Brauchen KI-Modelle wirklich riesige Kontextfenster?

KI-Unternehmen wie Google, OpenAI oder Anthropic vermarkten besonders große Kontextfenster ihrer Modelle, mit denen diese viele Daten gleichzeitig verarbeiten können. Aber sind sie wirklich der sinnvolle nächste Schritt?
Die größte Innovation bei großen Sprachmodellen in den vergangenen Monaten sind sehr große Kontextfenster. Die Hersteller versprechen, dass damit riesige Dokumente wie ganze Bücher oder sogar Buchreihen auf einen Schlag verarbeitet werden können.
Das stimmt zwar, aber sie verschweigen dabei ein wesentliches Detail: Diese Verarbeitung ist nicht zuverlässig. Je mehr Informationen man in das KI-Modell schaufelt, desto größer ist die Wahrscheinlichkeit, dass wichtige Details, zum Beispiel in einer Zusammenfassung, verloren gehen.
Das macht große Kontextfenster für viele Anwendungsszenarien zwar nicht nutzlos, aber weniger wertvoll. Überdies führen große Kontextfenster dazu, dass die Modelle teurer in der Ausführung sind und mehr Energie verbrauchen.
Kleine Kontextfenster besser nutzen
Forscherinnen und Forscher der Renmin Universität in China und der Beijing Academy of Artificial Intelligence argumentieren nun in einem Paper, dass die meisten Aufgaben mit langen Texten auch mit kleineren Kontextfenstern gelöst werden können. Denn oft seien nur Teile des langen Textes für die gestellte Aufgabe relevant.
Dazu entwickelten sie ein Verfahren namens LC-Boost auf Basis von GPT-3.5. LC-Boost zerlegt lange Texte in kürzere Abschnitte und lässt das Sprachmodell mit kleinerem Kontextfenster entscheiden, welche Teile für die Lösung der Aufgabe notwendig sind und wie diese am besten verwendet werden. So kann das Modell flexibel nur die relevanten Abschnitte verarbeiten und irrelevante Informationen herausfiltern.
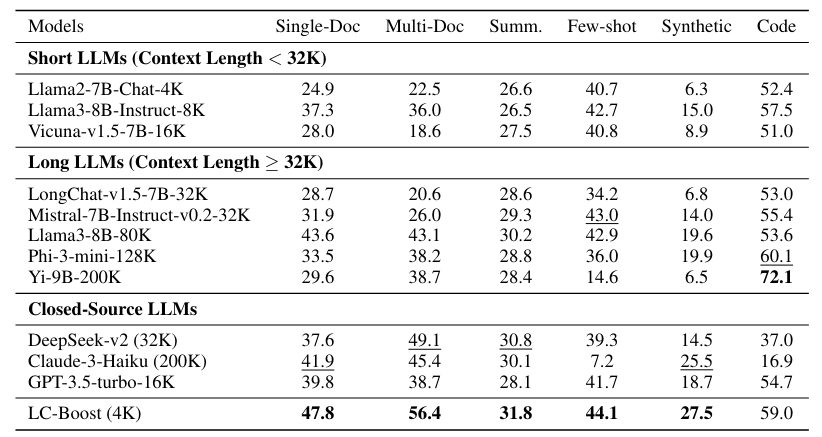
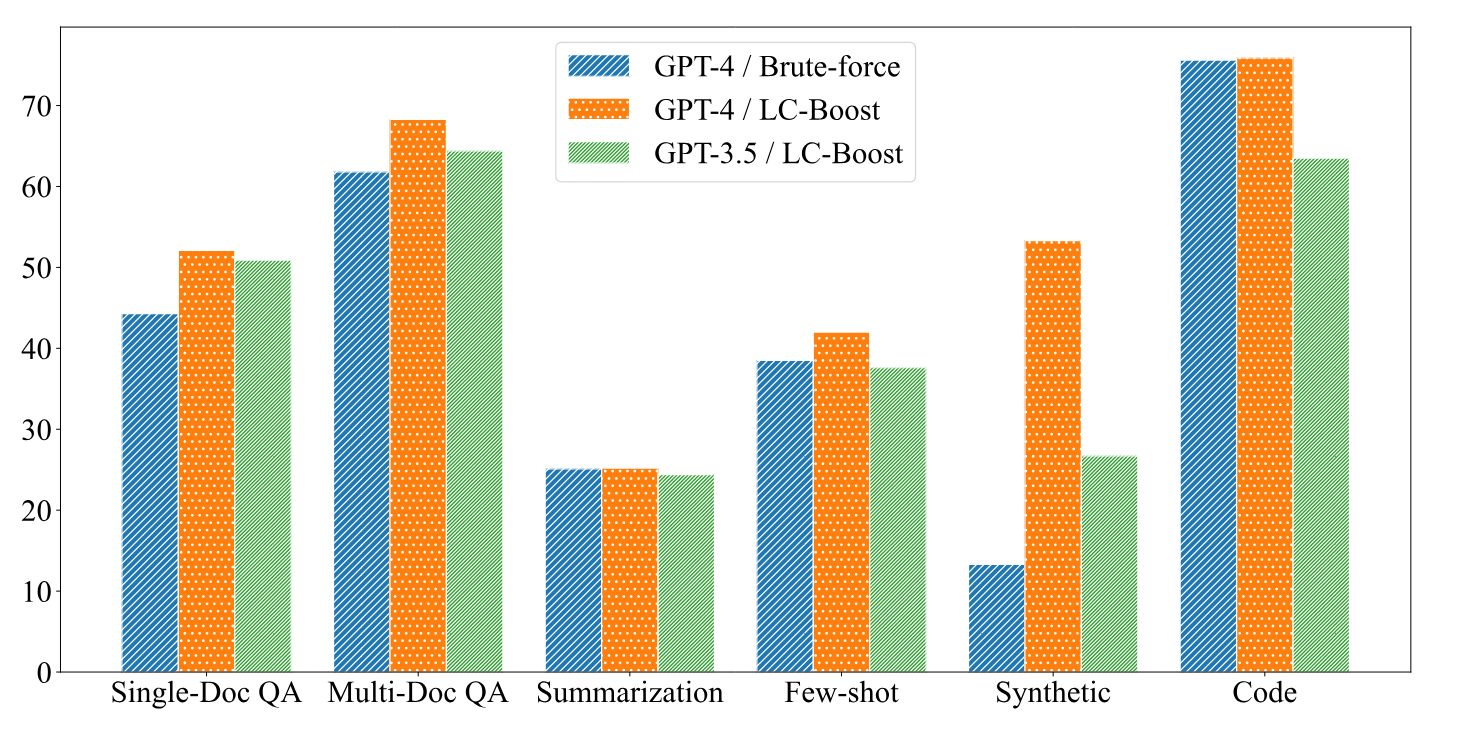
