DeepMind hat einen simplen Weg gefunden, wie Sprachmodelle besser schlussfolgern

Logische Schlussfolgerungen sind nach wie vor eine große Herausforderung für Sprachmodelle. DeepMind hat einen Weg gefunden, KI dabei zu helfen.
Eine Studie von Googles KI-Sparte DeepMind hat ergeben, dass die Reihenfolge der Prämissen in einer Aufgabe einen erheblichen Einfluss auf die logischen Schlussfolgerungen von Sprachmodellen hat.
Die beste Leistung erzielen sie, wenn die Prämissen in der gleichen Reihenfolge präsentiert werden, in der sie auch in den logischen Schlussfolgerungen auftauchen.
Das gilt nach ihren Beobachtungen auch für mathematische Probleme. Ihre systematisch generierten Tests stellen die Forschenden im R-GSM Benchmark für weitere Untersuchungen zur Verfügung.
Wir zeigen, dass die Reihenfolge der Prämissen einen signifikanten Einfluss auf die Leistung von LLMs bei Inferenzaufgaben hat, selbst wenn die Reihenfolge der Prämissen die zugrundeliegende Aufgabe selbst nicht verändert.
Unsere umfassende Auswertung zeigt, dass LLMs menschliche Präferenzen in Bezug auf die Prämissenreihenfolge ähneln, d.h. LLMs erzielen die beste Leistung, wenn die Prämissenreihenfolge den Zwischenschritten der Problemlösung folgt. Umgekehrt haben LLMs Schwierigkeiten, wenn das Modell die Problembeschreibung vor und zurück lesen muss, was zu einem Leistungsabfall von über 30 Prozent führt.
Aus dem Paper
Wenn A B ist, ist B auch A
Eine Prämisse ist eine Aussage oder Annahme, die als Grundlage für eine Argumentation oder Handlung dient. In ihrer Studie führten die Forscher eine systematische Untersuchung der Auswirkungen der Prämissenordnung auf verschiedene KI-Modelle durch.
Sie konzentrierten sich auf deduktive Schlussfolgerungen und testeten die Modelle anhand von Aufgaben, die nur den logischen Schluss "modus ponense" erforderten, also die Ableitung anderer wahrer Aussagen aus wahren Aussagen.

Der "Modus Ponens" ist eine Form der deduktiven Schlussfolgerung in der Logik. Wenn man zwei Aussagen hat, "Wenn P, dann Q" und "P ist wahr", dann kann man daraus schlussfolgern, dass "Q wahr ist".
Diese Form der Schlussfolgerung ist relativ einfach für Menschen, stellt für Sprachmodelle jedoch nachweislich eine große Hürde dar. Die Forscher stellten fest, dass die Genauigkeit der Modelle um mehr als 30 Prozent sinken kann, wenn die Reihenfolge der Prämissen geändert wird.
Die Tests wurden mit GPT-3.5 Turbo, GPT-4 Turbo, PaLM 2-L und Gemini Pro durchgeführt. OpenAIs GPT-Modelle schnitten dabei immerhin besser ab, wenn die Reihenfolge der Prämissen in genau umgekehrter Reihenfolge der Ground Truth waren.
Generell sei außerdem schlechtere Performance mit steigender Zahl der Regeln festzustellen. Auch würden die Modelle durch überflüssige Prämissen verwirrt.
Die Vergleiche zeigen spannenderweise auch, dass Googles jüngeres Gemini Pro ähnliche Leistung wie OpenAIs "altes" GPT-3.5 Turbo erbringt, da bereits bei relativ niedriger Zahl der Regeln die Genauigkeit rapide abnimmt, selbst wenn sie sich in logischer Reihenfolge befinden. PaLM 2-L entspricht eher dem Niveau von GPT-4 Turbo.
