Cerebras Super-Chip: KI-Performance könnte explodieren
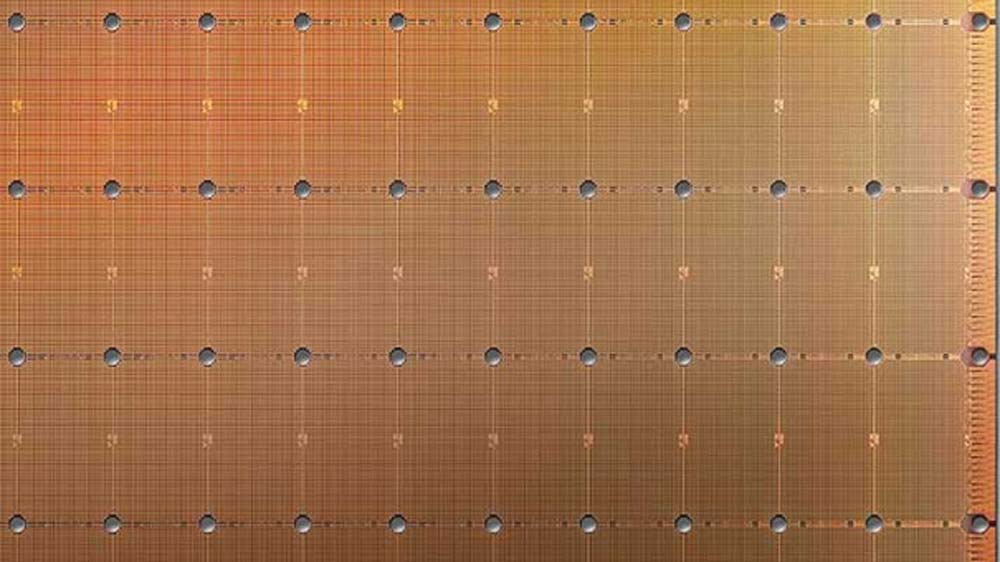
KI-Training braucht viel parallelisierte Rechenleistung. Nvidia baut dafür GPUs, Google nutzt spezielles TPUs. Cerebras geht einen anderen Weg: Das Unternehmen stellt einen riesigen Chip mit 1.2 Billionen Transistoren her, der 10.000 Mal schneller ist als eine GPU.
Egal ob CPU, GPU oder TPU, der Herstellungsprozess der unterschiedlichen Computerchips ist im Prinzip identisch: Die Hersteller lösen eine etwa ein Millimeter dünne Schicht von einem Siliziumblock („Wafer“). Anschließend wird der Wafer mit Chips der gewünschten Architektur versehen und in hunderte einzelne Stücke geteilt. Die einzelnen Chips kommen dann etwa in Grafikkarten oder als Prozessoren zum Einsatz.
