Deepminds neue Prompting-Technik geht einen Schritt zurück für mehr Genauigkeit

Ein aktuelles Paper von Alphabets KI-Unternehmen Google Deepmind zeigt, dass eine einfache Anpassung der Prompts die Genauigkeit von großen Sprachmodellen deutlich verbessern kann. Dabei wird die menschliche Fähigkeit zur Abstraktion genutzt.
Bei der sogenannten "Step-Back Prompting"-Technik wird der KI zunächst eine allgemeine Frage gestellt, bevor die eigentliche Aufgabe folgt. So kann das System relevante Hintergrundinformationen abrufen und die eigentliche Frage besser einordnen. Die Methode ist mit nur einer zusätzlichen Einstiegsfrage einfach umzusetzen.
Frage:
Welche Schule besuchte Estella Leopold zwischen August 1954 und November 1954?
Step-Back-Frage:
Was war Estella Leopolds Bildungsgeschichte?
Step-Back-Antwort:
B.S. in Botanik, Universität von Wisconsin, Madison, 1948
M.S. in Botanik, Universität von Kalifornien, Berkeley, 1950
Doktortitel in Botanik, Universität Yale, 1955
Finale Antwort:
Von 1951 bis 1955 war sie im Doktorandenprogramm für Botanik in Yale eingeschrieben. von 1951 bis 1955. Daher war Estella Leopold höchstwahrscheinlich zwischen August 1954 und November 1954 an der Yale University.
In der Deepmind-Untersuchung wurde Step-Back-Prompting am Sprachmodell PaLM-2L getestet und mit dem Basismodell sowie GPT-4 verglichen. Dabei konnten die Wissenschaftler:innen die Genauigkeit der Sprachmodelle um bis zu 36 Prozent gegenüber Chain-of-Thought-Prompting (CoT) steigern.
Verbesserungen in allen getesteten Disziplinen
Step-Back-Prompting wurde in den Bereichen Naturwissenschaften, Allgemeinwissen und logisches Denken getestet. Die größten Verbesserungen beobachteten die Forscherinnen und Forscher bei komplexeren Aufgaben, die mehrere Denkschritte erfordern.
Bei Aufgaben aus Physik und Chemie stieg die Genauigkeit im Vergleich zum unveränderten Modell um 7 bis 11 Prozent. Damit übertraf das angepasste PaLM-2L sogar GPT-4 um einige Prozentpunkte. Die abstrakte Fragestellung des Experiments lautete: "Welche physikalischen oder chemischen Prinzipien und Konzepte sind für die Lösung dieser Aufgabe notwendig?
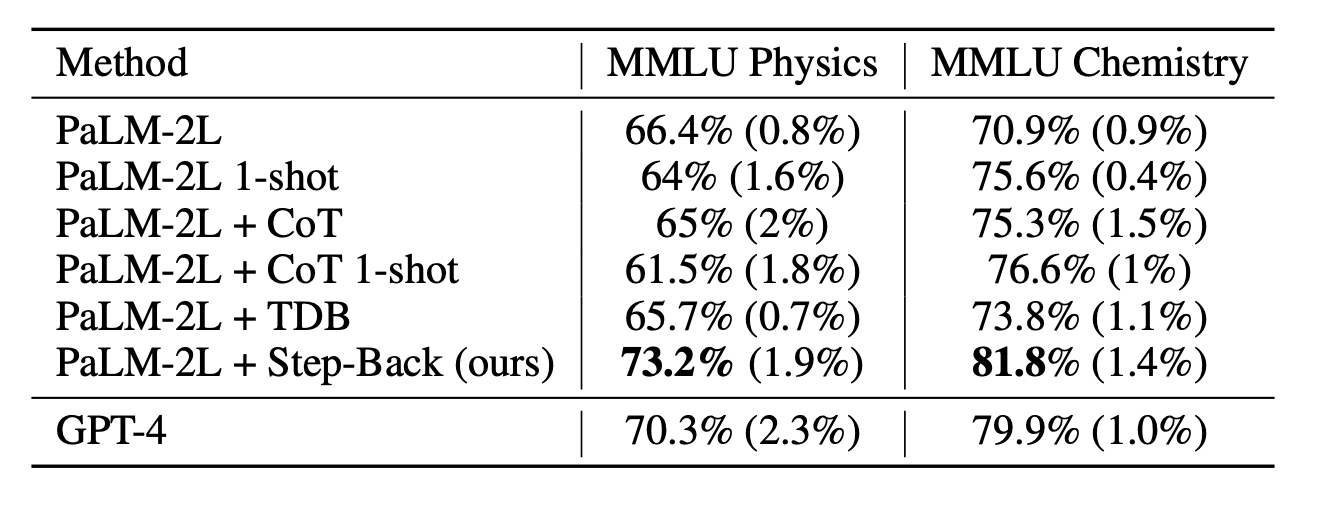
Die wichtigste Erkenntnis ist, dass die Prompting-Technik von DeepMind auch deutlich besser abschnitt als bestehende Methoden wie Chain-of-Thought und "Take a deep breath" (TDB), die die Genauigkeit nur geringfügig verbesserten oder sogar verschlechterten.
