Eine neue Methode zeigt, wie große Sprachmodelle wie GPT-3 zuverlässiger Matheaufgaben lösen können.
Große Sprachmodelle wie GPT-3 sind schlecht in Mathematik - eine Erkenntnis, die für viel Aufmerksamkeit sorgte, als OpenAI das Modell vorstellte. Denn dass GPT-3 überhaupt einige Zahlen addieren konnte, war so vorher nicht erwartet worden.
Seitdem entwickeln Forschende immer neue Methoden, die Mathematik-Fähigkeiten großer Sprachmodelle zu verbessern, etwa mit unterschiedlichen Formen von Prompt Engineering oder Zugriff auf einen externen Python-Interpreter.
Algorithmic Reasoning als Prompt-Eingabe
Beim Prompt Engineering experimentieren Forschende mit verschiedenen Eingabemustern und messen ihre Auswirkung auf die Ausgabe der Sprachmodelle. Dass unterschiedliche Eingaben teils deutlich bessere Ergebnisse hervorrufen, zeigt etwa das "Chain-of-thought"-Prompting.
Doch trotz dieser Fortschritte können Sprachmodelle ohne externen Zugriff selbst einfache algorithmische Aufgaben gar nicht oder nicht zuverlässig lösen. Forschende der Universite de Montreal und Google Research haben jedoch eine Methode des Prompt Engineering entwickelt, die die Leistung der Modelle deutlich steigert.
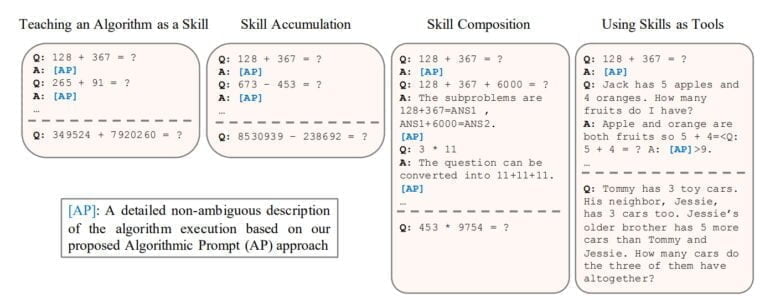
Das Team formuliert dafür detaillierte Algorithmen, etwa für Addition, als Prompt-Eingabe, die sicherstellt, dass das Sprachmodell diesen Algorithmus als Werkzeug einsetzen kann, um weitere vergleichbare Probleme zu lösen. Die Forschenden weisen nach, dass die Modelle diese Algorithmen tatsächlich nutzen können und evaluieren ihren Ansatz an einer Reihe von arithmetischen und quantitativen Reasoning-Aufgaben.
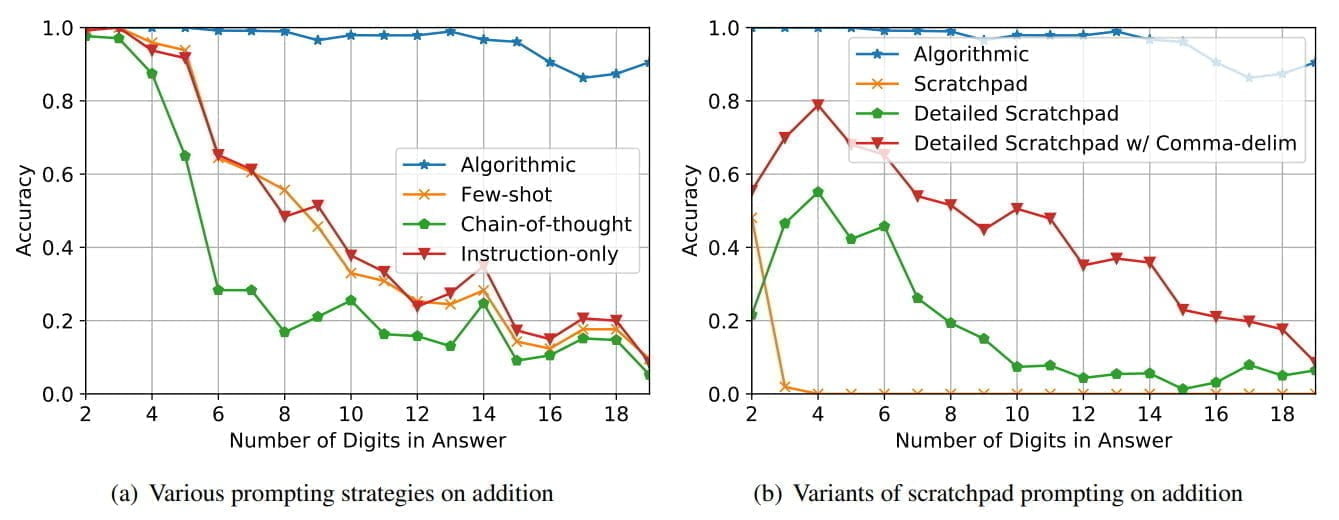
Durch ihren "Algorithmic Prompting"-Ansatz erreichen die Sprachmodelle eine signifikante Leistungssteigerung im Vergleich zu anderen Prompt-Strategien: Insbesondere bei langer Parität, Addition, Multiplikation und Subtraktion erreiche die Lösung bis zu 10-fach niedrigere Fehlerraten und kann Aufgaben mit deutlich mehr Zahlen lösen.
