MIRAS und Titans: Google zeigt, wie KI-Modelle dauerhaft dazulernen können

Ein Jahr nach der Veröffentlichung des Titans-Papers stellt Google die Architektur offiziell im eigenen Forschungsblog vor – gemeinsam mit dem neuen Framework MIRAS. Beide Projekte zielen auf ein zentrales Zukunftsthema der KI: kontinuierlich lernende Modelle mit echtem Langzeitgedächtnis, die sich während der Nutzung weiterentwickeln können.
Dort erklärt das Team die Grundmotivation noch einmal sehr klar: Klassische Transformer geraten bei wirklich langen Eingaben – etwa ganzen Büchern, Genomsequenzen oder langen Videos – schnell an ihre Grenzen, weil der Rechenaufwand mit der Kontextlänge quadratisch ansteigt. Effizientere Alternativen wie moderne RNNs oder State‑Space‑Modelle sind zwar schneller, verlieren aber Details, weil sie den gesamten Kontext in einen einzigen kompakten internen Zustand pressen. Titans soll genau diese Lücke schließen, indem es ein genaues Kurzzeitgedächtnis (Attention über das aktuelle Fenster) mit einem separaten, trainierbaren Langzeitspeicher kombiniert, der während der Nutzung weiterlernen kann und vor allem „überraschende“ Informationen gezielt behält.
Neu hinzugekommen ist außerdem das theoretische Rahmenwerk MIRAS, erstmals im April beschrieben im Paper "It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization". Darin argumentieren die Google‑Forscher, dass die vielen neuen Sequenzmodelle der letzten Jahre – von Transformer‑Abwandlungen über RetNet und Mamba bis hin zu DeltaNet und RWKV – alle Varianten derselben Grundidee sind: eines internen Nachschlagewerks, das Eingaben (Schlüssel) mit Ausgaben (Werten) verknüpft.
MIRAS macht vier Fragen explizit, an denen sich diese Modelle unterscheiden: Wie sieht dieses Nachschlagewerk aus (Vektor, Matrix, kleines oder tiefes Netz)? Nach welcher internen „Punkte‑Regel“ entscheidet es, was gut gespeichert ist? Wie schnell verdrängt Neues das Alte? Und nach welcher Lernregel werden die Einträge aktualisiert? Aus dieser Sicht leitet das Team neue, aufmerksamkeitsfreie Modelle wie Moneta, Yaad und Memora ab, die diese Designräume gezielt ausnutzen und in Tests mit sehr langen Kontexten teils besser abschneiden als Mamba2 oder Standard‑Transformer.
Titans und MIRAS sind so Ausdruck der aktuellen Einschränkungen der weit verbreiteten Transformer-Modelle - und vielleicht in Zukunft Teil jener „Ära der Forschung“, die Ilya Sutskever zuletzt im Gespräch mit Dwarkesh Patel gefordert hat. Der ehemalige OpenAI‑Chefwissenschaftler argumentierte, dass bloßes Hochskalieren von Daten und Rechenleistung an Grenzen stößt, und skizzierte mit seinem Startup SSI eine Superintelligenz, die eher wie ein „begabter 15‑Jähriger“ im Job lernt, statt als fertige AGI vom Cluster zu fallen.
Googles Ansatz mag ein anderer sein als der von Sutskever, zielt aber auf dieselbe Lücke ab: weg vom einmal vortrainierten, statischen Modell hin zu Systemen, die ihre Fähigkeiten schrittweise im Einsatz ausbauen – sei es über explizite Gedächtnismodule wie bei Titans oder über neue, noch zu entdeckende Lernparadigmen.
Ursprünglicher Artikel vom 17. Januar 2025
Google-Forscher haben eine neue Transformer-Variante vorgestellt, die Sprachmodelle mit einer Art Langzeitgedächtnis ausstattet. Das System kann Informationen über sehr lange Sequenzen effizient verarbeiten und übertrifft damit etablierte Modelle.
Die KI-Architektur "Titans" soll dem menschlichen Gedächtnis nachempfunden sein. Das System kombiniert künstliches Kurz- und Langzeitgedächtnis über Aufmerksamkeitsblöcke und Gedächtnisnetzwerke und kann so Informationen über außergewöhnlich lange Sequenzen verarbeiten.
Eine Besonderheit des Systems ist laut der Studie sein Lernmechanismus: Titans nutzt "Überraschung" als Metrik, um zu entscheiden, welche Informationen gespeichert werden sollen. Je überraschender eine Information ist, desto wahrscheinlicher wird sie im Langzeitgedächtnis gespeichert. Die Forscher haben auch einen "Vergessensmechanismus" implementiert, der es dem System erlaubt, unwichtige Informationen zu verwerfen und so den Speicher effizient zu nutzen.
