Weniger ist mehr: RAG-Systeme arbeiten besser mit reduzierter Dokumentenzahl
Forschende der Hebrew University of Jerusalem haben herausgefunden, dass die Anzahl der verarbeiteten Dokumente bei RAG (Retrieval Augmented Generation) die Leistung von KI-Sprachmodellen beeinträchtigt, auch wenn die Gesamtlänge des Textes gleich bleibt.
Die Forscher verwendeten dafür den Validierungsdatensatz von MuSiQue, einem Multi-Hop Question Answering Datensatz mit 2.417 beantwortbaren Fragen. Jede Frage ist mit 20 Absätzen aus einzelnen Wikipedia-Dokumenten verknüpft, von denen zwei bis vier die relevanten Informationen zur Beantwortung enthalten, während die übrigen als realistische Distraktoren dienen.

Basierend auf der Struktur von MuSiQue erstellten die Forscher mehrere Datenpartitionen, um den Einfluss der Anzahl der abgerufenen Dokumente kontrolliert zu untersuchen. Sie reduzierten die Anzahl der Dokumente schrittweise von 20 auf 15, 10, acht und schließlich auf die zwei bis vier Dokumente mit den relevanten Informationen.
Dabei behielten sie immer die Dokumente, die die Antwort stützen, und wählten die restlichen zufällig aus der nicht unterstützenden Menge aus. Um die ursprüngliche Token-Anzahl beizubehalten und sicherzustellen, dass die relevanten Informationen in allen Datensätzen an ähnlichen Positionen erscheinen, erweiterten sie die ausgewählten Dokumente mit Text aus den ursprünglichen Wikipedia-Artikeln.
Höhere RAG-Leistung mit weniger Dokumenten
Die Auswertung mehrerer Open-Source-Modelle wie Llama-3.1, Qwen2 und Gemma 2 ergab, dass in den meisten Fällen eine Reduzierung der Dokumentenanzahl die Leistung um bis zu 10 Prozent verbesserte.
Eine Ausnahme bildete Qwen2, das möglicherweise besser mit Sammlungen mehrerer Dokumente zurechtkommt. Die getesteten Modelle sind zwar erst wenige Monate alt, wurden jedoch bereits durch aktuellere Versionen wie Llama-3.3, Qwen2.5 und Gemma 3 abgelöst.
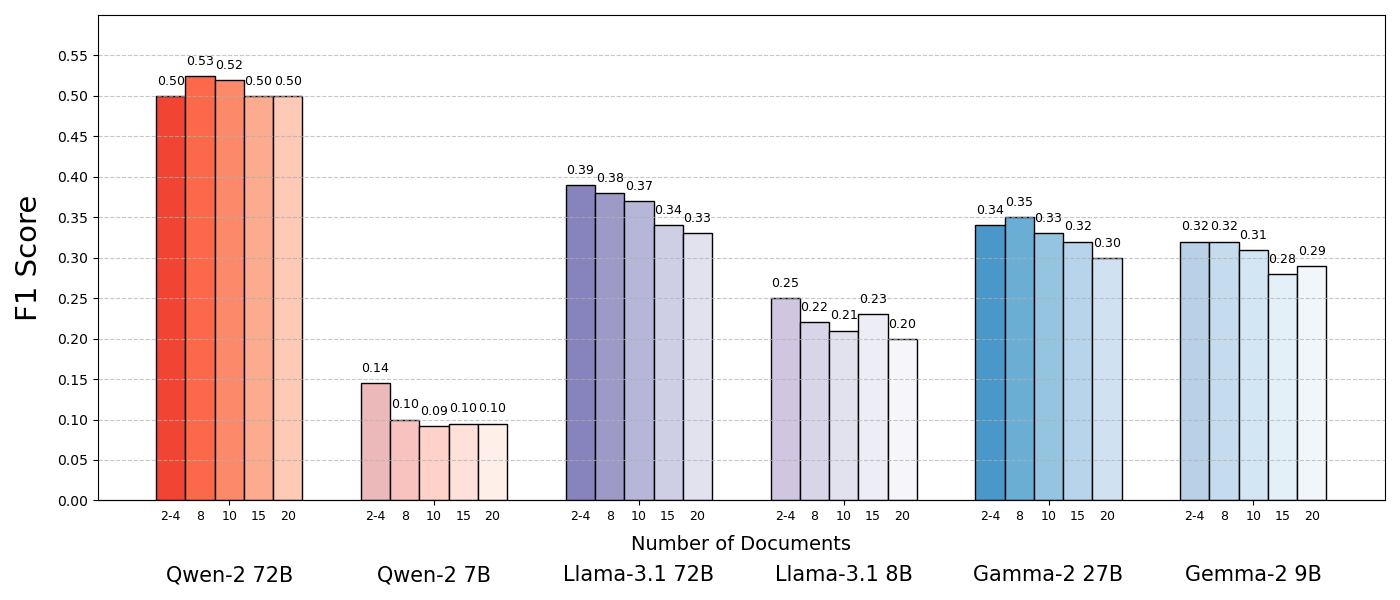
Die Leistung der Sprachmodelle war deutlich höher, wenn sie nur die unterstützenden Dokumente erhielten, was einen viel kürzeren Kontext und die Eliminierung ablenkender Inhalte bedeutete. Die Ergebnisse zeigten auch, dass ähnliche, aber nicht verwandte Dokumente, die oft in RAG abgerufen werden, das Modell verwirren und die Leistung verringern können.