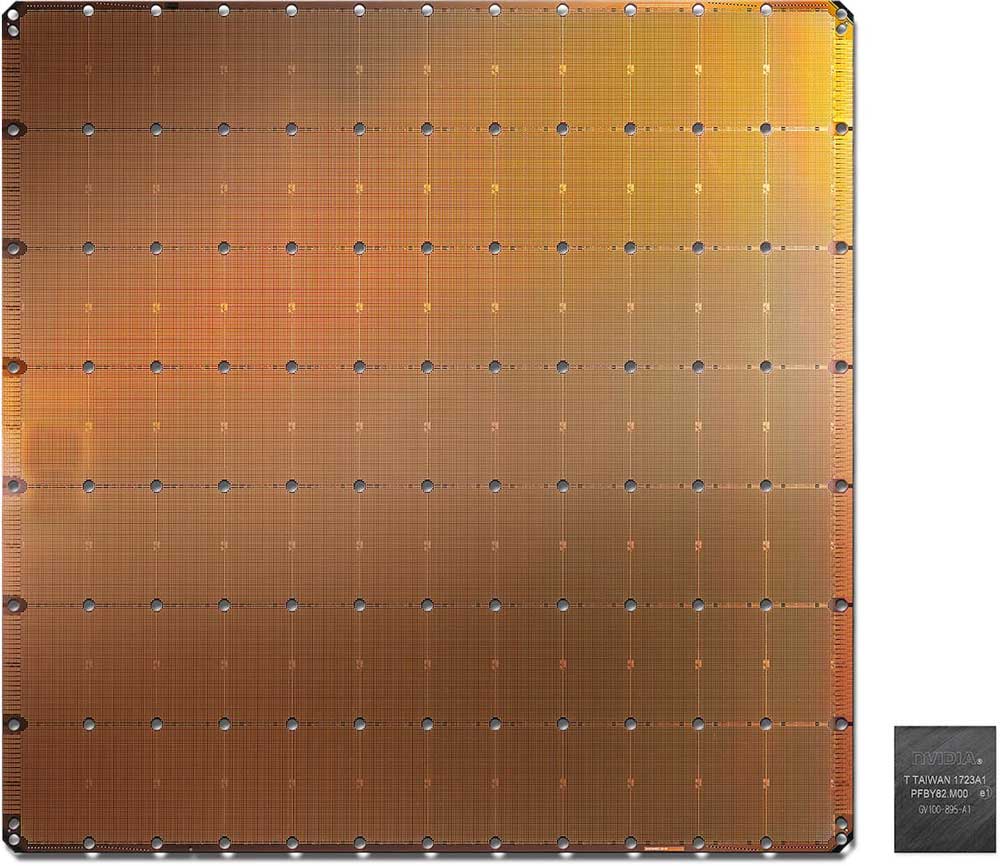
Das 275 Personen starke Team von Cerebras Systems geht einen anderen Weg: Die Chipexperten verwandeln den gesamten Wafer in einen zwei Millionen US-Dollar teuren und riesigen Computerchip – „Wafer Scale Engine“ (WSE) genannt. Der 2019 erstmals vorgestellte Chip ist 56 Mal größer als eine klassische GPU und kommt mit 400.000 miteinander verknüpften und für KI-Anwendungen optimierten Prozessorkernen.
Alte Ideen und technische Probleme
Die Idee, aus einem Wafer direkt einen großen statt vieler kleiner Chips zu bauen, kam in den 1970ern auf („Wafer-scale integration“). Doch technische Hürden hinderten Unternehmen wie Trilogy Systems daran, den Plan umzusetzen.
Die drei größten Hindernisse sind:
- Alle Kerne müssen miteinander kommunizieren können,
- bei der Herstellung entstehen fehlerhafte Kerne,
- und die unterschiedlichen Materialeigenschaften von Silizium-Wafer und aufgetragenen Schaltkreisen führen durch die im Recheneinsatz entstehenden Hitze zu Schäden an der Architektur.
Cerebras hat diese Probleme gelöst. Die Kerne werden im Herstellungsprozess über ein redundantes Netzwerk verbunden, das gleichzeitig zwei Hindernisse beseitigt: Die Kommunikation zwischen den Kernen ist sichergestellt und die Funktion eventuell beschädigter Kerne kann von anderen Kernen übernommen werden. Dafür plant Cerebras 1 bis 1,5 Prozent zusätzliche Kerne ein, die im Notfall einspringen. Fortschritte in der Fertigungstechnik seit den 1980ern sorgen außerdem für insgesamt weniger fehlerhafte Kerne.
Die Hitzeproblematik löst Cerebras mit einer verbindenden Schicht zwischen Kernen und Wafer. Unter Belastung breiten sich Kerne und Wafer auf Grund der Materialeigenschaften zwar weiter unterschiedlich aus, doch das verbindende Material gleicht die Unterschiede so aus, dass es zu keiner Beschädigung der Verbindungen und Transistoren kommt.
