Mistral veröffentlicht drei neue LLMs für Mathe, Code und generelle Aufgaben
Mistral AI hat diese Woche mehrere Sprachmodelle veröffentlicht, die neue Maßstäbe bei generellen Anfragen sowie in den spezialisierten Anwendungsbereichen mathematisches Denken und Codegenerierung setzen sollen.
Mathstral mit 7 Milliarden Parametern für mathematische Aufgaben
Mathstral ist ein Modell mit 7 Milliarden Parametern, das das französische Start-up in Zusammenarbeit mit Project Numina, einer gemeinnützigen Organisation "zur Entwicklung der menschlichen und Künstlichen Intelligenz im Bereich der Mathematik", entwickelt hat.
Es zeigt Spitzenleistungen sowohl in Mathematik-Benchmarks wie MATH (56,6 %) und allgemeineren Benchmarks wie MMLU (63,47 %). Im Vergleich mit ähnlich großen, teilweise ebenfalls spezialisierten Modellen wie DeepSeek-Math-7B, LLaMA-3-8B, Qwen2-7B oder Gemma-2-9B schneidet es in den meisten Benchmarks teilweise deutlich besser ab.
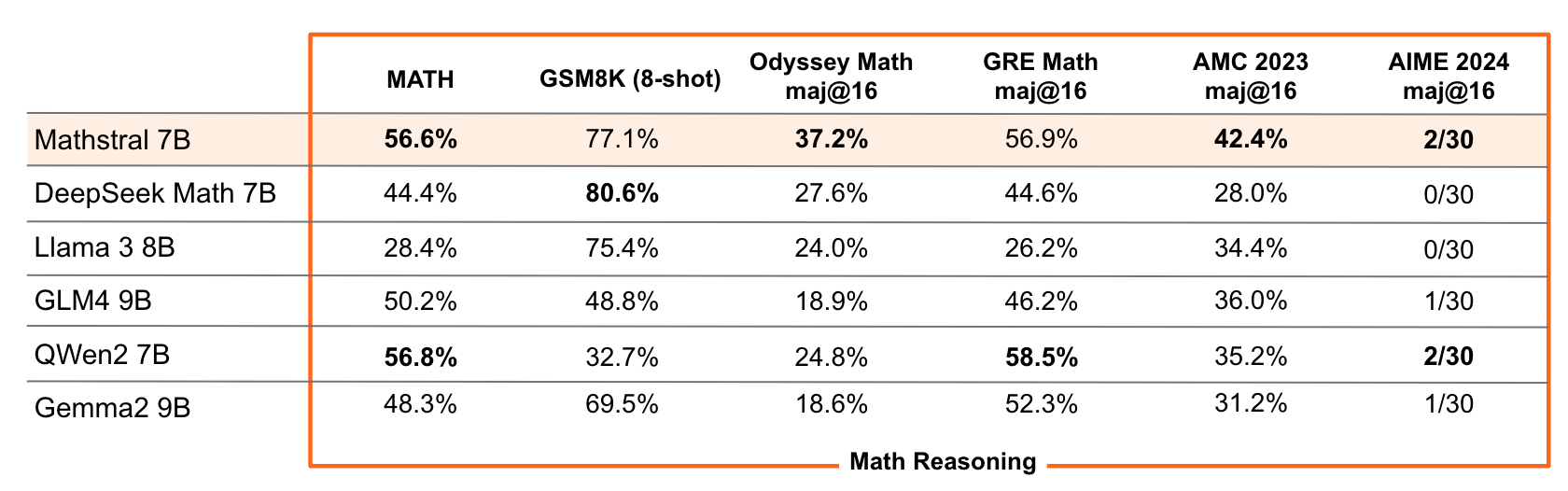
"Mathstral ist ein weiteres Beispiel für das hervorragende Verhältnis zwischen Leistung und Geschwindigkeit, das bei der Erstellung von Modellen für bestimmte Zwecke erzielt wird - eine Entwicklungsphilosophie, die wir in 'la Plateforme' [Anm.: Mistrals Cloud-Plattform] aktiv fördern, insbesondere mit den neuen Feinabstimmungsfunktionen", so das Team im neusten Blogeintrag.
