Tencent entwickelt KI-System, das Spielstrategien erklären und umsetzen kann
Forschende von Tencent haben ein neues Trainingsverfahren entwickelt, bei dem KI-Modelle durch das Spielen von Honor of Kings strategisches Denken lernen sollen. Kleinere KI-Systeme übertreffen dabei deutlich größere Modelle.
Tencent zufolge liegt das grundlegende Problem aktueller KI-Systeme in der Trennung zwischen Wissen und Handeln. Traditionelle KI-Agenten können zwar in Spielen handeln, ihre Entscheidungen jedoch nicht erklären. Sprachmodelle hingegen können Strategien analysieren und begründen, scheitern jedoch bei der praktischen Umsetzung. Ein neues Framework namens Think in Games (TiG) soll diese Lücke schließen.
Die Wissenschaftler:innen wählten das beliebte Smartphone-MOBA (Multiplayer Online Battle Arena) Honor of Kings, das ebenfalls von Tencent entwickelt wird, als Testumgebung. Das Spiel erfordert komplexe strategische Entscheidungen: Teams aus fünf Spieler:innen kämpfen gegeneinander, zerstören Türme und sichern Ressourcen.
Training mit echten Gameplay-Daten
Für ihr Experiment definierten die Wissenschaftler:innen 40 verschiedene Makro-Aktionen wie "Obere Lane angreifen", "Drachen sichern" oder "Basis verteidigen". Die KI muss in jeder Spielsituation die optimale Strategie wählen und diese begründen können.

Als Trainingsmaterial dienten anonymisierte Aufzeichnungen echter Honor-of-Kings-Matches. Die Forschenden achteten darauf, gleich viele gewonnene und verlorene Spiele zu verwenden. Ein spezieller Algorithmus diente dazu, die Daten zu vereinheitlichen und jedem Spielzug eine klare Makro-Aktion zuzuordnen.
Das Training erfolgt in zwei Phasen: Zunächst lernt die KI grundlegende Spielmechaniken durch überwachtes Lernen. Anschließend verfeinert ein Verstärkungslernen-Verfahren die Strategien durch ein einfaches Belohnungssystem: einen Punkt für korrekte Entscheidungen, null Punkte für falsche.
Kleinere Modelle erreichen höhere Trefferquoten
Die Forschenden testeten verschiedene Sprachmodelle als Basis für ihr Framework. Sie verwendeten Qwen2.5-Modelle mit 7, 14 und 32 Milliarden Parametern sowie das neuere Qwen3-14B. Als Vergleichsmaßstab diente Deepseek-R1, ein deutlich größeres System.
Für das Training kombinierten die Wissenschaftler:innen zwei Verfahren: Zunächst destillierten sie Trainingsdaten aus Deepseek-R1, das bereits starke Reasoning-Fähigkeiten in Spielumgebungen zeigt. Anschließend wendeten sie Group Relative Policy Optimization (GRPO) an, das die Modelle durch Vergleich mehrerer generierter Antworten optimiert.