CS-1 Supercomputer: Ein leistungsstarker Winzling
Dank der technologischen Fortschritte passen auf den WSE-Chip so 1,2 Billionen Transistoren. Zum Vergleich: Der A100-Chip, Nvidias Spitzenmodell, hat lediglich 54 Milliarden Transistoren. Der mit TSMCs 16nm-Prozess gefertigte Chip kommt außerdem mit 18 Gigabyte On-Chip-Speicher und einer Speicherbandbreite von neun Petabyte pro Sekunde. Nvidias A100 setzt dagegen auf klassischen, separaten Grafikkartenspeicher und bietet eine Bandbreite von lediglich zwei Terabyte pro Sekunde.
Cerebras integriert den WSE-Chip im eigenen Cerebras CS-1 Supercomputer, der die Rechenleistung eines GPU-basierten Supercomputers mit etwa 1.000 Nvidia Tesla V100-Grafikkarten erreicht, so der Hersteller.
Da der einzelne WSE-Chip wesentlich weniger Platz einnimmt, ist der CS-1-Computer ein vergleichsweise kompaktes Gerät, das etwa in einem Drittel eines klassischen Serverracks Platz findet. Während ein GPU-Supercomputer über Monate aufgebaut wird, dutzende Serverracks belegen kann und 650 Kilowatt frisst, ist der CS-1 in einer Stunde einsatzbereit und benötigt lediglich 20 Kilowatt.
Cerebras bietet mit dem „Cerebras Graph Compiler“ außerdem eine automatisierte Lösung für KI-Forscher an. Der Compiler überträgt klassische KI-Modelle aus Frameworks wie PyTorch oder Tensorflow in die eigene Cerebras Software.
CS-1 schlägt HPC-Computer „Joule“
Auch beim Hochleistungsrechnen zeigt Cerebras WSE-Chip, was er kann: In einem Test schlug der CS-1 mit dem zwei Millionen US-Dollar teuren WSE-Chip den Joule Supercomputer, der auf Platz 82 der 500 schnellsten Supercomputer der Welt rangiert. Der Joule Supercomputer kostet dutzende Millionen US-Dollar, belegt dutzende Serverracks, hat 84.000 CPU-Kerne und frisst 450 Kilowatt.

Getestet wurden die beiden Computer mit Aufgaben der numerischen Strömungsmechanik. Der Joule-Computer nutzte die für diese Aufgabe maximal mögliche Anzahl von 16.384 Kerne. Weitere Kerne hätte seine Performance nicht erhöht. In dem Test war der CS-1 ganze 200 Mal schneller als der Joule-Computer und 10.000 Mal schneller als eine einzelne GPU. Das Training neuronaler Netze lässt sich also um ein Vielfaches Beschleunigen.
„Für diese Workloads ist der CS-1 der schnellste Computer, der jemals gebaut wurde“, sagte Cerebras-Gründer Andrew Feldman.
Eine Forschungsarbeit des Nationalen Labors für Energietechnologie des US-Bundesamts für Energie und Cerebras kommt sogar zu dem Schluss, dass CS-1 eine Leistung liefert, die mit jeder beliebigen Anzahl von CPUs oder GPUs unerreichbar ist. Es ist außerdem das erste System, das in der Lage ist, die Strömungsmechaniken schneller als in Echtzeit zu simulieren.
Einschränkungen und „Neocortex“
Cerebras Ansatz hat allerdings einen Nachteil: Die 18 Gigabyte On-Board-Speicher sind weit entfernt von den 80 Gigabyte Speicher, die Nvidias A100-System liefert. Große Speichermengen sind besonders für große KI-Modelle nützlich, wie etwa die riesige Sprach-KI GPT-3, die Schätzungen zufolge über 350 Gigabyte Speicher benötigt.
Die Forscher erwarten allerdings mit der Verkleinerung des Fertigungsprozesses auch mehr Speicher: 7nm könnten etwa 40 Gigabyte Speicher und 5nm-Fertigung etwa 50 Gigabyte ermöglichen. Andere Änderungen wie mehrere verbundene Wafer oder verschiedene Wafer-Typen könnten das Speicherproblem lösen, schreiben die Autoren.
