Stable Video Diffusion: Das beste Open Source KI-Videomodell erhält ein großes Update

Update –
- SDV 1.1 ergänzt
Stability AI veröffentlicht das erste große Update für Stable Video Diffusion, das generative Videomodell des Unternehmens.
Mit dem Update auf Stable Video Diffusion (SVD) 1.1 soll das Modell KI-generierte Videos mit besserer Bewegung und Konsistenz erzeugen. Wie sein Vorgänger ist es öffentlich zugänglich und kann über Hugging Face heruntergeladen werden. Für die kommerzielle Nutzung ist eine Mitgliedschaft bei Stability AI erforderlich.
Das Unternehmen hat im Dezember 2023 einen Abonnement-Service für die kommerzielle Nutzung seiner Modelle gestartet, für nicht-kommerzielle Anwendungen sind alle Modelle weiterhin als Open Source verfügbar.
SVD 1.1 ist laut Modellkarte eine verfeinerte Variante des zuvor veröffentlichten SVD-XT und erzeugt viersekündige Videos mit 25 Frames und einer Auflösung von 1024 x 576 Pixeln.
Ursprünglicher Artikel vom 21. November 2023
Stable Video Diffusion wird in Form von zwei Bild-zu-Video-Modellen veröffentlicht, die jeweils 14 und 25 Bilder mit anpassbaren Bildraten zwischen 3 und 30 Bildern pro Sekunde erzeugen können.
Das auf dem Bildmodell Stable Diffusion basierende Video Diffusion Modell wurde von Stability AI auf einem sorgfältig zusammengestellten Datensatz mit speziell kuratierten, qualitativ hochwertigen Videodaten trainiert.
Dabei durchlief es drei Phasen: Text-zu-Bild-Vortraining, Video-Vortraining mit einem großen Datensatz niedrig aufgelöster Videos und schließlich Video-Feintuning mit einem viel kleineren Datensatz hoch aufgelöster Videos.

Stable Video Diffusion soll kommerzielle Modelle übertreffen
Laut Stability AI haben die eigenen Modelle in Nutzerpräferenzstudien führende geschlossene Modelle wie RunwayML und Pika Labs zum Zeitpunkt der Veröffentlichung übertroffen.
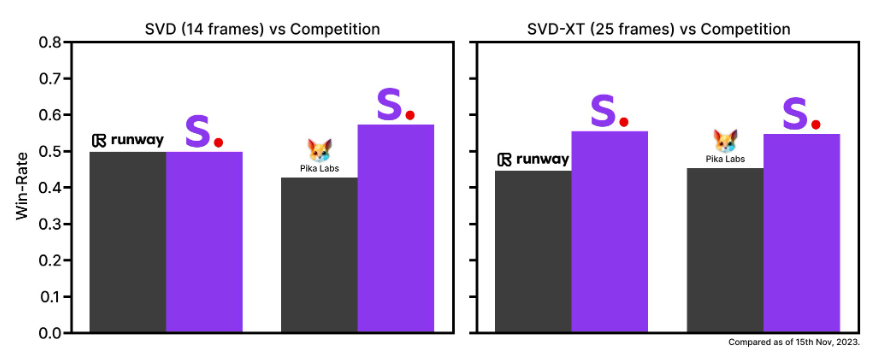
RunwayML und Pika Labs wurden jedoch kürzlich noch deutlicher von Metas neuem Videomodell Emu Video übertroffen, das die beiden vorgenannten Modelle noch viel deutlicher übertraf und weiter vorn liegen dürfte. Es ist allerdings nur als Forschungspapier verfügbar.
Die Forscher schlagen in ihrem Paper auch eine Methode vor, um große Mengen an Videodaten zu kuratieren und große, unübersichtliche Videosammlungen in geeignete Datensätze für generative Videomodelle umzuwandeln. Dieser Ansatz soll das Training eines robusten Basismodells für die Videogenerierung erleichtern.
Stable Video Diffusion gibt es zunächst nur als Forschungsversion
Stable Video Diffusion soll zudem leicht an verschiedene nachgelagerte Aufgaben angepasst werden können, einschließlich der Multi-View-Synthese aus einem Einzelbild mit Feinabstimmung auf Multi-View-Datensätze.
Stability AI plant, ein Ökosystem von Modellen zu entwickeln, die auf dieser Basis aufgebaut und erweitert werden, ähnlich wie bei Stable Diffusion.
Stable Video Diffusion wird zunächst nur als Forschungsversion bei Github veröffentlicht, um Erkenntnisse und Feedback zu Sicherheit und Qualität zu sammeln und das Modell für die endgültige Veröffentlichung zu verfeinern. Die weights sind bei HuggingFace verfügbar.
Das Modell ist in dieser Version nicht für reale oder kommerzielle Anwendungen vorgesehen. Das finale Modell soll wie Stable Diffusion dann frei verwendbar sein.
Zusätzlich zur Veröffentlichung der Forschungsversion hat Stability AI eine Warteliste für eine neue Web-Erfahrung mit einer Text-to-Video-Schnittstelle eröffnet. Dieses Tool soll die praktische Anwendung von Stable Video Diffusion in verschiedenen Bereichen wie Werbung, Bildung und Unterhaltung erleichtern.
Stability AI veröffentlichte zuletzt Open-Source-Modelle für die 3D-Generierung, die Audio-Generierung und die Textgenerierung per LLM.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.