In Experimenten mit zwölf Datensätzen zu Frage-Antwort-, Zusammenfassungs- und Code-Vervollständigungsaufgaben erzielte LC-Boost mit einem Kontextfenster von 4.000 Token gleich gute oder bessere Ergebnisse als Modelle mit bis zu 200.000 Kontext-Token. Vor allem bei Frage-Antwort-Aufgaben war LC-Boost überlegen, da es besser in der Lage war, die exakte Information zu finden, die für eine Antwort notwendig ist.
Die Wissenschaftler demonstrieren die Leistungsfähigkeit von LC-Boost unter anderem am Beispiel des Romans "Harry Potter und die Kammer des Schreckens" mit rund 122.000 Wörtern.
Auf die Frage "Zähle alle Personen auf, die im Buch versteinert wurden" findet das LC-Boost-System drei der fünf Charaktere, die im Verlauf der Handlung von diesem Schicksal ereilt werden, indem es den Text systematisch durchsucht und am Ende die Resultate zusammenfasst. Das ist zwar nicht perfekt, aber besser als etwa Claude 3 Haiku, das nur einen Charakter findet.

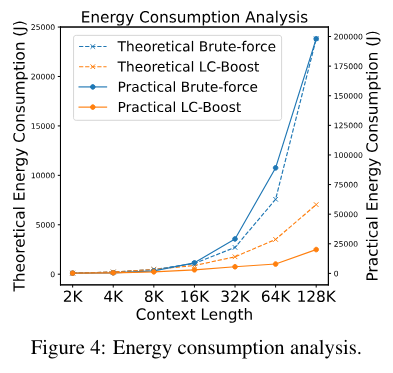
Eine Energieverbrauchsanalyse der Forscher zeigt zudem, dass LC-Boost mit seinem kurzen Kontextfenster deutlich weniger Energie verbraucht als Modelle, die den gesamten Text auf einmal verarbeiten. Bei letzteren explodiert der Energieverbrauch mit zunehmender Kontextlänge.
Die Autoren sehen in ihrem Ansatz einen wichtigen Schritt, um den enormen Ressourcenverbrauch großer Sprachmodelle einzudämmen. Sie erwarten, dass KI-Systeme in Zukunft allgegenwärtig sein werden. Dann wird ihr Energiebedarf zu einer großen ökologischen Herausforderung. Methoden wie LC-Boost, die ressourcenschonendere Ergebnisse liefern, würden daher immer gefragter.
Die Studie zeigt, dass es Alternativen zu großen Kontextfenstern geben kann, die mit smarten Verfahren mit kleineren Fenstern mindestens gleichwertige Ergebnisse erzielen - und das bei deutlich geringerem Energieverbrauch. Es kann jedoch auch komplexere Szenarien geben, die ein Verständnis des gesamten Kontextes erfordern. Für solche Aufgaben könnte LC-Boost weniger geeignet sein, so die Autoren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.