VIMA: Multimodale Modelle erreichen die Robotik

VIMA kann multimodale Prompts für Roboter verarbeiten und erreicht mit zehnmal weniger Daten eine höhere Leistung als vergleichbare Modelle.
Prompt-basiertes Lernen hat sich als zentrales Feature großer Sprachmodelle wie OpenAIs GPT-3 herauskristallisiert: Ein mit großen Datenmengen lediglich auf die Vorhersage von Token trainiertes Modell kann durch gezieltes Prompting zahlreiche spezialisierte Aufgaben in der Sprachverarbeitung übernehmen.
Methoden wie das Chain-of-Thought-Prompting oder Algorithmic Prompting zeigen zudem, welche Auswirkung unterschiedliche Formulierungen auf die Leistung der Modelle in diesen Aufgaben haben können.
KI-Forschende haben im letzten Jahr solche Modelle auch in der Robotik eingesetzt. Google hat etwa das riesige PaLM genutzt, um einen Roboter direkt mit PaLM-SayCan zu steuern. Das Projekt war eine Weiterentwicklung der inneren Monologe für Roboter. In einem weiteren Projekt zeigte Google die Echtzeit-Steuerung für Roboter per Sprachmodell und jüngst den Robotics Transformer 1 (RT-1), ein multimodal trainiertes Robotik-Modell.
VIMA erlaubt multimodales Prompting
Forschende von Nvidia, Stanford, Macalester College, Caltech, Tsinghua und UT Austin zeigen mit VisuoMotor Attention (VIMA) ebenfalls ein multimodales Modell. Anders als Googles RT-1 kann VIMA jedoch multimodale Prompts verarbeiten.
In der Robotik gibt es verschiedene Aufgaben, die üblicherweise von speziellen Modellen übernommen werden. Dazu zählen das Nachahmen einer Aktion nach einer einmaligen Demonstration, das Befolgen von Sprachanweisungen oder Ziele zu erreichen, die als Bild vermittelt werden. Statt auf unterschiedliche Modelle zu setzen, vereint VIMA diese Fähigkeiten mit multimodalen Prompts, die Text und Bild verknüpfen.
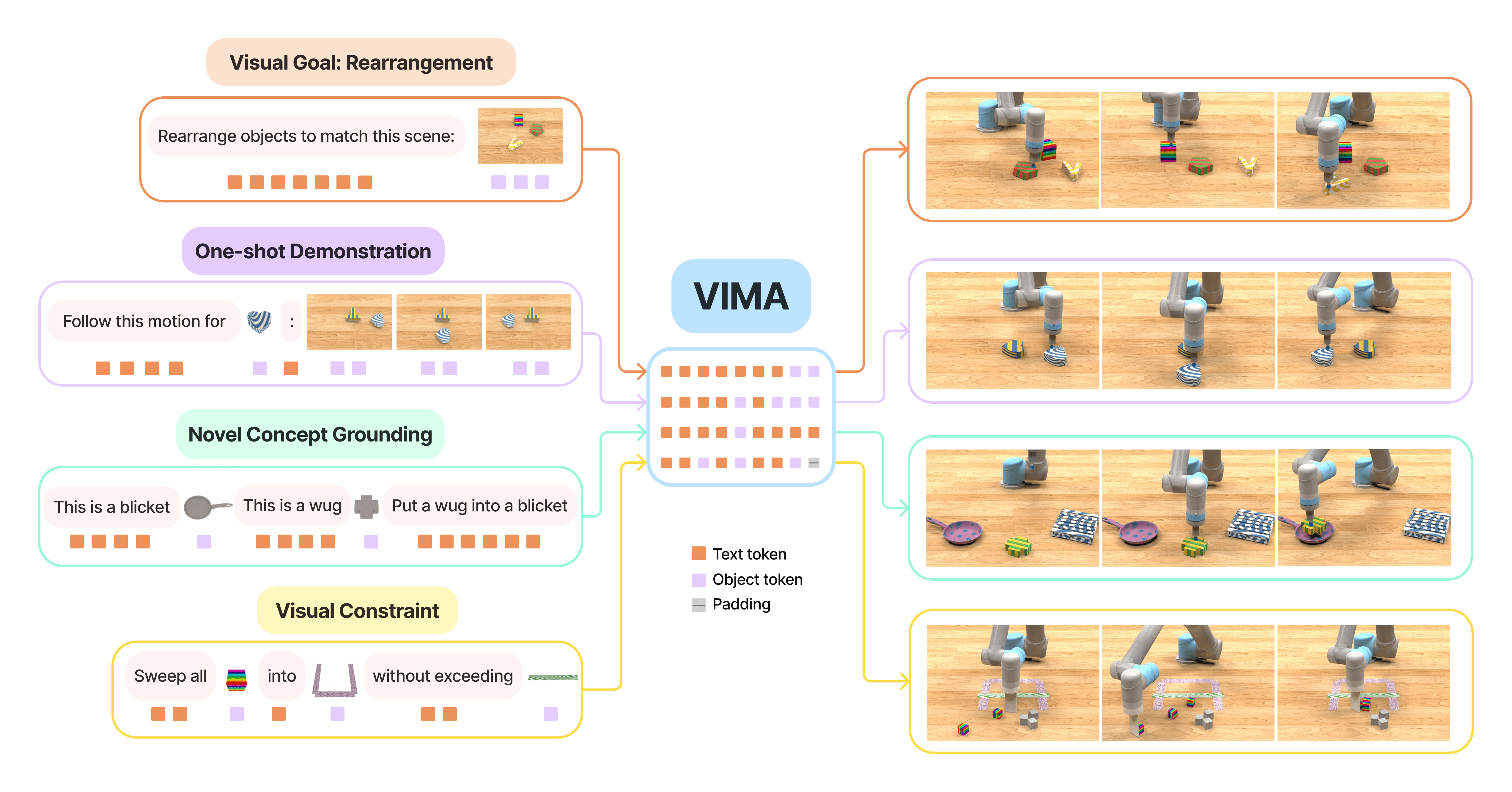
So kann VIMA etwa eine Anweisung wie "Sortiere die Objekte wie in dieser Szene" plus ein passendes Bild der gewünschten Anordnung direkt verarbeiten. Das Modell steuert dann einen Roboterarm in einer Simulation, um die Anweisungen auszuführen.