Codestral Mamba: Neue Architektur und größeres Kontextfenster
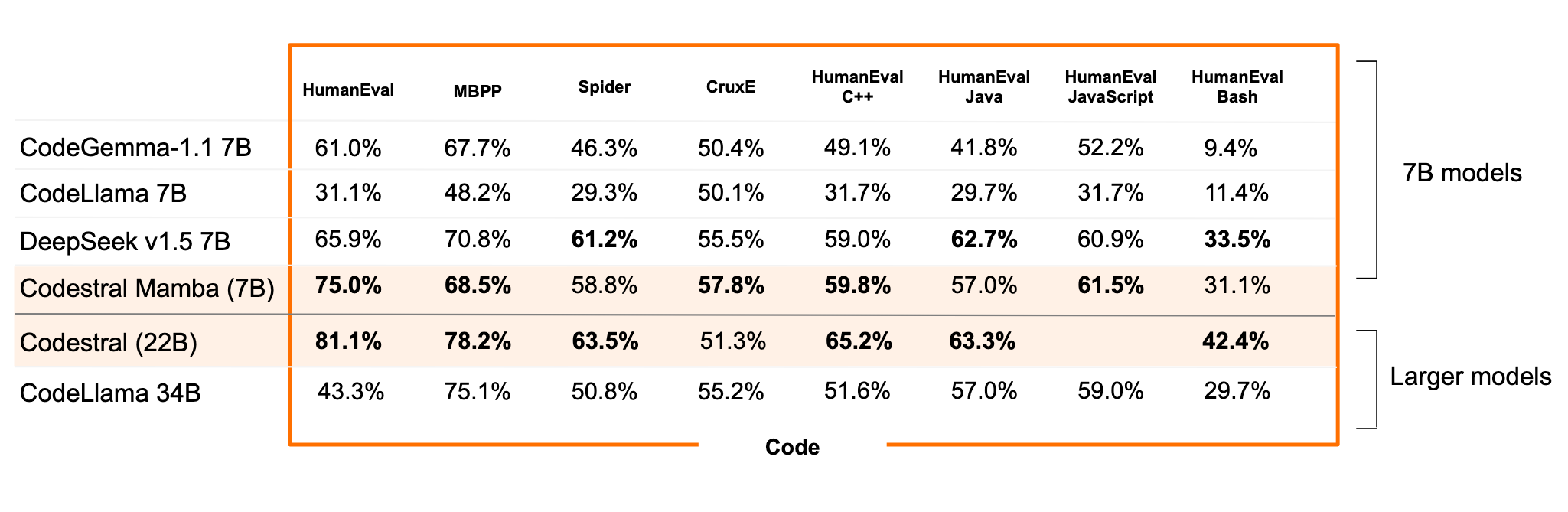
Mit Codestral hatte Mistral bereits im Mai 2024 ein Code-Modell mit 22 Milliarden Parametern auf den Markt gebracht. Es unterstützt über 80 Programmiersprachen und bot ein Kontextfenster von 32.000 Token, womit es alle anderen getesteten Modelle in Benchmarks übertraf.
Jetzt folgt ein neues Modell mit weniger Parametern, jedoch anderer Architektur. Wie der Name schon verrät, basiert Codestral Mamba auf der Mamba2-Architektur und verspricht dadurch schnelle Codegenerierung mit langen Kontextfenstern von bis zu 256.000 Token.
Damit eigne es sich hervorragend als lokaler Code-Assistent, da sich etwa die eigene Codebasis und Dokumentationen von Programmier-Frameworks in einen einzigen Prompt einspeisen lassen. Die jüngere, aber vielversprechende Mamba-Architektur verarbeitet Sequenzen in linearer Zeit, was schnellere Reaktionen und Ausgaben in theoretisch unendlicher Länge ermöglicht.
In Benchmarks brachte es Codestral Mamba zumindest im Vergleich mit ähnlich großen Modellen häufig auf den ersten Platz, das größere Codestral auf Transformer-Basis hat allerdings noch die Nase vorn.
Technische Dokumentationen, die mehr Einblicke in das Trainingsmaterial und den Aufbau der Modelle geben, hat Mistral bislang leider nicht veröffentlicht. Die Gewichte sind allerdings auf Hugging Face (Mathstral, Codestral Mamba) verfügbar.
