen hinweg.
Warum RLSP funktioniert
Die Forscher schlagen eine Theorie vor, warum die RLSP-Suchstrategie besser für LLMs geeignet ist als frühere Ansätze: Jüngste Ergebnisse zeigten, dass "Chain-of-Thought" (CoT) nachweislich die Rechenleistung von LLMs und damit das Reasoning erhöht. Je länger die CoT-Spur ist, desto mehr Rechenleistung steht für das Reasoning zur Verfügung.
RLSP rege Modelle an, synthetisch neuartige Chain-of-Thought (CoT) Reasoning-Pfade zu generieren, die nicht bereits in den Trainingsdaten enthalten sind, und daraus zu lernen. Dies geschieht in Form von "Self-Play" - ein zentrales Konzept der Suche und verwandten KI-Modellen wie AlphaZero.
Durch die verwendeten Belohnungssignale, die das Modell dazu ermutigen, mit zunehmender Problemschwierigkeit mehr Zwischenschritte zu verwenden und verschiedene Begründungen zu erkunden, können diese neuartigen CoT-Pfade entstehen. Die Erkundungsbelohnung fördert die Ausgabe aller Zwischenschritte (CoT), auch wenn die meisten Pfade während des RL-Trainings nicht zur korrekten Antwort führen. Wenn das Modell jedoch schließlich über einen langen Reasoning-Pfad die richtige Antwort findet, erhält es die volle Belohnung.
Auf diese Weise erzeugt RLSP durch Self-Play neue CoT-Daten. Da bekannt ist, dass CoT die Reasoning-Fähigkeiten von LLMs verbessert, könne RLSP diese Fähigkeiten im Prinzip kontinuierlich weiter verbessern, solange es ausreichend vielfältige neue Probleme zu lösen gibt.
Die emergenten Verhaltensweisen der mit RLSP trainierten Modelle, wie das Erkunden mehrerer Begründungen und das Verifizieren, dass alle zum gleichen Ergebnis führen, scheinen diese Theorie laut dem Team zu bestätigen. RLSP ermögliche es den Modellen, durch das Generieren synthetischer CoT-Spuren kontinuierlich besser zu werden.
Viele Fragen bleiben offen
Dennoch bleiben laut dem Team viele Fragen offen. Wie könne beispielsweise eine feinkörnigere Suche zur Laufzeit in LLMs ermöglicht werden, bei der die Suchzeit direkten Einfluss auf die Lösungsqualität hat? So könnte das Modell zwischen trivialen Aufgaben wie 1+1 und komplexen Problemen wie der Riemann-Hypothese unterscheiden. Welchen Einfluss hat die Kontextlänge auf das Reasoning und kann reine RL ohne Erkundungsbelohnung ab einer bestimmten Modellgröße zu Denkverhalten führen? Was ist der genaue Einfluss der Pre-Training-Daten?
Außerdem: Auch wenn die Modelle interessante Suchstrategien wie Backtracking und Verifizierung zeigen, sind diese den Forschern nicht völlig unerwartet, da sie indirekt auch in den Pre-Training-Daten vorkommen. Es gelte daher auch die Frage zu beantworten, ob es wirklich neuartige emergente Verhaltensweisen gebe, die menschliches Denken übertreffen oder zumindest überraschen?
Und: Welche weiteren Trainingsmethoden sind nötig, um noch höhere Formen des Reasoning wie Abstraktion, Theoriebildung und das Lösen offener Probleme zu erreichen?
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.