Studie deckt Schwächen von KI-Sprachmodellen beim Schlussfolgern in langen Kontexten auf

Aktuelle KI-Sprachmodelle stoßen an ihre Grenzen, wenn es darum geht, in langen Texten die richtigen Informationen zu verknüpfen und Schlüsse zu ziehen. Auch Reasoning-Modelle haben dahingehend nur überschaubare Fähigkeiten.
Das ist das Ergebnis einer neuen Studie von Forschenden der LMU München, dem Munic Center for Machine Learning und von Adobe Research. Die Wissenschaftler:innen haben 12 State-of-the-Art-Sprachmodelle getestet, darunter GPT-4o, Gemini 1.5 Pro und Llama-3.3-70B, die alle Kontextlängen von mindestens 128.000 Token unterstützen.
Benchmark minimiert wörtliche Übereinstimmungen
Der Benchmark NOLIMA (No Literal Matching) testet die Fähigkeit von Sprachmodellen, Informationen in langen Texten zu verknüpfen und Schlüsse zu ziehen, ohne sich auf wörtliche Übereinstimmungen zu verlassen. Dafür werden Fragen und relevante Textstellen (Nadeln) so formuliert, dass sie keine gemeinsamen Wörter enthalten. Das Modell muss den Text verstehen und assoziative Verbindungen zwischen Begriffen herstellen.
Konkret: Eine Nadel könnte den Satz enthalten: "Tatsächlich wohnt Yuki neben der Semperoper." Die dazugehörige Frage lautet: "Welche Figur war schon in Dresden?" Das Modell muss die Verbindung zwischen "Semperoper" und "Dresden" kennen, um "Yuki" als richtige Antwort zu identifizieren.
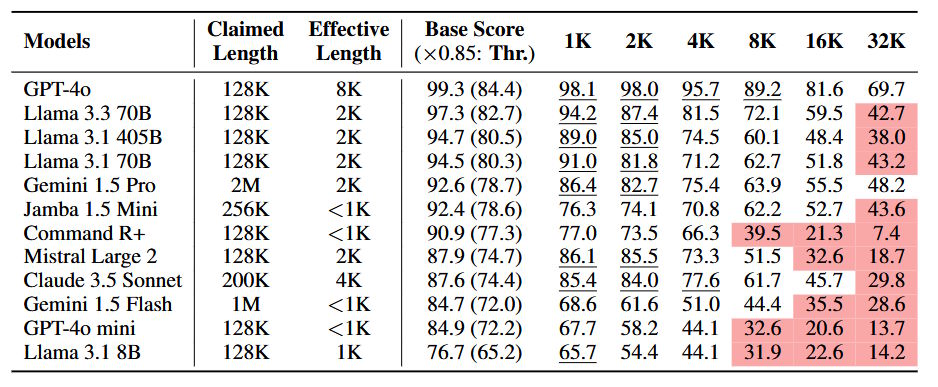
Die Ergebnisse zeigen deutliche Leistungseinbußen der Modelle bei zunehmender Kontextlänge. Bereits bei 2.000 bis 8.000 Token waren erhebliche Rückgänge zu verzeichnen. Bei 32.000 Token erreichten 10 von 12 Modellen nur noch die Hälfte ihrer Leistung im Vergleich zu kurzen Kontexten.
Auch Reasoning hilft nicht
Die Forschenden führen dies auf die Grenzen des bei solchen Transformer-Modellen grundlegenden Aufmerksamkeitsmechanismus zurück, der in langen Kontexten überlastet werde. Fehlen wörtliche Hinweise, falle es den Modellen schwer, relevante Informationen zu finden und zu verknüpfen.
Je mehr Denkschritte, sogenannte Latent Hops, nötig sind, desto stärker sei außerdem der Leistungsabfall. Auch die Reihenfolge der Informationen sei entscheidend: Steht der relevante Name (die Antwort) erst nach dem Schlüsselwort, sinkt die Leistung.