Das Transformer-Modell wurde mit VIMA-Bench trainiert, einem von den Forschenden erstellten Simulations-Benchmark mit Tausenden von prozedural generierten Tabletop-Aufgaben in 17 Kategorien mit passenden multimodalen Aufforderungen und mehr als 600.000 Roboterbewegungen für das Imitationslernen.
VIMA hängt andere Modelle deutlich ab - und das mit zehnmal weniger Daten
Laut des Teams übertrifft VIMA Modelle wie Gato, Flamingo oder Decision Transformer um das bis zu 2,9-fache - und das über alle Modellgrößen und Generalisierungsebenen hinweg.
Das größte VIMA-Modell erreicht 200 Millionen Parameter. VIMA sei zudem sehr stichprobeneffizient im Imitationstraining und erreiche vergleichbare Leistung wie andere Methoden mit zehnmal weniger Daten.
Ähnlich wie bei GPT-3 sollte ein generalistischer Roboteragent eine intuitive und ausdrucksstarke Schnittstelle für menschliche Benutzer haben, um ihre Absichten zu vermitteln. In dieser Arbeit stellen wir eine neue multimodale Prompting-Formulierung vor, die verschiedene Robotermanipulationsaufgaben in ein einheitliches Sequenzmodellierungsproblem umwandelt.
Wir schlagen VIMA vor, einen konzeptionell einfachen Transformer-basierten Agenten, der in der Lage ist, Aufgaben wie visuelle Ziele, One-Shot-Video-Imitation und neuartige Konzeptfindung mit einem einzigen Modell zu lösen.
Aus dem Paper
VIMA bietet laut der Forschenden eine wichtige Grundlage für zukünftige Arbeiten. Das sieht auch Google so: In seiner Arbeit bezeichnete das Unternehmen das multimodale Prompting von VIMA als vielversprechende Zukunftsperspektive für RT-1. Der Einsatz von multimodalen Modellen in der Robotik wird also in Zukunft weiter zunehmen.
Video: Jiang, Gupta, Zhang, Wang et al.
Mehr Beispiele, den Code und vortrainierte Modelle gibt es auf der VIMA-Projektseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.