Ein erstes Beispiel für den Verbund zweier WSE-Chips gibt es bereits: Das Pittsburgh Supercomputing Center (SPC) der Carnegie Mellon Universität und der Universität Pittsburgh baut den aus zwei CS-1-Computern bestehenden KI-Supercomputer Neocortex. Neocortex verbindet die zwei CS-1-Systeme mit einem HPE Superdome Flex Server mit knapp 26 Terabyte Speicher und 32 6,4 Terabyte NVMe SSDs.
Die Forscher versprechen sich vom System erheblich verkürzte Trainingszeiten für das Deep Learning und somit eine bessere Zugänglichkeit zu Rechenleistung: Neocortex erlaube der Forschungsgemeinschaft Zugriff auf massive Rechenleistung, die sonst nur großen Tech-Konzernen zur Verfügung stehe, heißt es auf der Webseite des Projekts.
Cerebras Super-Chip ist wohl erst der Anfang
Die Halbleiterindustrie steht vor einem grundsätzlichen Problem: Es wird immer schwieriger, Transistoren durch verfeinerte Leiterstrukturen und verbesserte Prozessknoten bessere Leistung abzuringen. Zwar startete in diesem Jahr der 5nm-Fertigungsprozess und für die nächsten Jahre werden 3nm und 2nm erwartet – doch dann braucht es wohl völlig neue Fertigungsmethoden für weiteren Fortschritt.
Unternehmen wie AMD versuchen daher mit verbesserter Kommunikation zwischen einzelnen Komponenten innerhalb des Chips und zwischen mehreren Chips mehr Leistung zu gewinnen – vor allem für die Cloud. Erst kürzlich zeigte AMD seine Pläne für die Infinity Architecture, eine Fortführung der Infinity Fabric von 2017.
Für viele dieser Unternehmen könnten größere, stärker verbundene Chip-Designs daher der nächste logische Schritt im Cloud-Computing sein – wenn die Fertigungskapazitäten zur Verfügung stehen.
Hergestellt wird Cerebras WSE-Chip vom Tech-Giganten Taiwan Semiconductor Manufacturing Company (TSMC). Das 1987 gegründete Unternehmen ist einer der fünf führenden Halbleiterhersteller und bedient Kunden wie Nvidia, AMD, Apple oder Qualcomm. Vor dem Eingreifen der USA produzierte TSMC außerdem einen Großteil der Huawei-Chips.
Wie DigiTimes berichtet, will TSMC die für den WSE-Chip eingesetzte Technologie als InFO-SoW (integrated fan-out system-on-wafer) in den nächsten zwei Jahren kommerzialisieren und damit die Architekturen von Supercomputer-Chips anderer Unternehmen für KI- und HPC-Anwendungen fertigen.
Das könnte die weltweit in der Cloud verfügbare Rechenleistung schnell und verhältnismäßig günstig vervielfachen und die Erforschung, Entwicklung und Ausführung von KI-Anwendungen drastisch beschleunigen. Ähnliche Auswirkungen auf Cloud-Anwendungen wie virtuelle Computer oder das Game-Streaming sind ebenfalls zu erwarten.
Ein erster Gewinner von TSMCs Investment in die Fertigungstechnologie für Wafer-Chips steht bereits fest: Cerebras kündigte auf der „Hot Chips 2020“-Konferenz „Wafer Scale Engine 2“ an. Der neue Chip setzt dank TSMCs Fortschritten seit 2019 auf den 7nm-Prozess und kommt bei gleicher Wafer-Größe (300mm) auf 850.000 für Künstliche Inteligenz optimierte Kerne und insgesamt 2,6 Billionen Transistoren. Laut Cerebras wird er aktuell intern getestet, Informationen zur Leistung, internem Speicher oder Energiebedarf gibt es noch nicht.
Titelbild: Cerebras | Via: HPCWire, AIBusiness
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.