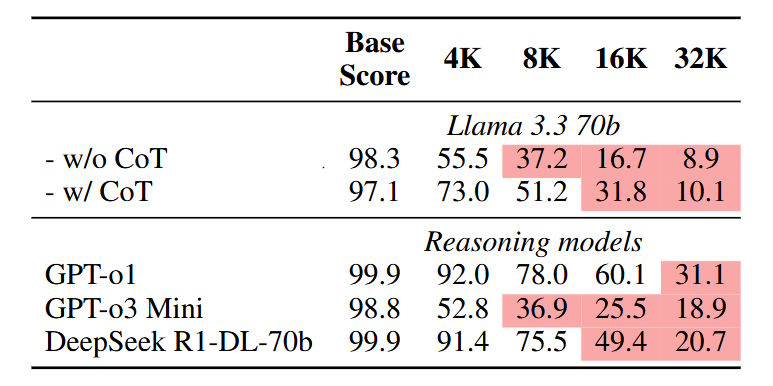
Zusätzlich haben die Forschenden ein Subset namens NOLIMA-Hard erstellt, um speziell Reasoning-Modelle zu testen. Dieses Subset enthält die zehn schwierigsten Frage-Antwort-Paare aus NOLIMA. Selbst spezialisierte Reasoning-Modelle wie o1, o3-mini und DeepSeek-R1 erreichen bei Kontextlängen von 32.000 Token nur eine Genauigkeit von unter 50 Prozent, obwohl sie bei kürzeren Kontexten nahezu perfekt abschneiden.
Chain-of-Thought-Prompting (CoT) verbessert die Leistung von Llama-3.3-70B in langen Kontexten, kann den starken Leistungsabfall aber nicht vollständig kompensieren. Wörtliche Übereinstimmungen im Text vereinfachen die Aufgabe zwar, führen aber zu starken Leistungseinbrüchen, wenn sie als Ablenkung in einem irrelevanten Kontext auftauchen. Somit bleiben selbst für spezialisierte Reasoning-Modelle und CoT-Prompting die Herausforderungen in Bezug auf lange Kontexte bestehen.
Die Studie unterstreicht somit eine grundlegende Schwäche aktueller KI-Sprachmodelle. Die Ergebnisse zeigen in den Augen der Forschenden, dass die Systeme stark auf oberflächliche Signale angewiesen sind. Fehlen diese, geraten sie schnell an ihre Grenzen.
Das könnte laut den Forscher:innen unmittelbare Auswirkungen auf praktische Anwendungen haben. Beispielsweise in Suchmaschinen, die auf der RAG-Architektur aufbauen. Hier werden Informationen portionsweise in Vektordatenbanken gespeichert und sollen so dem Bedarf an großen Kontextfenstern eigentlich entgegenwirken.
Auch wenn ein Dokument mit der korrekten Antwort gefunden wird, könnte das Sprachmodell Schwierigkeiten haben, diese zu extrahieren, wenn der Kontext keine wörtlichen Übereinstimmungen mit der Suchanfrage aufweist. Stattdessen würde es sich von oberflächlichen Signalen in irrelevanten Dokumenten ablenken lassen.
NOLIMA als neuer Kontextfenster-Messwert?
Während es in den letzten Monaten nur wenige fundamentale Durchbrüche bei der Entwicklung großer Foundation-Modelle gab, haben sich kommerzielle Anbieter einerseits auf Reasoning-Logiken, andererseits auf größere Kontextfenster konzentriert. Momentan führt Gemini 1.5 Pro das Feld mit einer maximalen Eingabe von zwei Millionen Token an.
Bei der rasanten Erweiterung der Kontextfenster - GPT-3.5 unterstützte anfangs etwa nur 4.096 Token, GPT-4 immerhin 8.000 - hatten große Sprachmodelle zunächst selbst mit dem Extrahieren von Wortsequenzen Schwierigkeiten. Bald zeigten sie jedoch immer bessere Performance bei den durch Hersteller veröffentlichten Ergebnissen des Needle-in-a-Haystack-Benchmarks. Hier wird getestet, wie genau Sprachmodelle einzelne oder mehrere Wörter in einem großen Kontextfenster wiederfinden.
NOLIMA könnte sich jetzt als ein neuer Messwert etablieren, der die tatsächliche Fähigkeit bewertet, mit großen Kontextfenstern effektiv umzugehen, und die LLM-Entwicklung langfristig verbessern. Allerdings hatten auch schon frühere Studien angemerkt, dass dabei noch großes Verbesserungspotenzial besteht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.