Die Testergebnisse zeigen deutliche Unterschiede zwischen den Ansätzen. Qwen3-14B erreichte nach 2000 Trainingsschritten mit der Kombination aus überwachtem Lernen und GRPO 90,91 Prozent korrekte strategische Entscheidungen. Damit übertraf es Deepseek-R1, das trotz seiner höheren Parameterzahl nur 86,67 Prozent erzielte.
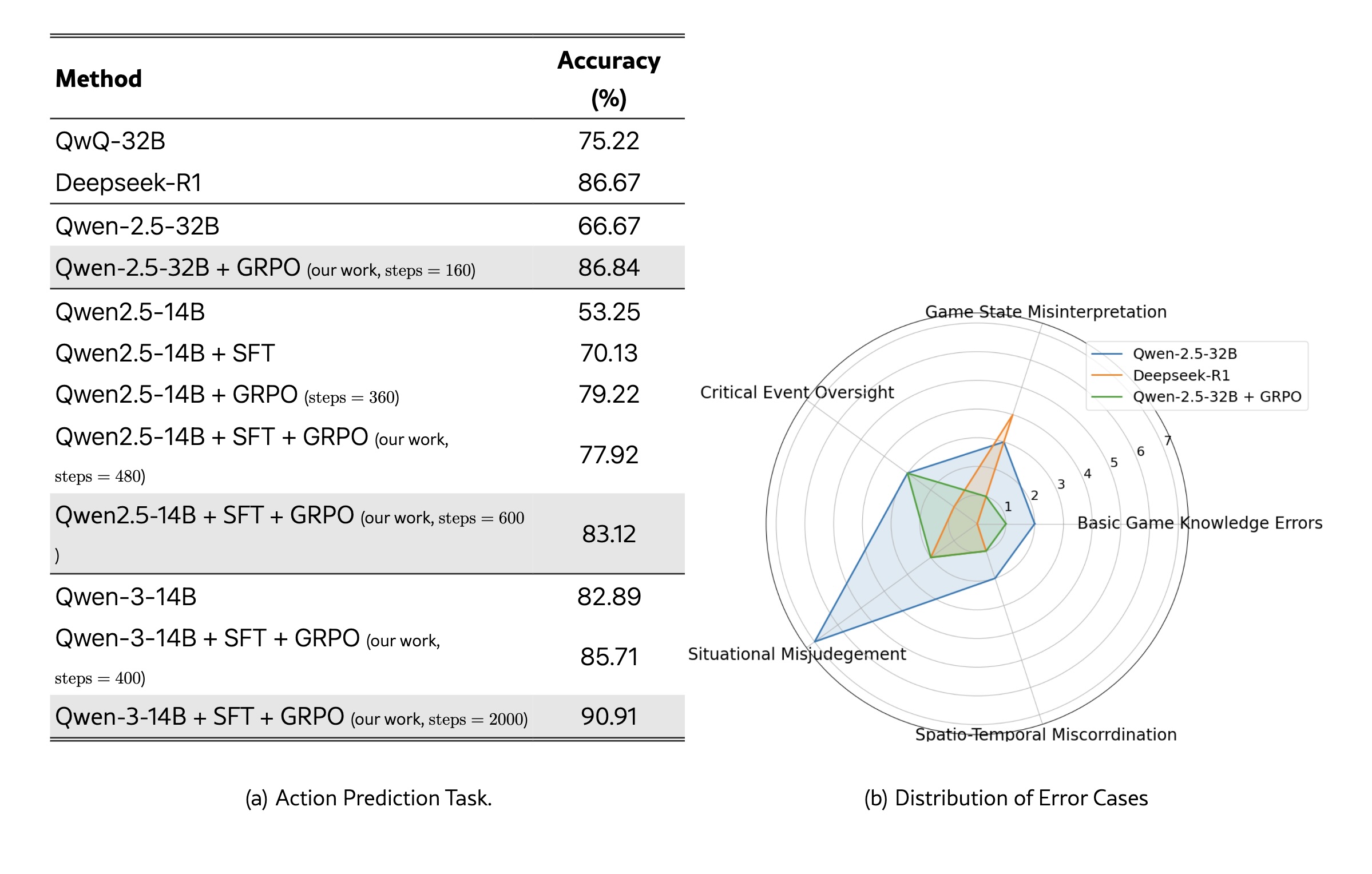
Qwen-2.5-32B profitierte besonders vom GRPO-Training: Die Leistung stieg um mehr als 20 Prozent von 66,67 auf 86,84 Prozent. Qwen-2.5-14B, das kleinere Modell, verbesserte sich durch die sequenzielle Anwendung beider Trainingsmethoden von 53,25 Prozent auf 83,12 Prozent.
Der GRPO-Algorithmus erwies sich dabei als entscheidender Faktor. Er normalisiert Belohnungen innerhalb einer Gruppe von Antworten und berechnet relative Vorteile, wodurch das Training stabilisiert wird.
Die trainierten Systeme können ihre Entscheidungen auch erläutern. In einem Beispiel analysiert die KI eine Spielsituation, identifiziert einen schwachen Turm als Angriffsziel und warnt gleichzeitig vor möglichen Hinterhalten durch gegnerische Spieler:innen.
Andere Fähigkeiten bleiben erhalten
Tests mit verschiedenen Aufgaben zeigen, dass die Honor-of-Kings-trainierten Modelle ihre ursprünglichen Fähigkeiten beibehalten. Sie können weiterhin Texte verstehen, mathematische Probleme lösen und Fragen beantworten.
Die Forschenden sehen Potenzial für Anwendungen über Spiele hinaus. So könnte das Framework beispielsweise auf Bereiche übertragen werden, in denen sowohl strategisches Denken als auch Erklärungsfähigkeit gefragt sind.
Allerdings sagen die Wissenschaftler:innen auch, wo ihre Grenzen sind: Wie gut die Methode ist, hängt davon ab, wie gut die Sprachmodelle sind. Außerdem ist nicht klar, ob sich die Erkenntnisse auf andere Bereiche übertragen lassen.
Neben TiG nutzen auch andere Projekte Gameplay, um strategisches Denken zu testen. Im August 2025 hat Google die "Game Arena" gestartet, eine offene Benchmark-Plattform, auf der Frontier-Modelle gegeneinander antreten und so klassische Benchmarks ersetzen. Schon vorher hat ROCKET-1 gezeigt, dass ein hierarchischer Agent in Minecraft einfache Aufgaben mit einer Erfolgsrate von bis zu 100 Prozent lösen kann. Beide Ansätze zeigen, dass man reales Spielverhalten als Datenquelle und Messlatte für KIs nutzen will.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.