PaLM-2L kann mit Step-Back-Prompting bessere Leistungen erzielen als GPT-4
Noch deutlicher war die Verbesserung bei Wissensfragen mit zeitlicher Komponente aus dem Datensatz TimeQA. Hier betrug der Zuwachs durch eine Kombination aus Step-Back-Prompting und Retrieval-Augmented Generation (RAG) satte 27 Prozentpunkte zum Basismodell, damit rund 23 Prozent genauer als GPT-4. Natürlich könnte man Step-Back-Prompting auch mit GPT-4 verwenden, der Vergleich soll nur den Leistungsgewinn demonstrieren.
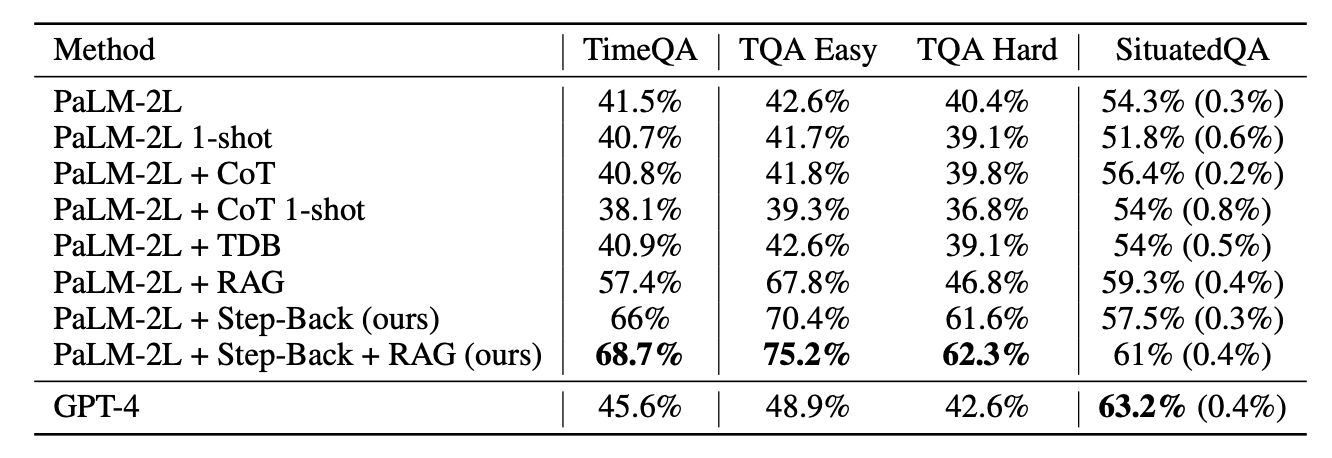
Auch bei besonders schwierigen Wissensfragen, die mit RAG nur weniger häufig korrekt beantwortet werden konnten, verzeichneten die Forschenden durch Step-Back-Prompting einen deutlichen Genauigkeitsgewinn. "Hier kann Step-Back-Prompting wirklich glänzen, indem es Fakten zu übergeordneten Konzepten abruft, um die abschließende Argumentation zu begründen", heißt es im Paper.
Trotz der vielversprechenden Ergebnisse zeigte die Fehleranalyse, dass mehrschrittiges Argumentieren nach wie vor zu den schwierigsten Fertigkeiten eines LLM gehört. Auch sei die Technik nicht immer zielführend oder hilfreich, etwa wenn die Antwort allgemein bekannt ist ("Wer war im Jahr 2000 Präsident der USA?") oder die Frage bereits auf ein hohes Abstraktionsniveau hindeutet ("Wie groß ist die Lichtgeschwindigkeit?").
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.