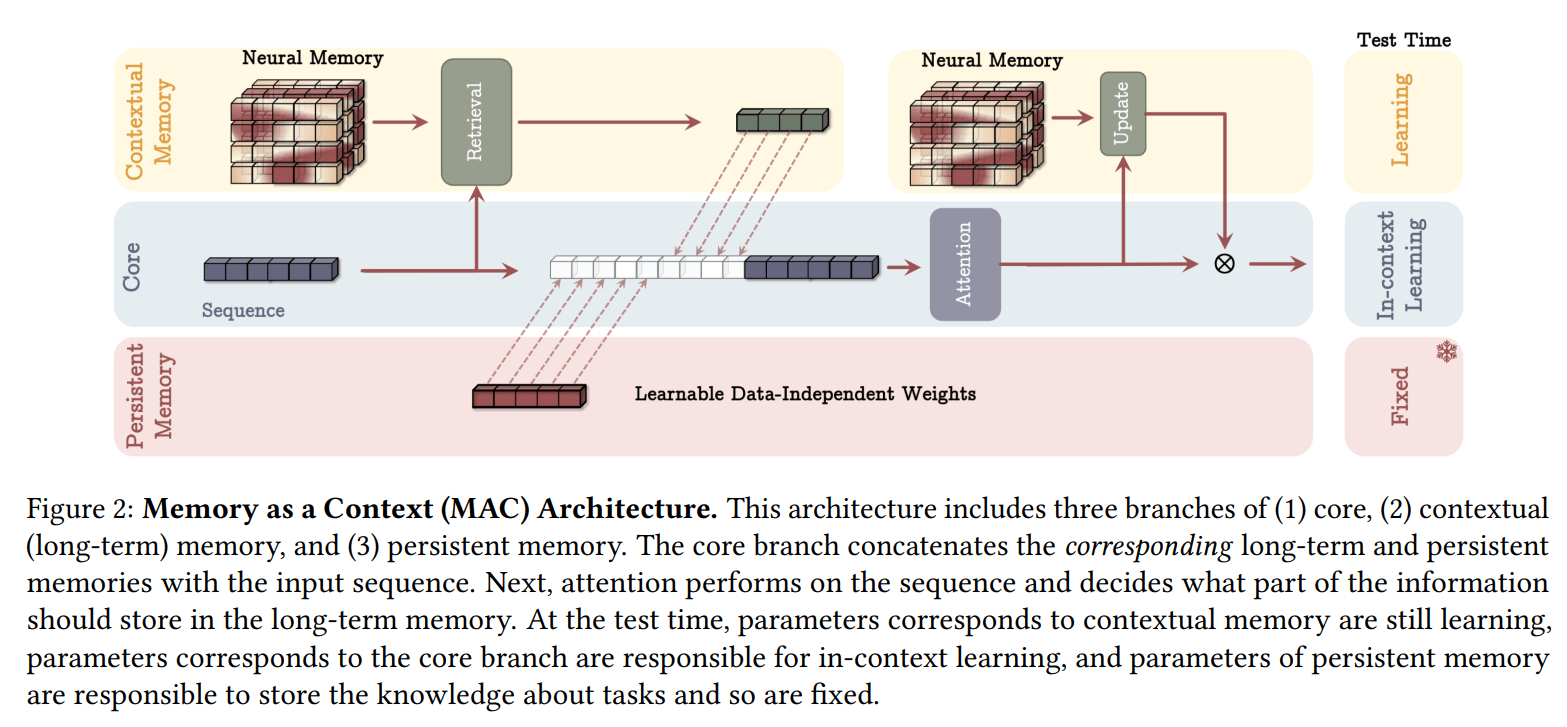
Die Forscher haben drei verschiedene Varianten der Architektur entwickelt, die sich vor allem darin unterscheiden, wie sie das Langzeitgedächtnis einbinden:
- Memory as Context (MAC)
- Memory as Gate (MAG)
- Memory as Layer (MAL)
Jede dieser Varianten zeigt spezifische Stärken bei unterschiedlichen Anwendungen, wobei sich MAC insbesondere bei sehr langen Sequenzen als überlegen erweist.
Titans schlägt andere Transformer-Modelle
In umfangreichen Tests übertraf Titans etablierte Modelle wie den klassischen Transformer oder hybride Modelle wie Mamba2 vor allem bei der Verarbeitung sehr langer Sequenzen. Nach Angaben des Teams kann das System Kontextfenster mit mehr als 2 Millionen Tokens besser verarbeiten. In Tests zur Sprachmodellierung und Zeitreihenvorhersage erreichte das System neue Bestwerte bei langen Kontexten.
Das Team testete Titans auch im "Needle in the Haystack"-Test (NIAH). Bei diesen Tests muss das System bestimmte Informationen in sehr langen Texten finden und verarbeiten - ähnlich einer Nadel im Heuhaufen.
