OpenAI behauptet KI-Durchbruch bei komplexen mathematischen Problemen
Update –
- Aussagen eines weiteren OpenAI-Forschers ergänzt
Update vom 20. Juli 2025:
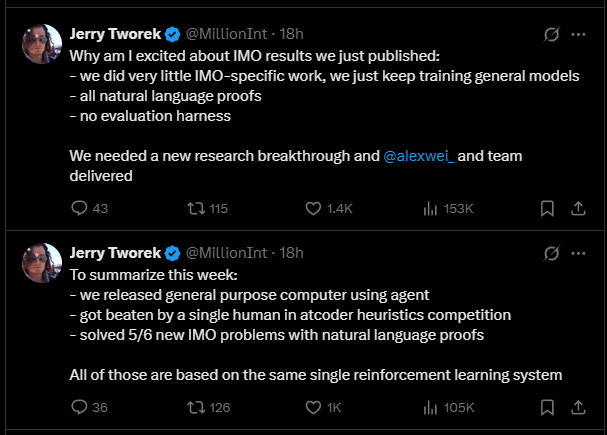
OpenAI-Forscher Jerry Tworek bestätigt bei X, dass für das unten genannte Modell "sehr wenig" IMO-spezifische Anpassungen vorgenommen wurden. Stattdessen habe man lediglich die bestehenden allgemeinen Modelle weitertrainiert.
Alle Lösungen basierten auf natürlichen Sprachbeweisen, ein spezieller Bewertungsrahmen sei nicht verwendet worden. Tworek hebt hervor, dass ein echter Durchbruch in der Forschung nötig war – und das Team um Alexander Wei diesen geliefert habe. Eine Veröffentlichung des Modells sei wahrscheinlich Ende des Jahres möglich.
Laut Tworek sind alle großen OpenAI-Ankündigungen dieser Woche – die Veröffentlichung eines allgemeinen KI-Agentensystems, eine knappe Niederlage gegen einen einzelnen Menschen bei einem heuristischen Programmierwettbewerb und das Lösen von 5 von 6 IMO-Aufgaben mit natürlichen Sprachbeweisen – auf dasselbe Reinforcement-Learning-System zurückzuführen. Der ChatGPT-Agent nutze einen früheren Stand der Technik, basierend auf einem älteren Basismodell.
Unterdessen kursieren Gerüchte, dass auch Deepmind bei der IMO 2025 eine Goldmedaille gewonnen haben könnte. Eine offizielle Bestätigung seitens des Unternehmens steht bislang aus. Im Vorjahr hatten Deepminds Systeme AlphaProof und AlphaGeometry mit vier gelösten Aufgaben Silber erreicht. Damals setzte Deepmind auf einen hybriden Ansatz aus vortrainierten LLMs und klassischen Suchalgorithmen. Welche Methode OpenAI und Deepmind in diesem Jahr verwendet haben, ist bislang unklar.
Artikel vom 19. Juli 2025:
Ein experimentelles Sprachmodell von OpenAI hat erstmals Aufgaben der Internationalen Mathematik-Olympiade (IMO) auf Goldmedaillen-Niveau gelöst – ein möglicher Meilenstein für KI-Systeme mit allgemeinem Denkvermögen. Die Ergebnisse sind bislang nicht unabhängig bestätigt.
Ein experimentelles Sprachmodell von OpenAI hat bei Aufgaben der Internationalen Mathematik-Olympiade (IMO) 2025 eine Leistung erzielt, die einer Goldmedaille entspricht. Laut den OpenAI-Forschern Alexander Wei und Noam Brown löste das Modell die ersten fünf der sechs offiziellen Aufgaben und erreichte 35 von 42 möglichen Punkten.
Die IMO gilt als anspruchsvollster Mathematikwettbewerb für Schüler. Ihre Aufgaben erfordern kreative, ausdauernde und logisch präzise Denkprozesse. Wei zufolge ist das OpenAI-Modell das erste KI-System, das auf diesem Niveau mithalten kann: Es sei in der Lage, "komplexe, wasserdichte Argumente auf dem Niveau menschlicher Mathematiker" zu formulieren.

Die Einreichungen wurden unter Wettbewerbsbedingungen erstellt: zwei Sitzungen à 4,5 Stunden, ohne Hilfsmittel, mit Lösungen in natürlicher Sprache. Bewertet wurden sie anonym von ehemaligen IMO-Medaillengewinnern. Die vollständigen Lösungen sind auf Github einsehbar.
Raum für noch mehr Skalierung
Das Modell ist anders als Deepminds AlphaGeometry kein auf Mathematik spezialisiertes System, sondern weiter ein Reasoning-Sprachmodell, das laut Brown "neue experimentelle Techniken" im Bereich Generalisierung und testzeitbasierter Skalierung nutzt.
"o1 hat für Sekunden nachgedacht, Deep Research für Minuten. Dieses Modell denkt stundenlang nach", schreibt Brown. Das Modell sei effizienter im Denken und habe noch Skalierungspotenzial. Bereits eine leichte Überlegenheit gegenüber menschlicher Leistung könne in der Wissenschaft bedeutsam sein, so Brown weiter.
OpenAI plant derzeit keine Veröffentlichung des Modells oder eines ähnlich leistungsfähigen mathematischen Modells in den kommenden Monaten. Es handle sich um ein reines Forschungsprojekt. GPT-5 sei zwar "bald" geplant, so Wei, habe aber nichts mit dem IMO-Modell zu tun. Entwickelt wurde es von einem kleinen Team unter Weis Leitung.
Brown deutet an, dass OpenAI an einem entsprechenden Produkt arbeitet und zukünftige Versionen angesichts des rasanten Fortschritts noch leistungsfähiger sein könnten. Das aktuelle Ergebnis sei selbst für OpenAI überraschend und ein "Meilenstein, den viele noch Jahre in der Zukunft gesehen hätten."
Aktuelle KI-Modelle sind weit abgeschlagen
Dass OpenAI gerade jetzt diese inoffiziellen Resultate veröffentlicht, ist kein Zufall: Denn die Ergebnisse aktueller KI-Modelle bei der jüngsten Mathematik-Olympiade enttäuschten eher.
Die Plattform MathArena.ai bewertete mehrere führende Sprachmodelle – darunter Gemini 2.5 Pro, Grok-4, DeepSeek-R1 sowie OpenAIs eigene Modelle o3 und o4-mini – anhand der IMO-2025-Aufgaben. Keines der Modelle erreichte die für eine Bronzemedaille nötigen 19 Punkte. Gemini 2.5 Pro schnitt mit 13 von 42 Punkten am besten ab, alle anderen lagen deutlich darunter.

Trotz aufwendiger Best-of-32-Auswahl und Bewertungen durch IMO-Experten zeigten sich in den Ergebnissen gravierende Schwächen: logische Fehler, fehlende Begründungen und erfundene Theoreme waren häufig.
Vor diesem Hintergrund erscheint OpenAIs Goldmeldung auch als gezielte Reaktion auf die im MathArena-Test deutlich gewordene Leistungsgrenze aktueller Systeme. Das schmälert den Fortschritt nicht – vorausgesetzt, er lässt sich reproduzieren und auf reale Anwendungsbereiche übertragen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.