
Video-ChatGPT kann Videos im zeitlichen Verlauf beschreiben und dabei Textaufgaben lösen, etwa Sicherheitsrisiken in einer Szene beschreiben, möglicherweise humorvolle Aspekte hervorheben oder einen Werbetext generieren.
Während Unternehmen wie Runway ML Fortschritte bei der Umwandlung von Text in Video machen, geht Video-ChatGPT den umgekehrten Weg und verleiht einem Sprachmodell die Fähigkeit, Videos zu analysieren. Video-ChatGPT kann den Inhalt eines Videos in Texten beschreiben und dabei etwa erklären, warum ein Clip lustig sein könnte, indem es ein ungewöhnliches Element hervorhebt.
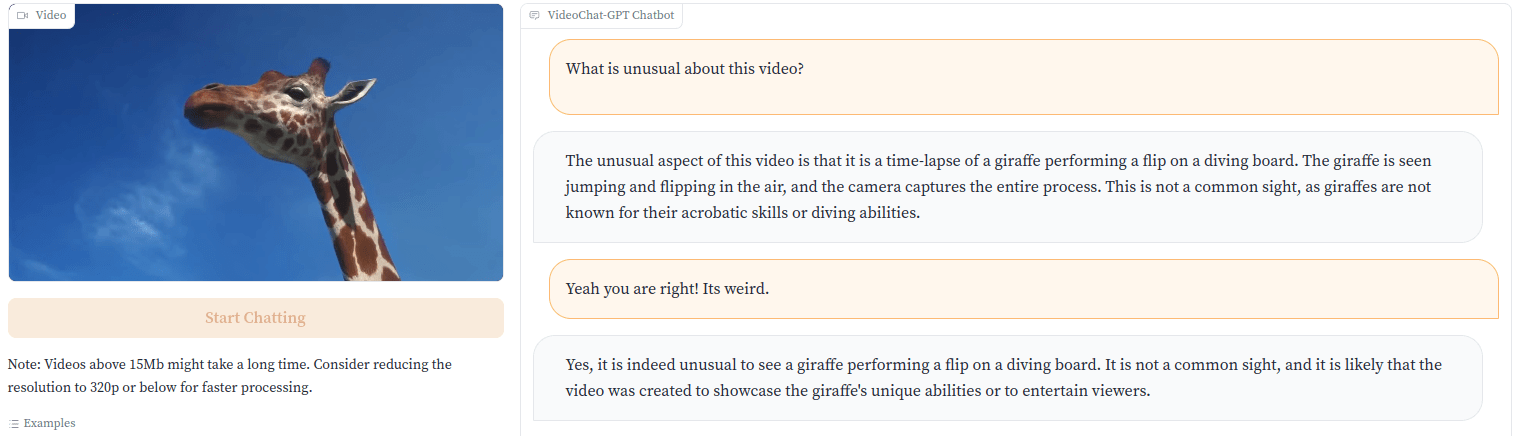
Die Entwickler:innen demonstrieren das mit einem Video, in dem eine Giraffe von einem Sprungbrett ins Wasser springt. "Das ist kein alltäglicher Anblick, denn Giraffen sind weder für ihre Akrobatik noch für ihre Tauchkünste bekannt", stellt Video-ChatGPT richtig fest.
Video- und Sprachencoder mit Sprachmodell verknüpft
Das Design von Video-ChatGPT wird von den Forschenden selbst als einfach und leicht skalierbar beschrieben. Es nutzt bereits vortrainierte Video- und Sprachcoder in Kombination mit einem Sprachmodell.
Anders, als der Name vermuten lässt, verwendet das Projekt der Mohamed bin Zayed University of Artificial Intelligence in Abu Dhabi keine OpenAI-Technologie. Stattdessen kommt das Open-Source-Modell Vicuna-7B zum Einsatz.
Für die multimodale Ausrichtung haben die Wissenschaftler:innen einen sogenannten Linear Layer eingebettet, um das Sprachmodell und den Video-Encoder miteinander zu verknüpfen. Das Sprachmodell erhält neben dem Prompt der Nutzer:innen auch einen Systembefehl, der Vicuna seine Rolle und Aufgabe erklärt.

Wie bei Vicuna selbst wird ein nicht näher spezifiziertes GPT-Modell verwendet, um die Instruktionsdaten für das Feintuning zu verbessern.
Umfassender Datensatz für das Feintuning
Das Modell verwendet eine Mischung aus menschlichen und halbautomatisierten Methoden, um qualitativ hochwertige Daten für das Training des Modells zu generieren. Diese Daten reichen von detaillierten Beschreibungen bis zu kreativen Aufgaben und Interviews und decken somit eine Vielzahl unterschiedlicher Konzepte ab.
Insgesamt umfasst der Datensatz rund 86.000 qualitativ hochwertige Frage-Antwort-Paare, die teils von Menschen, teils von GPT-Modellen und teils mit Kontext aus Bildanalysesystemen verbessert wurden.


Das Herzstück von Video-ChatGPT ist seine Fähigkeit, Videoverständnis und Sprachgenerierung zu kombinieren. Es wurde ausgiebig auf seine Fähigkeiten in den Bereichen Video-Reasoning, Kreativität und Verständnis von Zeit und Raum getestet. Weitere Beispiele gibt es im folgenden Video und im GitHub Repository.
Bis jetzt ist Video-ChatGPT nur über eine Online-Demo verfügbar, in naher Zukunft wollen die Entwickler:innen aber auch Codes und Modelle auf GitHub veröffentlichen.
Multimodale KI-Zukunft
Nach deutlichen Fortschritten im Bereich der Textgenerierung in den vergangenen Jahren wenden sich Unternehmen wie OpenAI und Google mit ihren Modellen der Multimodalität zu. Bard versteht inzwischen Bilder und kann mit solchen antworten, GPT-4 hat diese Fähigkeiten bei der offiziellen Vorstellung immerhin unter Beweis gestellt.
Der Schritt vom Bild zum Bewegtbild wäre der nächste logische Schritt. Google hat mit Project Gemini bereits die Entwicklung eines großen multimodalen KI-Modells angekündigt, das im Laufe des Jahres veröffentlicht werden soll.




