Forscher der East China Normal University und von Microsoft Research Asia haben untersucht, wie sich große Sprachmodelle wie GPT-4 in dynamischen, interaktiven Szenarien schlagen.
Das Team wollte herausfinden, wie gut Sprachmodelle in der Lage sind, Entscheidungen in sich schnell verändernden Kontexten zu treffen, die den sich ständig ändernden Strategien in der Geschäfts- und Finanzwelt entsprechen, z. B. aufgrund von Marktschwankungen oder Ressourcenknappheit.
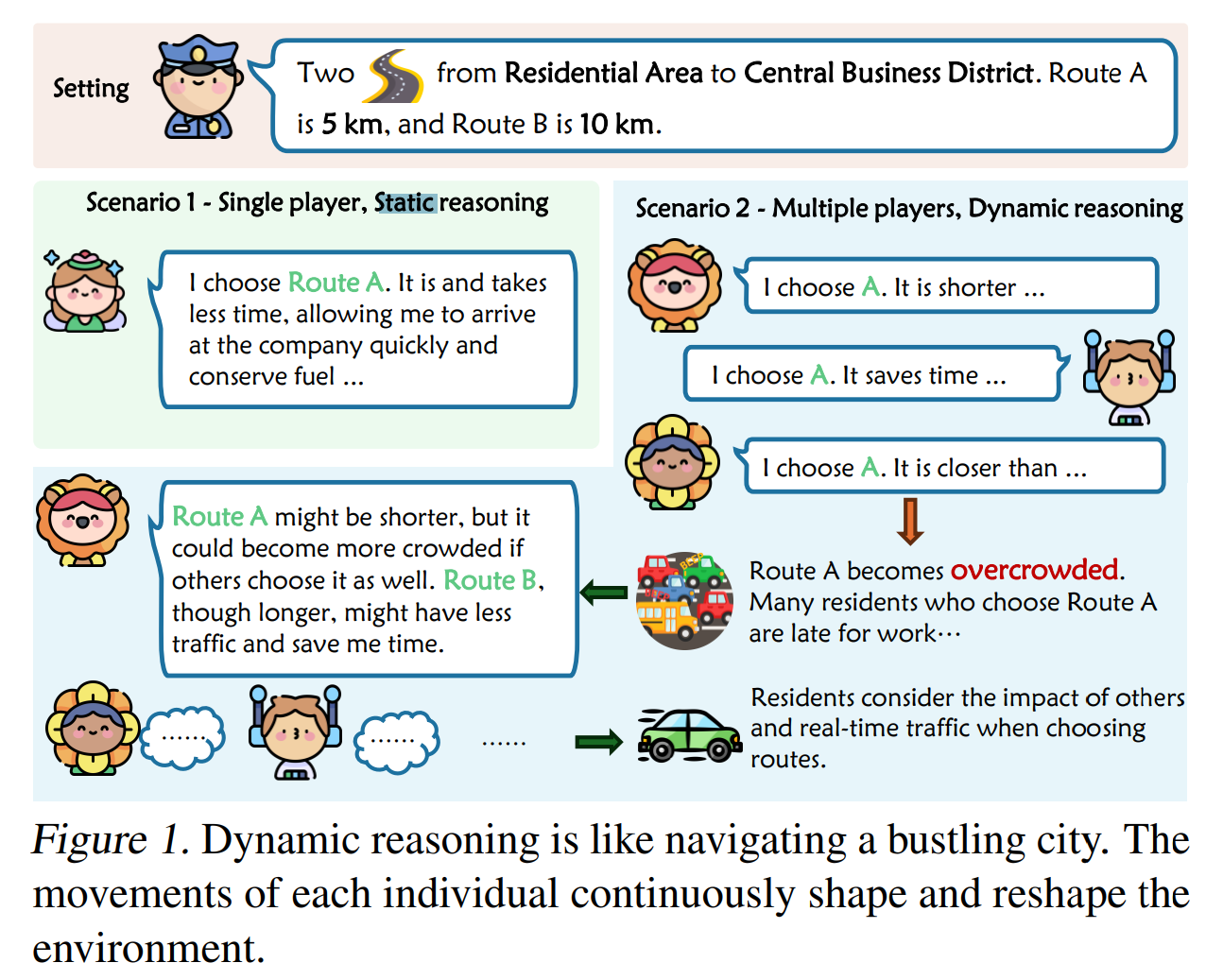
Die Studie zeigt, dass herkömmliche Reasoning-Verfahren wie Chain-of-Thought, die bei statischen Reasoning-Aufgaben gut funktionieren, in diesen dynamischen Umgebungen versagen. Die Forscher entwickelten daher eine neue Methode, die die Leistung von Sprachmodellen in solchen Aufgaben verbessert.
Die Forscher nutzten dazu das von ihnen entwickelte Konzept des "K-Level Reasoning" für Sprachmodelle, einen neuen Ansatz, der auf den Prinzipien der Spieltheorie beruht. Es basiert auf der Idee des "k-level thinking", bei dem ein Spieler nicht nur über seine eigene Strategie nachdenkt, sondern auch versucht, die Züge seines Gegners vorherzusagen. Die Methode verwendet große Sprachmodelle, um die Perspektive der Gegner einzunehmen und ihre möglichen Züge rekursiv zu simulieren. Dieser Prozess berücksichtigt historische Informationen und ermöglicht es der KI, fundiertere Entscheidungen zu treffen.