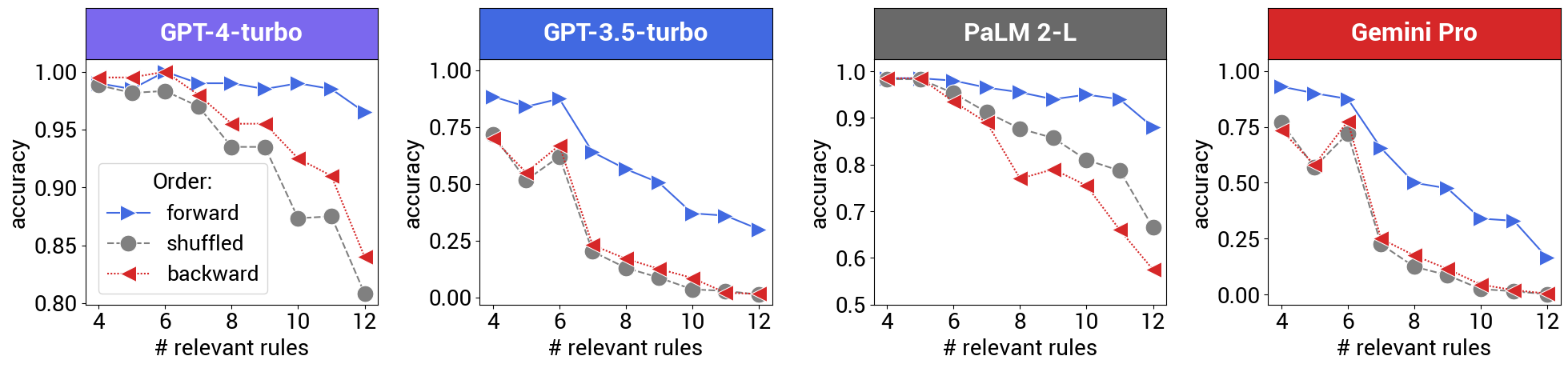
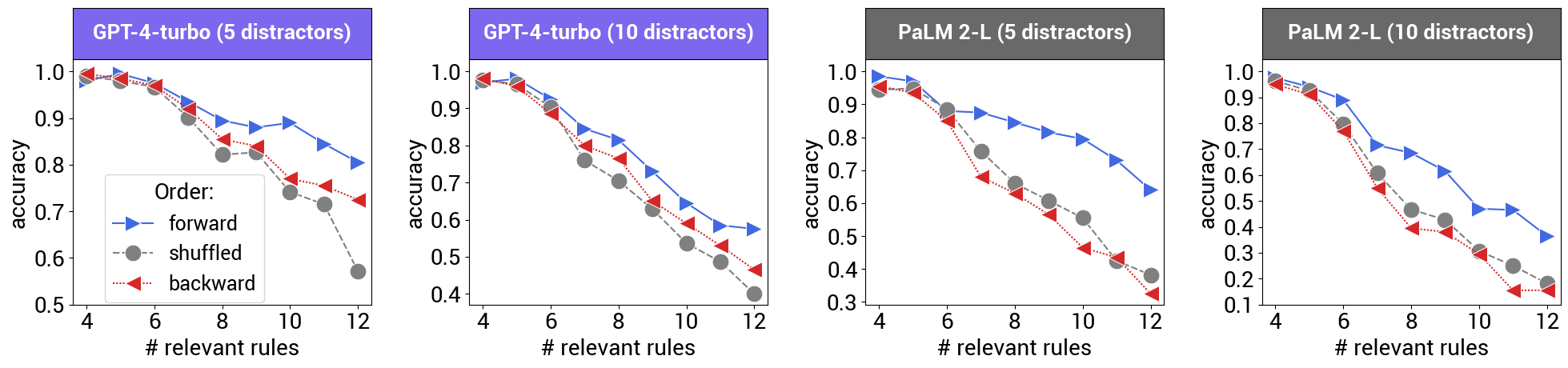
Eine theoretische Erklärung für den Effekt oder gar mögliche Lösungsansätze zur Verbesserung von Sprachmodellen für das logische Denken liefern die Forschenden nicht.
Dennoch könnten die Ergebnisse die Weiterentwicklung von Sprachmodellen unterstützen und Promptexperten helfen, die einfache Schlussfolgerungen in der Praxis einsetzen wollen.
Denn die Fähigkeit zum logischen Denken wird den zukünftigen Nutzen von Sprachmodellen maßgeblich beeinflussen - unabhängig von Features wie dem Kontextfenster, dessen Grenzen Google kürzlich mit Gemini 1.5 Pro gesprengt hat.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.