MagicVideo-V2: ByteDance stellt leistungsstarkes KI-Modell zur Videogenerierung aus Text vor

ByteDance investiert weiter in die KI-Forschung und stellt ein neues KI-Modell für die Generierung von Videos vor, das andere Methoden übertrifft.
Forscher von Bytedance haben mit MagicVideo-V2 ein neues generatives KI-Modell zur Text-zu-Video (T2V) Generierung entwickelt, das andere T2V-Systeme wie Runways Gen-2, Pika 1.0, Morph, Moon Valley oder Stable Video Diffusion übertreffen soll.
MagicVideo-V2 unterscheidet sich laut dem Team von bestehenden T2V-Modellen durch die Integration mehrerer Module, die zusammenarbeiten, um qualitativ hochwertige Videos zu erzeugen. Das Team kombiniert dafür Text-zu-Bild (T2I), Bild-zu-Video (I2V), Video-zu-Video (V2V) und Video Frame Interpolation (VFI) Module in einer Architektur.
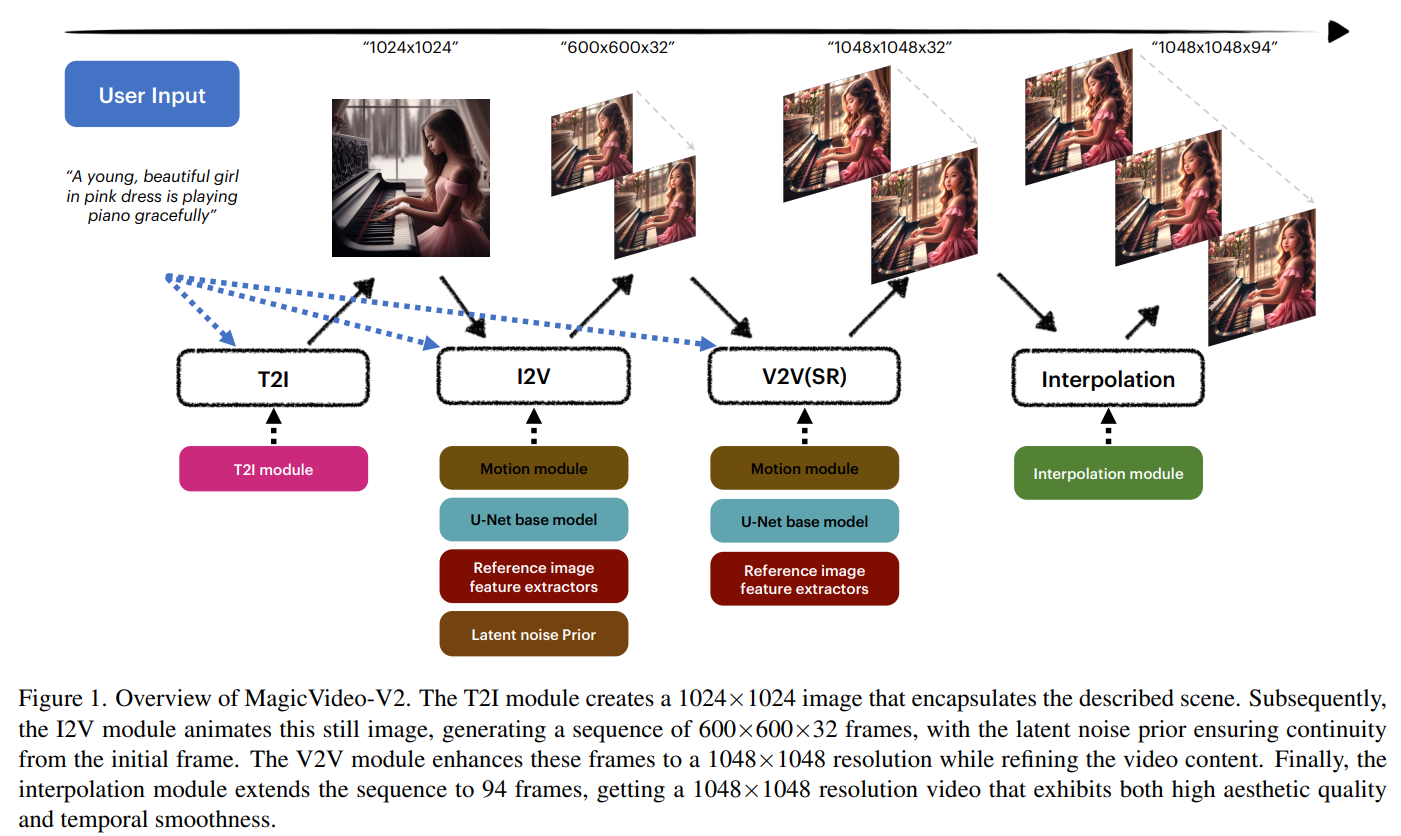
Das T2I-Modul erzeugt ein erstes Bild aus dem Text-Input und liefert so die Grundlage für die weitere Videogenerierung. Das I2V-Modul verwendet dann das Bild als Eingabe und liefert niedrig aufgelöste Keyframes des generierten Videos. Das V2V-Modul erhöht die Auflösung der Keyframes und verbessert ihre Detailgenauigkeit. Schließlich interpoliert das VFI-Modul die Bewegung im Video und glättet sie.
ByteDance erforscht die gesamte Bandbreite generativer KI
Den Forschern zufolge ist MagicVideo-V2 in der Lage, zu Text-Prompts passende, hochauflösende Videos mit 1.048 mal 1.048 Pixeln zu generieren und soll andere generative KI-Modelle für Videos übertreffen. In einem Blindtest mit knapp 60 menschlichen Teilnehmenden wurden die Videos von MagicVideo-V2 häufiger bevorzugt, schreibt das Team. Die besseren Ergebnisse führt das Team auf die Integration der Module in einem einzigen Modell zurück, anstatt mehrere Modelle getrennt hintereinander zu schalten.
Video: ByteDance
Video: ByteDance
Video: ByteDance
Die Ergebnisse von MagicVideo-V2 sind deutlich besser als die der ersten Version, die das Unternehmen bereits Ende 2022 vorgestellt hatte. ByteDance hat kürzlich mit MagicAnimate auch eine Art TikTok-Generator vorgestellt, hat eine offene Plattform für Chatbots in der Entwicklung und forscht mit MVDream auch an Text-zu-3D-Modellen.
Die Forscher planen, MagicVideo-V2 weiter zu verbessern. Mehr Beispiele und Vergleiche mit anderen Modellen gibt es auf der Projektseite von MagicVideo-V2.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.