Die Forschenden zeigen zudem, dass die Sprachmodelle mehrere Fähigkeiten, etwa Addition und Subtraktion, akkumuliert lernen, verschiedene Fähigkeiten gemeinsam in einer Matheaufgabe anwenden und die gelernten Fähigkeiten auch als Werkzeuge in komplexeren Text-Aufgaben einsetzen können.
Algorithmic Prompting in Zeiten von ChatGPT
Am Beispiel der Addition zeigt das Team, dass große Sprachmodelle Anweisungen mit nur fünf Zahlen auf bis zu 19 Ziffern anwenden können. Das sei ein Beispiel für eine Generalisierung und ein direkter Effekt des Algorithmic Prompting. Eine Ausweitung auf größere Zahlen wird laut des Teams durch die verfügbare Kontextlänge der Sprachmodelle beschränkt.


Wer jetzt versucht, die Methode auf ChatGPT anzuwenden, wird feststellen, dass der jüngste Chatbot von OpenAI auch ohne viel Prompt-Engineering korrekte Antworten auf Matheaufgaben ausspuckt. OpenAI nutzt hierfür vermutlich einen externen Interpreter. Warum also weitere Methoden des Prompt-Engineering für Mathematik erforschen?
Ein Bereich mit erheblichem Verbesserungspotenzial ist die Fähigkeit großer Sprachmodelle, komplexe logische Aufgaben zu lösen. In diesem Bereich stellt das mathematische Denken eine einzigartige Herausforderung dar. Es erfordert die Fähigkeit, ein Problem logisch zu analysieren, in Teilprobleme zu zerlegen und diese neu zu kombinieren, sowie das Wissen über Regeln, Transformationen, Prozesse und Axiome anzuwenden.
Aus dem Paper
Methoden wie das "Algorithmic Prompting" könnten also die Fähigkeiten der Modelle verbessern, logisch zu schlussfolgern. Modelle, die lernen, einen Algorithmus auszuführen, können gleichbleibende Ergebnisse erzeugen, Halluzinationen reduzieren und da "Algorithmen von Natur aus Input-unabhängig sind, sind sie bei ordnungsgemäßer Ausführung immun gegen Leistungseinbußen, die außerhalb der gelernten Verteilung auftreten können."
Als zentrale Erkenntnis sieht das Team die Rolle der Kontextlänge: Es könne möglich sein, eine größere Kontextlänge in eine bessere Leistung beim Schlussfolgern umzuwandeln, indem ausführlichere Lösungsbeispiele bereitgestellt werden. Statt eines Zugriffs auf einen externen Interpreter würde das Modell in diesem Fall für unterschiedliche Aufgaben passende Algorithmic Prompts aus einer externen Datenbank abrufen und im Kontext-Fenster ausführen.
Modelle wie GPT-4 sollen die Kontextlänge aktueller Sprachmodelle mutmaßlich verdoppeln. Ob sich mit Methoden wie dem Algorithmic Prompting dann noch bessere Schlussfolgerungen umsetzen lassen, wird sich zeigen.



