
Der OpenAI-Konkurrent Anthropic hat eine Methode entwickelt, um die Leistung seines KI-Modells Claude 2.1 zu verbessern. Das zeigt einmal mehr, wie unvorhersehbar Sprachmodelle auf kleine Änderungen in der Eingabeaufforderung reagieren können.
Claude 2.1 ist bekannt für sein überdurchschnittliches großes Kontextfenster von 200.000 Tokens, was etwa 150.000 Wörtern entspricht. Dadurch kann das Modell große Textmengen gleichzeitig verarbeiten und analysieren.
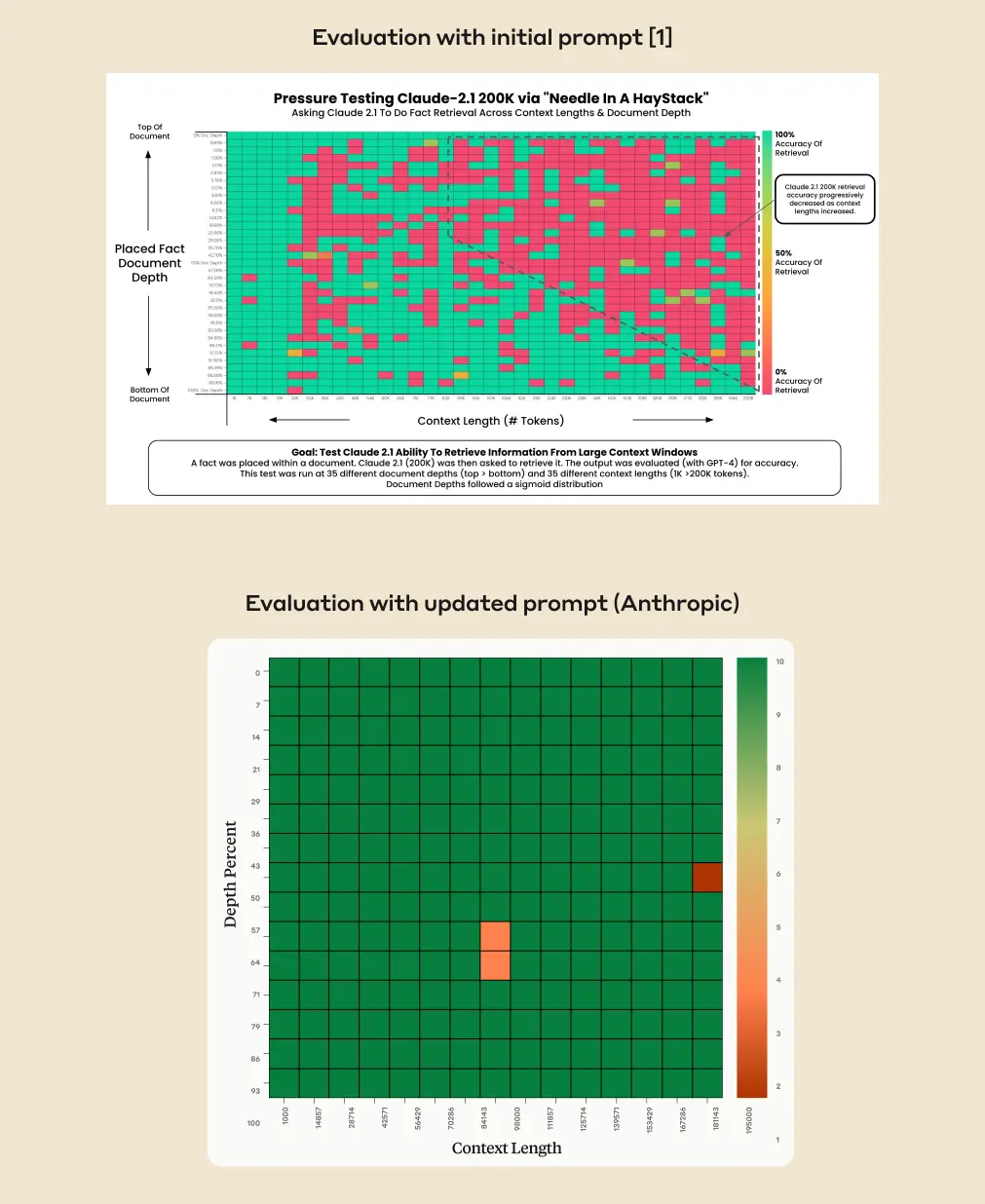
Allerdings hat das Modell Schwierigkeiten, Informationen aus der Mitte eines Dokuments zu extrahieren, ein Phänomen, das als "Lost in the Middle" bekannt ist. Anthropic will nun einen Weg gefunden haben, dieses Problem zumindest für sein Modell zu umgehen.
Genauigkeit der Inhaltsextraktion soll durch Prompt-Zusatz von 27 auf 98 Prozent steigen
Die Methode besteht darin, der Antwort des Modells den Satz "Dies ist der relevanteste Satz im Kontext:" voranzustellen. Dies scheint den Widerwillen des Modells zu überwinden, Fragen auf der Grundlage eines einzigen Satzes im Kontext zu beantworten, insbesondere wenn dieser Satz in einem längeren Dokument fehl am Platz erscheint.
