
Databricks hat mit DBRX ein neues leistungsfähiges offenes Sprachmodell vorgestellt, das GPT-3.5, Grok, Mixtral und Llama 2 übertrifft. Damit will das Unternehmen den Trend zu mehr Transparenz und offenen Modellen in der KI-Branche vorantreiben.
Das Technologieunternehmen Databricks hat mit DBRX ein neues offenes Sprachmodell veröffentlicht, das nach eigenen Angaben die Leistung etablierter Open-Source-Modelle übertrifft. In standardisierten Benchmark-Tests schnitt DBRX besser ab als Llama 2 von Meta, Mixtral von Anthropic und sogar das kürzlich veröffentlichte Grok-1-Modell von Elon Musks xAI. Ebenso zeigte DBRX bei den meisten Benchmarks eine bessere Leistung als das GPT 3.5-Modell von OpenAI.
In Composite-Benchmarks wie dem Hugging Face Open LLM Leaderboard und dem Databricks Model Gauntlet erzielte DBRX die besten Ergebnisse aller getesteten Modelle. Auch in Bereichen wie Programmierung und Mathematik überzeugte DBRX.
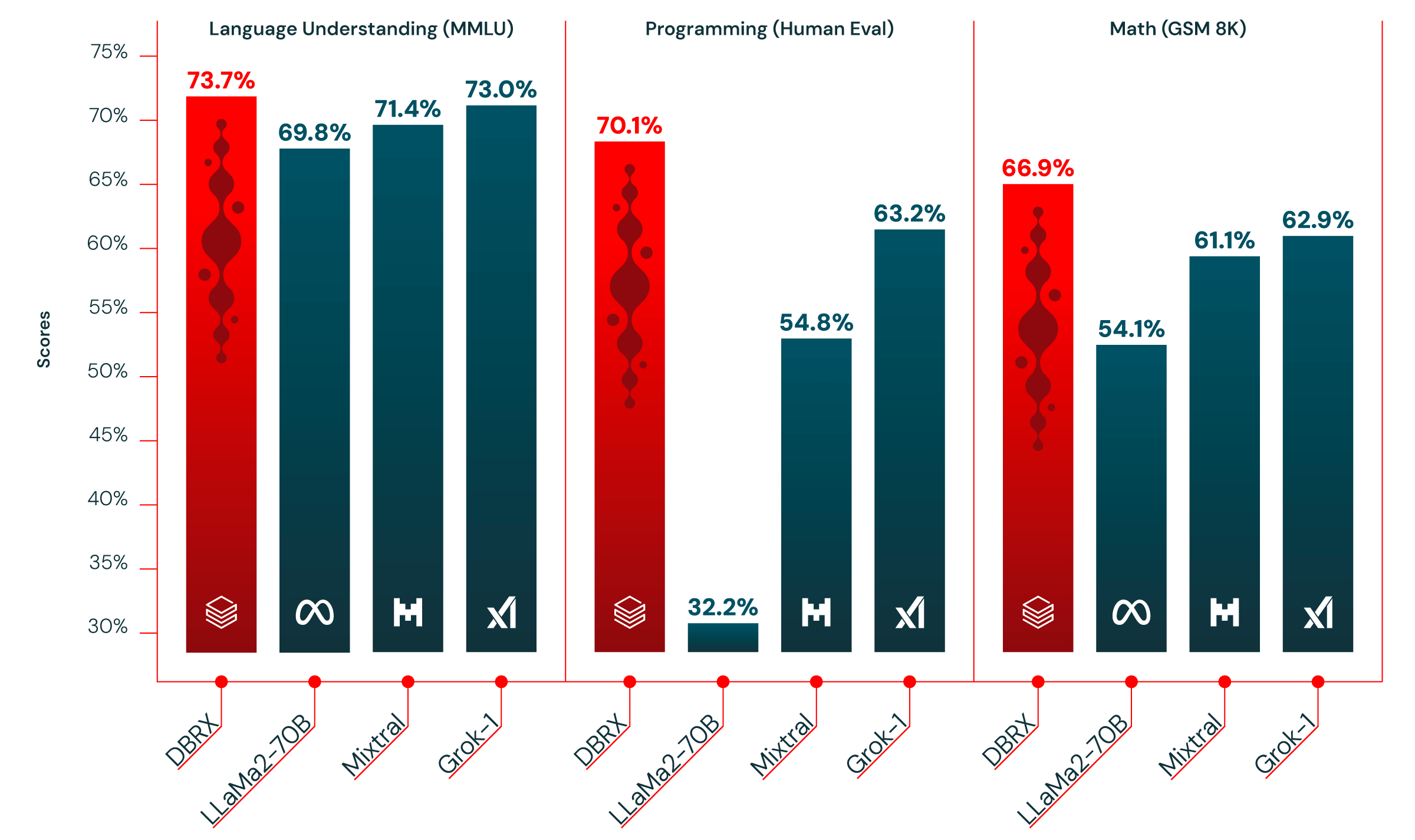
Laut Databricks kommt DBRX in puncto Qualität sogar an GPT-4 heran, das derzeit leistungsfähigste geschlossene Sprachmodell von OpenAI. "Wir haben einen neuen Standard für Open-Source-Sprachmodelle gesetzt", sagte Jonathan Frankle, Chefarchitekt für neuronale Netze bei Databricks, der das DBRX-Projekt leitete.
Das Modell ist jedoch nicht vollständig Open Source - es kommt mit einer Lizenz, die Regeln für Nutzung festlegen und die Trainingsdaten sind nicht verfügbar. Es ist daher eher als offenes Modell einzustufen, ähnlich wie Metas Llama 2, das laut Open-Source-Wächtern nicht Open-Source ist. Private und kommerzielle Nutzung sind erlaubt.
Zudem hat das Team DBRX nicht gegen andere Modelle wie Alibabas QWen1.5 getestet, das laut Benchmarks das neue Modell zumindest im MMLU-Benchmark übertrifft.