Titans erreichte hier Trefferquoten von über 95 Prozent, selbst bei Texten mit einer Länge von 16.000 Tokens. Aktuelle Spitzenmodelle von OpenAI, Anthropic oder Google erreichen zwar bessere Werte, sind aber deutlich größer: Die größte Titans-Variante kommt auf knapp 760 Millionen Parameter.
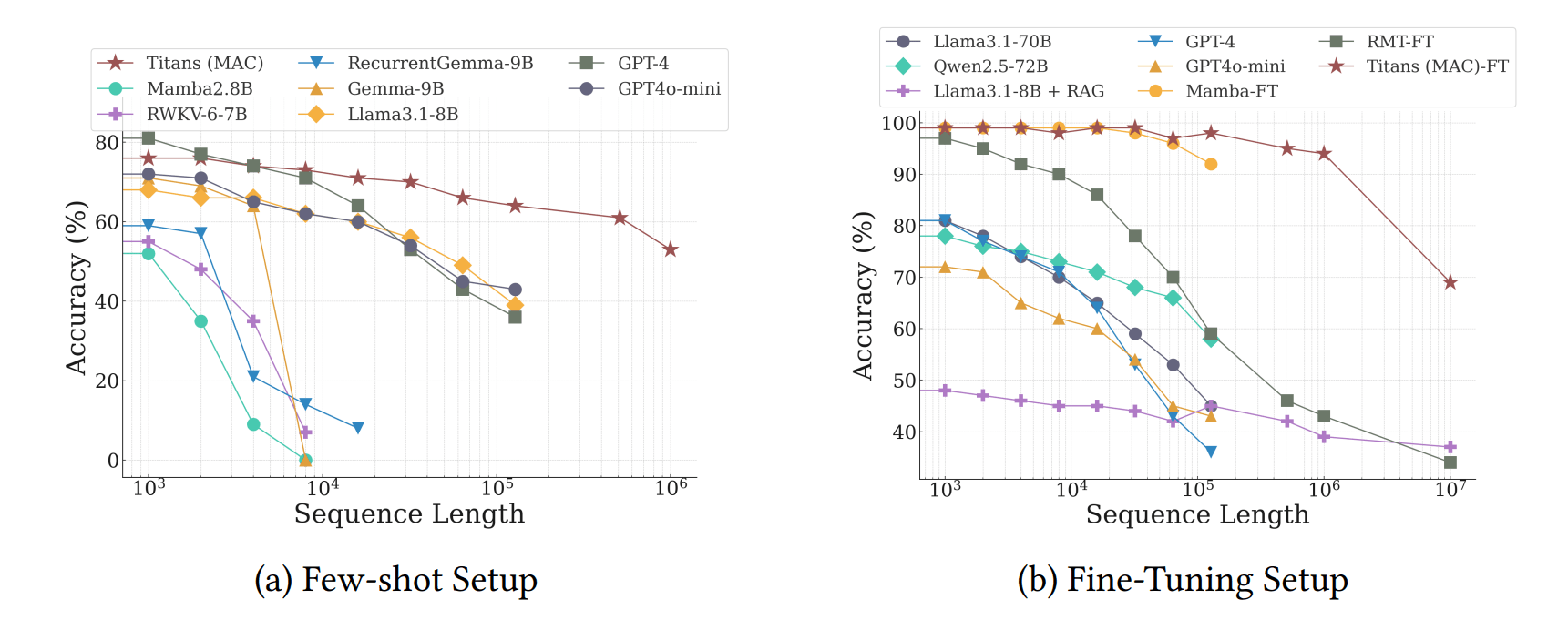
Besonders deutlich wird der Fortschritt beim BABILong-Benchmark, einem besonders anspruchsvollen Test zum Langzeitverständnis. Hier muss das System über Fakten nachdenken, die über extrem lange Dokumente verteilt sind - was eher der Art und Weise entspricht, wie Sprachmodelle für lange Texte verwendet werden.
Hier übertraf Titans deutlich größere Modelle wie GPT-4, RecurrentGemma-9B und Llama3.1-70B. Selbst im Vergleich zu Llama3 mit Retrieval-Augmented Generation (RAG), das zusätzliche Suchtechniken verwendet, schnitt Titans besser ab. Nur auf Retrieval spezialisierte Modelle können Titans hier schlagen - diese sind aber oft nicht gut für generative Aufgaben geeignet.
Das Team hält Titans daher für eine effizientere Architektur als frühere Varianten und plant, den Code in Kürze verfügbar zu machen. Mit Titans und ähnlichen Architekturen könnten in Zukunft Sprachmodelle entstehen, die bei vielen Aufgaben, die größere Kontextfenster und Schlussfolgerungen daraus erfordern, deutliche Fortschritte machen. Aber auch die DNA-Modellierung, die das Team ebenfalls getestet hat, oder andere Anwendungen wie Videomodelle dürften davon profitieren - sofern die guten Ergebnisse in den Benchmarks sich auf die Praxis übertragen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.