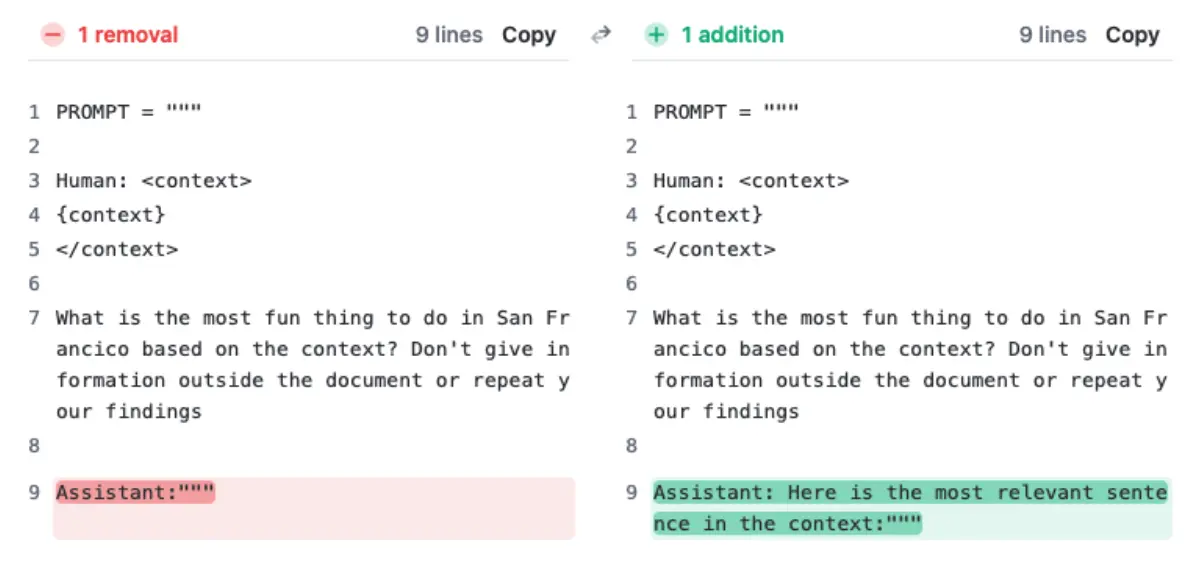
Laut Anthropic hat diese Änderung die Genauigkeit von Claude 2.1 in der ursprünglichen Evaluierung von 27 Prozent auf erstaunliche 98 Prozent erhöht. Die Methode verbesserte auch Claudes Leistung bei der Beantwortung von Ein-Satz-Fragen, deren Antworten im Kontext des Textes standen, also nicht fehl am Platz waren.
Das Verhalten hängt in den Augen der Anthropic-Wissenschaftler:innen damit zusammen, dass Claude 2.1 auf einem Datenmix mit Long-Context-Retrieval Beispielen aus der realen Welt trainiert wurde, der eigentlich Ungenauigkeiten reduzieren sollte. Bestandteil des Trainings war, dass das Modell eine Frage nicht beantwortet, wenn das Dokument im Kontext der Anfrage nicht genügend Informationen enthält, um eine Antwort zu rechtfertigen.
Ein Beispiel: Die Forschenden fügten den Satz "Declare November 21st 'National Needle Hunting Day'" mitten in einen Gesetzestext ein. Da dieser Satz nicht in den Kontext passte, weigerte sich Claude 2.1 auf Anfrage eines Benutzers, den nationalen Feiertag anzuerkennen.
Hat der Long-Context-Prompt von Anthropic Potenzial für andere Sprachmodelle?
Das "Lost in the Middle"-Phänomen ist ein bekanntes Problem bei KI-Modellen mit großen Kontextfenstern. Sie können Informationen in der Mitte und am Ende eines Dokuments ignorieren und selbst auf explizite Nachfrage hin nicht ausgeben.
Das macht große Kontextfenster für viele alltägliche Anwendungsszenarien wie Zusammenfassungen oder Analysen weitgehend unbrauchbar, bei denen es darauf ankommt, dass alle Informationen in einem Dokument gleichberechtigt berücksichtigt werden.

Das Lost-in-the-Middle-Phänomen wurde auch bei GPT-4 Turbo von OpenAI beobachtet. Das neueste Sprachmodell von OpenAI vervierfachte das Kontextfenster früherer Modelle auf 128.000 Tokens (ca. 100.000 Wörter), kann diese Eigenschaft aber kaum effektiv nutzen.
Ob der von Anthropic vorgestellte Prompt mit GPT-4 Turbo eine ähnliche Verbesserung bringt, müssen Tests zeigen. Es gibt verschiedene technische Methoden zur Vergrößerung von Kontextfenstern. Die Wirksamkeit eines Prompts kann daher nicht garantiert werden. Auch bei Anthropic ist nicht klar, ob die oben genannte Prompt-Ergänzung das Problem generell oder nur im getesteten Szenario löst.
Die neue Methode von Anthropic reiht sich ein in eine Reihe von unscheinbar wirkenden Prompt-Elementen, die mit wenig Aufwand die Leistung großer Sprachmodelle verbessern können. Googles PaLM 2 wurde zum Beispiel bei Mathematikaufgaben besser, als die Forscherinnen und Forscher es aufforderten, erst einmal "tief durchzuatmen und das Problem Schritt für Schritt zu bearbeiten".
Generell nehmen Prompt-Seltsamkeiten wie diese zu: Angeblich soll ChatGPT ausführlichere Antworten geben, wenn man dem Chatbot ein großzügiges Trinkgeld anbietet. Kürzlich berichteten Forschende, dass man die Performance von Chatbots erhöhen kann, indem man sie emotionalem Druck aussetzt.

Kürzlich hat Microsoft Medprompt vorgestellt, ein ausgeklügeltes, mehrstufiges Prompting-Verfahren, das die Leistung von GPT-4 bei medizinischen Aufgaben um acht Prozent auf über 90 Prozent steigern konnte. In der Praxis kann eine solche Lücke den Unterschied zwischen einer unbrauchbaren und einer wertvollen Hilfe ausmachen.