DBRX setzt auf Mixture-of-Experts
DBRX ist ein Mixture-of-Experts-Modell mit 132 Milliarden Parametern, von denen jedoch nur 36 Milliarden zu jedem Zeitpunkt aktiv sind, was eine hohe Effizienz in Bezug auf Token pro Sekunde ermöglicht. Das Modell wurde auf 3.072 Nvidia H100 GPUs mit 12 Billionen Token Text und Code mit einem maximalen Kontextfenster von 32.000 Token trainiert. Die Kombination aus hoher Datenqualität und Anpassungen der Modellarchitektur zur Verbesserung der Hardwarenutzung habe zu einer Steigerung der Trainingseffizienz um bis zu 50 Prozent geführt, heißt es in der Mitteilung.
Darüber hinaus ermöglicht Databricks seinen Kunden, DBRX auf der Databricks-Plattform zu nutzen, anzupassen und eigene Modelle auf privaten Daten zu trainieren. Die Open-Source-Community kann über das GitHub-Repository von Databricks sowie über Hugging Face auf DBRX zugreifen.
Durch den Open-Source-Ansatz möchte Databricks die Innovation im Bereich der generativen KI fördern und mehr Transparenz in die Entwicklung von KI-Modellen bringen. Das Unternehmen betont, dass offene LLMs immer wichtiger werden, da Unternehmen zunehmend proprietäre Modelle durch anpassbare Open-Source-Modelle ersetzen, um mehr Effizienz und Kontrolle zu erreichen. Databricks ist davon überzeugt, dass offene Modelle wie DBRX die Wettbewerbsfähigkeit von Unternehmen in ihrer jeweiligen Branche steigern können.

Databricks stellt mit DBRX Base und DBRX Instruct zwei Varianten zur Verfügung. Das Unternehmen hatte in 2023 MosaicML übernommen, dessen Team mit den MPT-Modellen schon früh leistungsfähige, offene Sprachmodelle veröffentlichte.