Mistral NeMo: Neues Mini-Modell mit 12 Milliarden Parametern
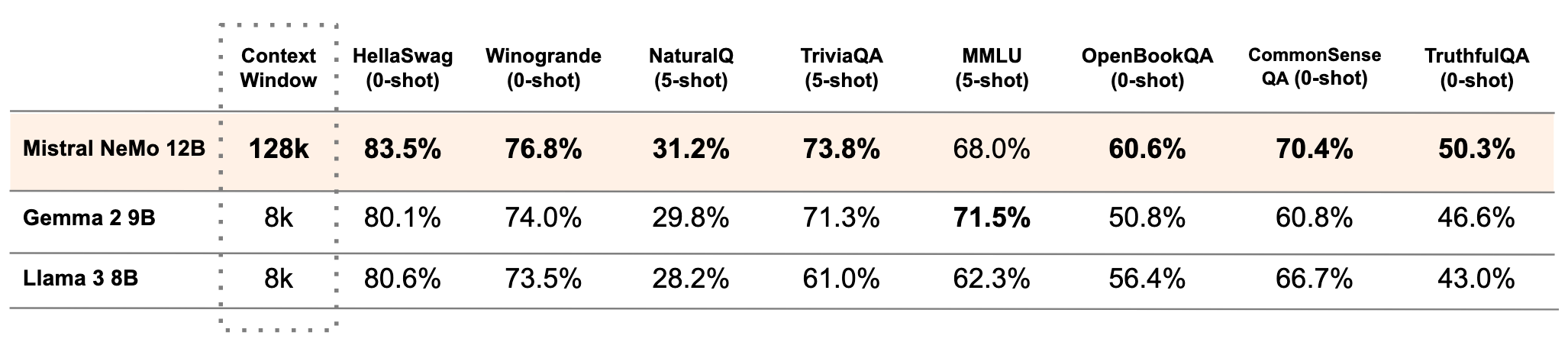
In Zusammenarbeit mit NVIDIA wurde das neue Sprachmodell Mistral NeMo entwickelt, das mit zwölf Milliarden Parametern und einem Kontextfenster von bis zu 128.000 Tokens aufwartet.
Das Modell zeichnet sich dem Unternehmen zufolge durch seine Leistungsfähigkeit in den Bereichen Logik, Weltwissen und Codingfähigkeiten aus und soll besonders für globale, mehrsprachige Anwendungen geeignet sein.
Mistral NeMo basiert auf einer Standardarchitektur und könne daher leicht in bestehende Systeme integriert werden. Im Vergleich zu anderen Open-Source-Modellen wie Gemma-2-9B und LLaMA-3-8B zeigt das NeMo-Basismodell in Benchmarks ähnliche oder bessere Ergebnisse, unterstützt dabei jedoch sogar ein 16-mal so großes Kontextfenster.
Das Modell wurde mit einem neuen Tokenizer namens Tekken trainiert, der auf über 100 Sprachen optimiert ist und eine stärkere Komprimierung von natürlichem Text und Quellcode ermöglicht als der zuvor verwendete SentencePiece-Tokenizer.
Im Vergleich sei er rund 30 Prozent effizienter bei der Tokenisierung von Code, Chinesisch, Italienisch, Französisch, Spanisch und Russisch. Gegenüber dem Tokenizer von LLaMA 3 biete Tekken für 85 Prozent der Sprachen eine effizientere Komprimierung.
Mistral NeMo ist besonders leistungsstark in Sprachen wie Englisch, Französisch, Deutsch, Spanisch, Italienisch, Portugiesisch, Chinesisch, Japanisch, Koreanisch, Arabisch und Hindi. Die vortrainierten Basis- und anweisungsoptimierten Checkpoints hat Mistral unter der Apache 2.0-Lizenz veröffentlicht, um die Akzeptanz bei Forschenden und Unternehmen zu fördern. Mistral NeMo scheint in die Fußstapfen von Mistral-7B zu treten, das erst im Mai ein Update erhalten hatte.
Mistral bleibt das führende europäische LLM-Start-up
Mistral hat dieses Jahr sein Flaggschiffmodell namens Mistral Large vorgestellt, das es als Konkurrenz zu OpenAIs GPT-4 positioniert. Im Februar schloss Microsoft eine mehrjährige Partnerschaft mit Mistral AI, wodurch es unter anderem Zugang zu Microsofts Azure AI Supercomputing-Infrastruktur erhält. Im Juni folgte der Abschluss einer weiteren Finanzierungsrunde in Höhe von 600 Millionen US-Dollar, womit Mistral zu den wertvollsten KI-Unternehmen Europas befördert wurde.
Insgesamt positioniert sich Mistral AI als eins der führenden europäischen KI-Unternehmen, mit dem Ziel, leistungsstarke und spezialisierte Sprachmodelle zu entwickeln, die auch Aspekte wie Transparenz und Datenschutz nach europäischen Standards berücksichtigen.
In Europa gibt es im LLM-Bereich noch Aleph Alpha, das auf Modellebene bislang nicht mit Mistral gleichziehen konnte oder wollte, DeepL, das mit 300 Millionen im Rücken KI-Sprachlösungen für Unternehmen ausbauen will und das kürzlich von AMD aufgekaufte Silo AI.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.