Studie zeigt: "Test-Time Compute Scaling" ist der Weg zu besseren KI-Systemen

Forscher von Hugging Face zeigen, wie sich die Leistung von Open-Source-Sprachmodellen durch intelligente Skalierung der Rechenleistung bei der Inferenz deutlich steigern lässt - inspiriert durch das o1-Modell von OpenAI. Dazu kombinieren sie verschiedene Suchstrategien mit Belohnungsmodellen.
Die Skalierung von Rechenressourcen während des Trainings hat in den letzten Jahren wesentlich zur Entwicklung großer Sprachmodelle (LLMs) beigetragen. Die dafür benötigten Ressourcen werden jedoch zunehmend unerschwinglich, sodass alternative Ansätze in den Fokus rücken. Laut den Forschern von Hugging Face bietet die Skalierung der Rechenleistung während der Inferenz eine vielversprechende Lösung, indem dynamische Inferenzstrategien verwendet werden, die es den Modellen ermöglichen, länger über komplexe Aufgaben nachzudenken.
Während die Idee des "test-time compute scaling" nicht neu ist und z.B. ein wesentlicher Grund für die starke Leistung von KI-Systemen wie AlphaZero ist, hat OpenAIs o1 erstmals eindrucksvoll gezeigt, dass auch die Leistung von Sprachmodellen durch längeres "Nachdenken" über schwierige Aufgaben deutlich verbessert werden kann. Bei der konkreten Umsetzung gibt es allerdings mehrere mögliche Ansätze - und welcher davon von OpenAI verwendet wird, ist noch nicht bekannt.
Von einfachen zu komplexen Suchstrategien
Die Wissenschaftler untersuchten drei zentrale suchbasierte Ansätze: Die "Best-of-N"-Methode generiert mehrere Lösungsvorschläge und wählt den besten aus. Beam Search untersucht den Lösungsraum systematisch mit Hilfe eines Process Reward Models (PRM). Die neu entwickelte "Diverse Verifier Tree Search" (DVTS) optimiert zusätzlich die Vielfalt der gefundenen Lösungen.
Die Ergebnisse der Praxistests sind beeindruckend: Ein Llama-Modell mit nur einer Milliarde Parametern erreichte die Leistung eines achtmal größeren Modells. Bei mathematischen Aufgaben erzielte es eine Genauigkeit von fast 55 Prozent - laut Hugging Face nahe an der durchschnittlichen Leistung von Informatik-Doktoranden.
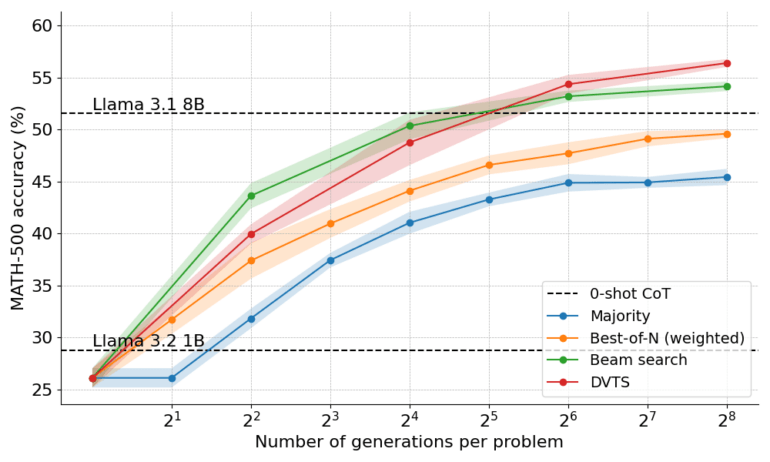
Ein 3-Milliarden-Parameter-Modell übertraf sogar die Leistung des 22-mal größeren 70-Milliarden-Parameter-Modells Llama 3.1 dank der vom Team vorgeschlagenen optimierten Berechnungsmethoden, die für jedes Rechenbudget die jeweils beste Suchstrategie auswählen.
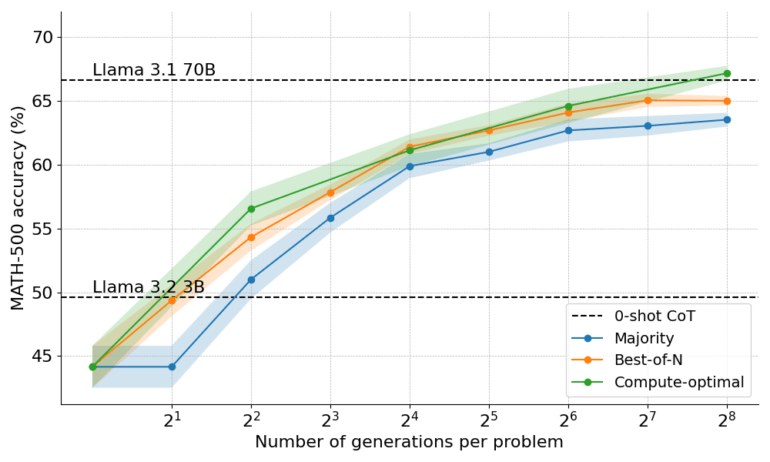
In beiden Fällen verglich das Team die Ergebnisse der kleineren Modelle mit den Inferenzmethoden mit denen der größeren Modelle ohne diese Methoden.
Verifier spielen eine Schlüsselrolle
Eine zentrale Rolle in all diesen Ansätzen spielen sogenannte Verifier oder Belohnungsmodelle. Sie bewerten die Qualität der generierten Lösungen und lenken die Suche auf vielversprechende Kandidaten. Benchmarks wie ProcessBench zeigen laut dem Team jedoch, dass aktuelle Verifier noch Schwächen aufweisen, insbesondere in Bezug auf Robustheit und Generalisierbarkeit.
Die Verbesserung der Verifier ist daher ein wichtiger Ansatzpunkt für zukünftige Forschung, die Königsdisziplin ist jedoch ein Modell, das seine eigenen Ausgaben autonom verifizieren kann - wie es laut dem Team OpenAIs o1 zu tun scheint.
Mehr Informationen, sowie einige der verwendeten Tools, gibt es auf Hugging Face.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.