MiniMax stellt KI-Modelle mit Rekord-Kontextlänge vor

Das chinesische Start-up MiniMax hat die Open-Source-Modellfamilie MiniMax-01 veröffentlicht. Das Sprachmodell MiniMax-Text-01 verarbeitet laut Hersteller Kontexte von bis zu 4 Millionen Token - doppelt so viel wie der bisherige Spitzenreiter.
Zur neu eingeführten Serie gehören das textbasierte Modell MiniMax-Text-01 und das multimodale Modell MiniMax-VL-01, das auch visuelle Informationen verarbeiten kann. Die enorme Kontextlänge soll es ermöglichen, KI-Agenten mit einer Art "Langzeitgedächtnis" auszustatten, die Informationen aus vielen Quellen aufnehmen, miteinander verknüpfen und für späteren Abruf speichern können.
"Lightning Attention" steigert Effizienz
Um derart lange Kontexte effizient verarbeiten zu können, setzt MiniMax auf eine hybride Architektur. Diese kombiniert den in 2023 vorgestellten und 2024 weiterentwickelten "Lightning Attention"-Mechanismus mit klassischen Transformer-Blöcken in einem Verhältnis von 7:1. Diese Kombination reduziere den Rechenaufwand bei sehr langen Eingaben deutlich, während die Vorteile der Transformer-Architektur erhalten blieben, so das Team.
Ein weiterer Schlüssel zur effizienten Verarbeitung ist die bekannte "Mixture of Experts"-(MoE)-Struktur. Dabei handelt es sich um eine Schicht mit mehreren spezialisierten Teilmodellen, die für unterschiedliche Aufgaben optimiert sind.
Je nach Eingabe werden die am besten geeigneten Experten ausgewählt und kombiniert. MiniMax-Text-01 verfügt über 32 solcher Experten mit jeweils 45,9 Milliarden Parametern. Demnach verfügt das Modell über insgesamt knapp 456 Milliarden Parameter.
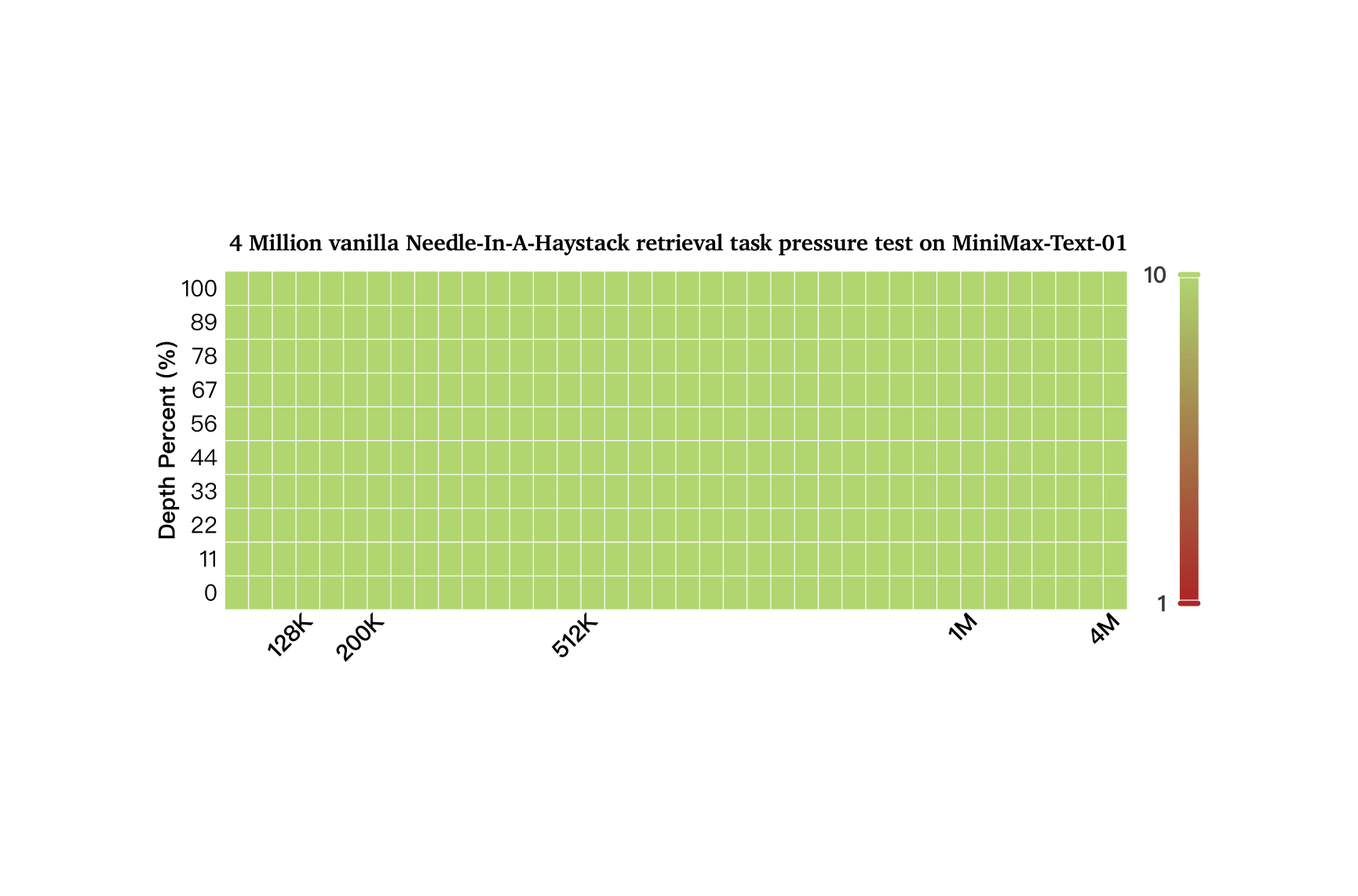
Needle im 4-Millionen-Token-Haystack gefunden
