Erstes Fazit zu GPT-4-Feintuning fällt bescheiden aus

Die Datenanalyseplattform Supersimple konnte GPT-4 bereits fine-tunen. Trotz deutlicher Verbesserungen ist der Test jedoch eher ernüchternd.
Die Firma Supersimple, eine Datenanalyseplattform, mit der Benutzer komplexe Ad-hoc-Abfragen in natürlicher Sprache durchführen können, hat vor einigen Wochen einen frühen Zugang zur GPT-4 Finetuning API von OpenAI erhalten.
Supersimple verwendet große Sprachmodelle wie GPT-3.5 und GPT-4, um Benutzeranfragen in natürlicher Sprache zu beantworten. Die LLMs werden mit einem proprietären Datensatz angereichert, der mehrere zehn Millionen Token mit Beispielen für Frage-Antwort-Kombinationen enthält. Die Modelle GPT-3.5 und GPT-4 wurden für jeweils drei Epochen verfeinert.
Die LLMs geben ihre eigene domänenspezifische Sprache (DSL) aus, die dann in JSON und Datenbankabfragen kompiliert wird. Im Gegensatz zu Text-to-SQL ist die Ausgabe eine erklärbare No-Code-Exploration, die direkt mit der Datenplattform interagiert und leicht editierbar ist.
Video: Supersimple
Die komplexe Ausgabe wird in einzelne Blöcke zerlegt, die logische Schritte im Denkprozess darstellen. Die Komplexität der Erstellung korrekter SQL-Abfragen wird auf die Plattform verlagert. Bei der Generierung der Ausgabe berücksichtigen die Modelle auch bestehende Dashboards und benutzerdefinierte Konzepte.
GPT-4 Feintuning skaliert weniger als bei GPT-3.5
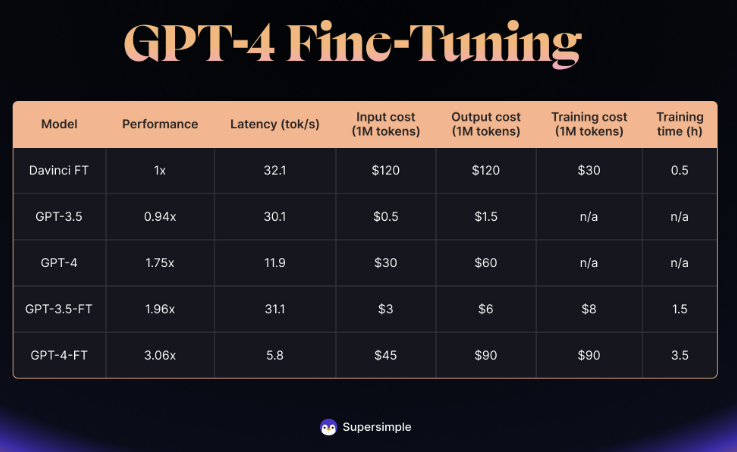
Ein Vergleich verschiedener OpenAI-basierter Modelle zeigt, dass ein fein abgestimmtes GPT-4 zwar die Leistung von GPT-3.5 um 56 Prozent übertrifft. Der Leistungssprung war jedoch geringer als beim Wechsel von GPT-3 zu GPT-3.5. Dennoch übertrifft das fein abgestimmte GPT-4 das herkömmliche GPT-4 und GPT-3.5 deutlich.

In einem internen Benchmark-Test mit 100 verschiedenen Fragen zeigte das verbesserte GPT-4 trotz Leistungsverbesserungen laut Supersimple weiterhin Schwächen bei breiten und offenen Fragen, wenn diese mit einer einzigen Antwort gelöst werden sollten.
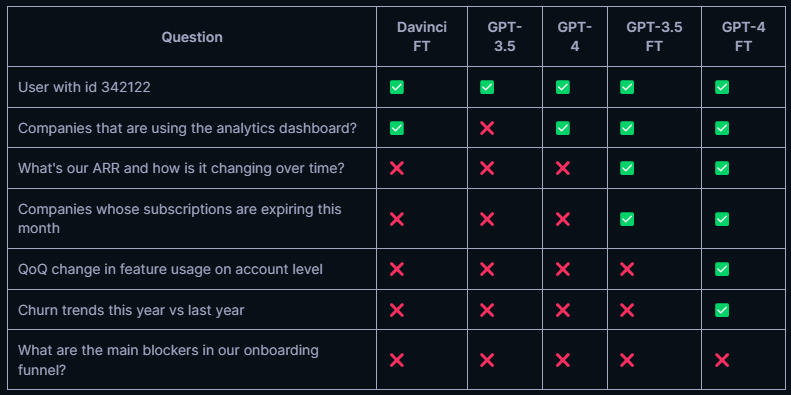
"Besorgniserregend ist der Trend, dass die Vorteile der Feinabstimmung abnehmen. Während das Feintuning von Davinci eine deutliche Verbesserung gegenüber dem Basismodell darstellt, bietet das Feintuning von GPT-3.5 weniger Vorteile und der Fortschritt durch das Feintuning von GPT-4 ist noch geringer", schreibt die Firma.
Die Hauptprobleme des feinabgestimmten GPT-4 sind laut Supersimple die deutlich höhere Latenz, die sechsmal höher ist als bei GPT-3.5, und die Kosten, die 15-mal höher für Inferenz und 11-mal höher für Training sind als bei GPT-3.5.
Um diese Einschränkungen zu umgehen, verlässt sich Supersimple im Produktivbetrieb selten auf einen einzigen Modellaufruf. Stattdessen wird eine Mischung aus verschiedenen spezialisierten Modellen, Prompts und Heuristiken verwendet, um sowohl die Genauigkeit als auch die Antwortzeit zu verbessern.
Auch aufgrund der hohen Latenz verwendet Supersimple GPT-4 nur für eine bestimmte Untermenge von Fragen und für einige der kritischsten Denkschritte. Für den Rest werden andere Modelle wie GPT-3.5 verwendet.
Für viele reale Anwendungen, die nicht-triviale Fähigkeiten des logischen Denkens erfordern, sei ein einziges Modell mit einer einzigen Antwort nicht ausreichend. Darüber hinaus sei es wichtig, dass eine KI ihr Ergebnis dem Benutzer genau erklärt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.