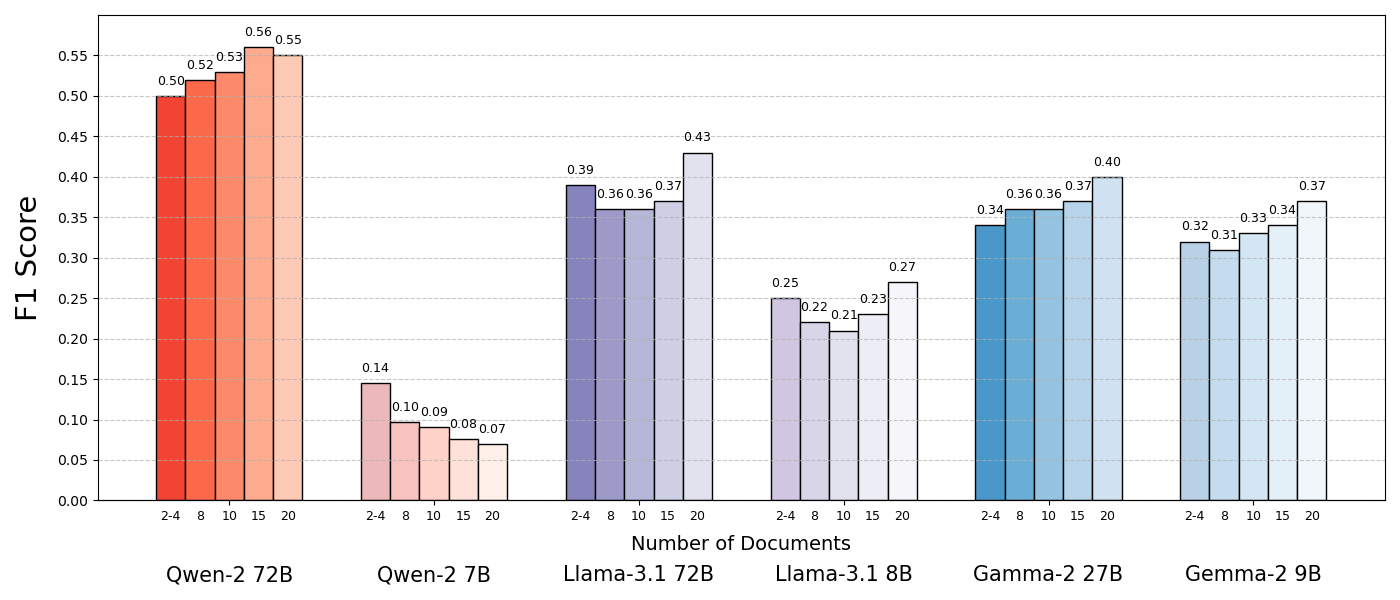
Die Studie zeigt, dass die Eingabe mehrerer Dokumente die Aufgabe in einer Retrieval-Umgebung erschwert und hebt die Notwendigkeit hervor, dass Retrieval-Systeme Relevanz und Vielfalt ausbalancieren müssen, um Konflikte zu minimieren. Zukünftige Modelle könnten von Mechanismen profitieren, die widersprüchliche Informationen erkennen und verwerfen und gleichzeitig die Dokumentenvielfalt nutzen.
Die Forscher:innen weisen auch auf einige Einschränkungen der Studie hin, wie fehlende Untersuchungen zu Promptvariationen oder Auswirkungen der Datenreihenfolge. Die Datensätze der Studie sind öffentlich zugänglich, um weitere Forschungen zur Verarbeitung mehrerer Dokumente zu erleichtern.
RAG vs. große Kontextfenster
Ob RAG-Systeme angesichts immer weiter wachsender Kontextfenster überhaupt noch notwendig sind, ist eine anhaltende Diskussion in der KI-Entwicklung. Obwohl Sprachmodelle zwar immer besser darin werden, große Mengen von Text auf einmal zu verarbeiten, zeigt sich gerade beim Einsatz von eher kleineren Open-Source-Modellen der Vorteil von RAG-Architekturen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.