Um die Leistungsfähigkeit seiner Modelle zu untermauern, hat MiniMax eine Reihe von Benchmarks veröffentlicht. Diese zeigen: MiniMax-01 kann in gängigen Tests mit kommerziellen Spitzenmodellen wie GPT-4o und Claude 3.5 Sonnet mithalten.
Besonders gut schneidet es bei Aufgaben mit sehr langen Kontexten ab: Beim "Needle-In-A-Haystack"-Test mit 4 Millionen Token, bei dem das Sprachmodell bestimmte Informationen aus einer riesigen Datenmenge extrahieren muss, erreichte MiniMax-Text-01 laut Hersteller eine Genauigkeit von 100 Prozent.
Ein ebenfalls optimales Ergebnis erzielte allerdings schon Googles Gemini 1.5 Pro, das vor rund einem Jahr mit einem 2 Millionen Token großen Kontextfenster eingeführt wurde. Genauere Untersuchungen brachten hervor, dass der Benchmark nicht sonderlich viel Aussagekraft hat. Gleichzeitig haben Untersuchungen gezeigt, dass überdimensionale Kontextfenster nicht zwangsweise Vorteile gegenüber kleineren Kontexten in Kombination mit einer RAG-Umgebung bieten.
Modelle als Open Source verfügbar
Die MiniMax-01-Modelle stehen auf GitHub und Hugging Face zum Download bereit. Interessierte können sie im hauseigenen Chatbot Hailuo AI ausprobieren oder über eine vergleichsweise kostengünstige API in eigene Anwendungen integrieren.
MiniMax hat zuletzt im Herbst 2024 mit seinem Videogenerator Video-01 für Aufsehen gesorgt. Das Ende 2021 gegründete KI-Start-up mit Sitz in Shanghai wird unter anderem von dem E-Commerce-Riesen Alibaba finanziert, das mit Qwen eine eigene Modellfamilie entwickelt.
Als Konkurrenz betrachtet MiniMax außerdem das Unternehmen DeepSeek, das mit dem kürzlich veröffentlichten Open-Source-Sprachmodell DeepSeek-V3 in eine ähnliche Richtung geht. Jedoch dürfte MiniMax-01 wie DeepSeeks Modell unter Zensur der chinesischen Regierung leiden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.