K-Level Reasoning hängt Chain-of-Thought ab
Die Methode wurde an zwei Spielen mit GPT-4 und GPT-3.5 getestet: "Guessing 0.8 of the Average" (G0.8A) und "Survival Auction Game" (SAG). Im ersten Spiel müssen die Teilnehmer eine Zahl zwischen 1 und 100 wählen, wobei der Gewinner die Zahl wählt, die am nächsten an 80% des Durchschnitts aller gewählten Zahlen liegt. Im zweiten Spiel ersteigern die Teilnehmer Wasserressourcen, um eine fiktive Dürreperiode zu überleben, wobei sie ihre Gesundheitspunkte und finanziellen Ressourcen im Gleichgewicht halten müssen.
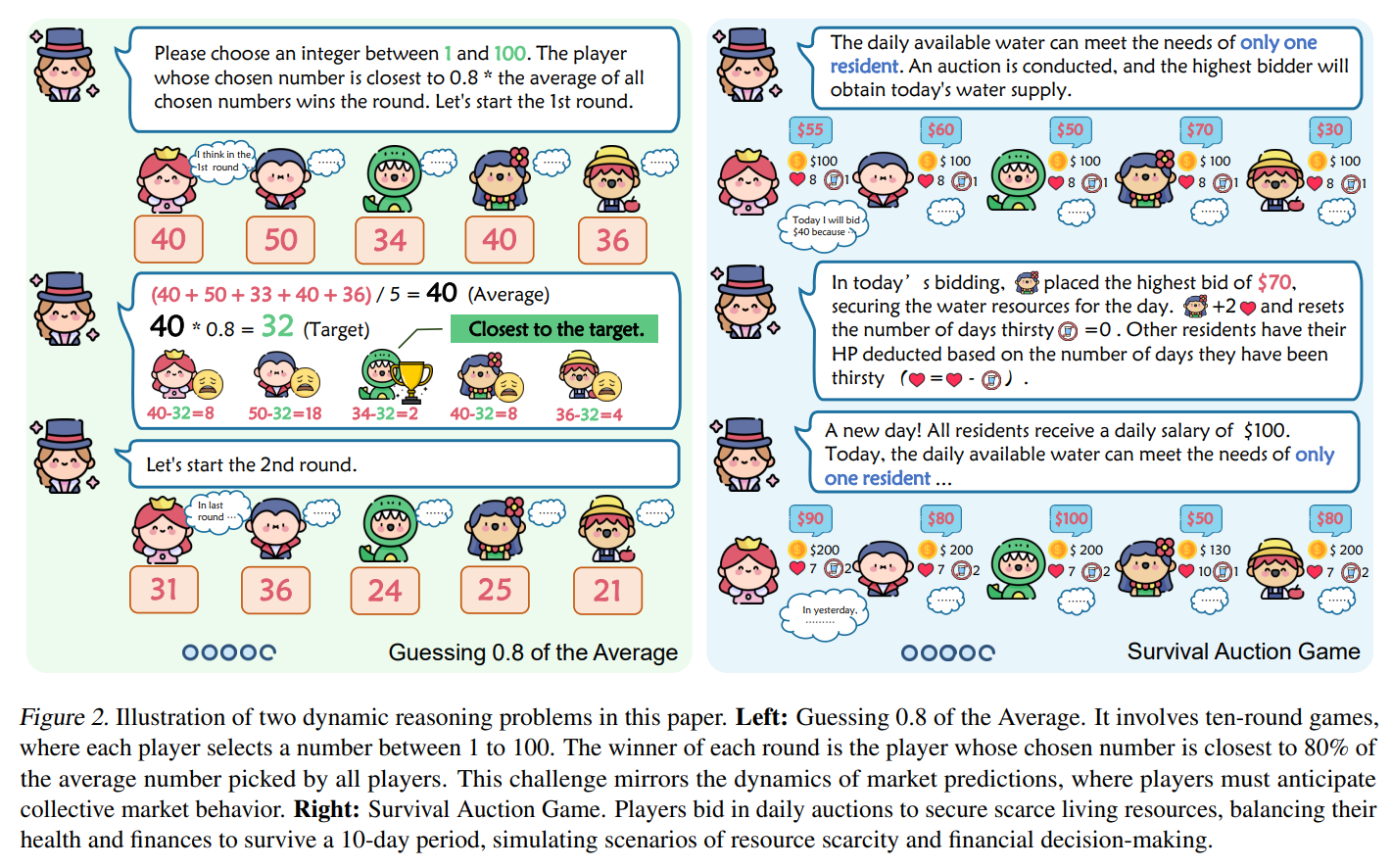
Die K-Level Reasoning Methode zeigte eine überlegene Leistung im Vergleich zu anderen Ansätzen. Sie führte zu einer höheren Gewinnquote in den Spielen und zeigte eine bessere Anpassungsfähigkeit an sich ändernde Bedingungen. Die Methode war auch in der Lage, die Aktionen des Gegners genauer vorherzusagen und somit strategisch klügere Entscheidungen zu treffen.

Das Team sieht die eigene Arbeit als Vorlage für weitere Tests von Sprachmodellen in solchen komplexen Szenarien, aber auch als Hinweis für das bisher ungenutzte Potenzial, das noch in Sprachmodellen steckt.