Der "Prompt Report" ist ein umfassender Prompting-Überblick mit kuriosen Erkenntnissen
Eine Gruppe von mehr als 40 Forschern hat die erste großangelegte systematische Untersuchung von Prompting-Techniken durchgeführt. Der daraus resultierende "Prompt Report" deckt Hunderte von Techniken ab und gibt Einblicke in die Möglichkeiten und die Besonderheiten des Prompting.
Prompting ist allgegenwärtig, aber der KI-Industrie fehlt bisher eine gründliche und systematische Untersuchung der Hunderten Techniken, die sich entwickelt haben.
Um diese Lücke zu schließen, hat eine Gruppe von mehr als 40 Forschenden aus verschiedenen Universitäten und Unternehmen wie OpenAI und Microsoft den "Prompt Report" veröffentlicht - die erste groß angelegte, systematische Übersichtsarbeit zu Prompting-Techniken.
Die Forscher analysierten einen Datensatz von mehr als 1.500 Veröffentlichungen zum Thema Prompting, die sie mithilfe einer maschinengestützten Version des PRISMA-Verfahrens für systematische Übersichtsarbeiten gesammelt hatten.
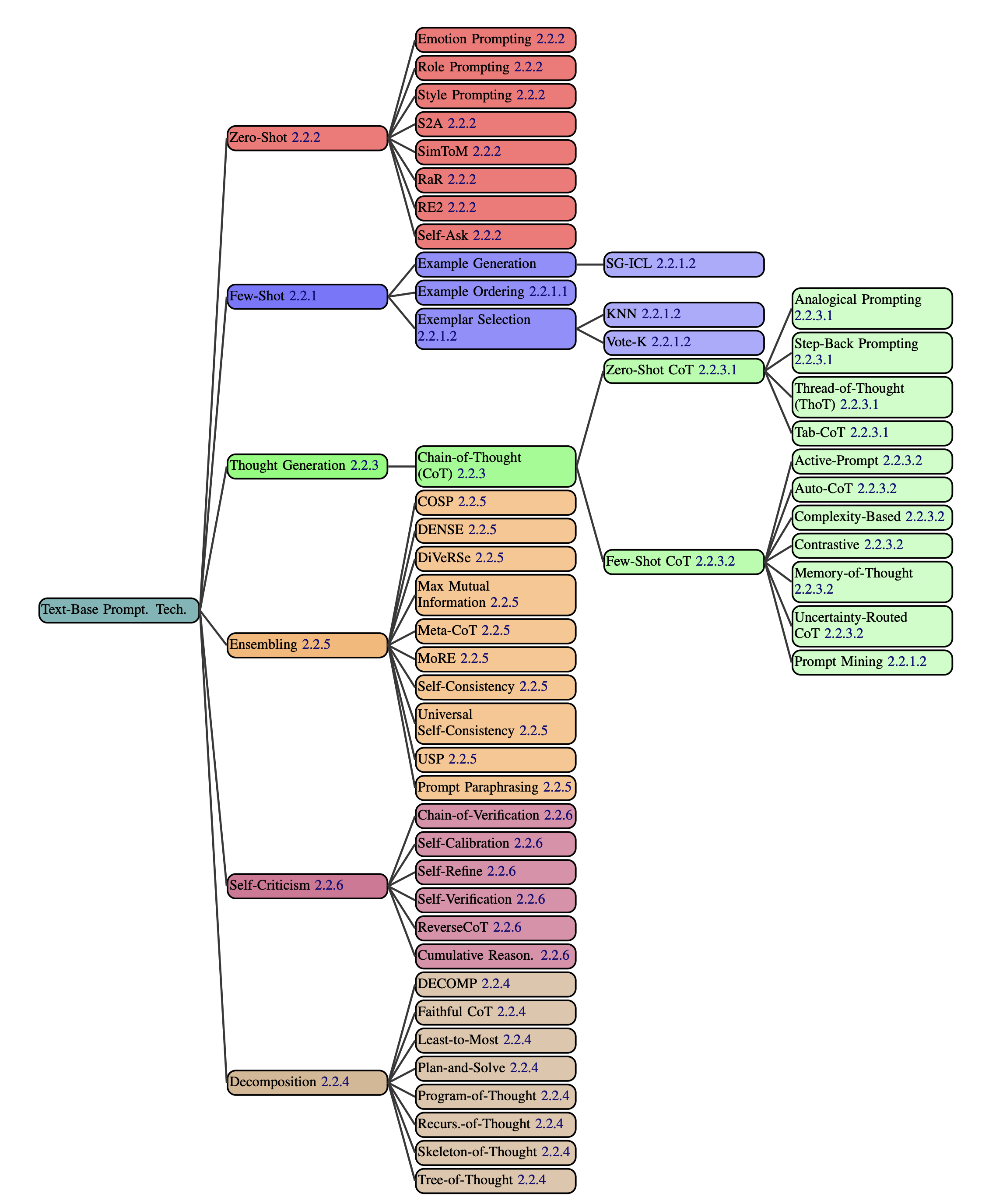
Aus dieser Analyse leiteten sie eine Taxonomie ab, die 58 textbasierte Prompting-Techniken, 40 multimodale Techniken, agentenbasierte Erweiterungen und Themen wie Sicherheit und Orientierung umfasst.
LLMs sind seltsam
Die Forscher fanden einige kuriose Artefakte, wie die Tatsache, dass die Verdoppelung von Teilen eines Prompts die Leistung erheblich steigern kann.
In einer Fallstudie zur Erkennung von suizidalen Krisen wurde eine E-Mail mit Kontext zu einem Fall versehentlich zweimal in den Prompt aufgenommen - und das Entfernen dieser Verdoppelung verringerte die Genauigkeit.
Es gibt keine klare Erklärung dafür, warum dieser "Wiederholungseffekt" auftritt. Laut der Forschenden erinnert er an die Anweisung an ein LLM, eine Aufgabe vor der Durchführung erneut zu lesen, die ebenfalls die Qualität des Outputs steigern kann.
Die Einbeziehung von Personennamen in die Prompts kann laut der Tests ebenfalls von großer Bedeutung sein. Als die Namen in der oben erwähnten E-Mail anonymisiert wurden, indem sie durch zufällige Namen ersetzt wurden, nahm die Genauigkeit des Modells ab.
Diese Sensibilität für solche irrelevanten Details ist rätselhaft, und die Forscher sehen darin sowohl positive als auch negative Aspekte. Positiv sei, dass durch Exploration Leistungsverbesserungen erzielt werden könnten.
Negativ gesehen zeige das E-Mail-Beispiel, dass Prompting eine "schwer zu erklärende schwarze Kunst" sei, bei der das Sprachmodell unerwartet sensibel auf Details reagiere, die der Benutzer für irrelevant halte.
Aufgrund dieser Sensibilität empfehlen die Autoren eine enge Zusammenarbeit zwischen Prompt Engineers, die wissen, wie man die Modelle steuert, und Fachexperten, die die Ziele genau verstehen. "Generative KI wird nicht programmiert, sondern überredet", fassen die Forscher zusammen.
Prompts mit Beispielen sind besonders effektiv
Few-Shot-Prompting, also Prompting mit Beispielen direkt im Prompt, ist in der Regel die effizienteste Prompting-Methode. Allerdings gibt es auch hier merkwürdige Fallstricke.
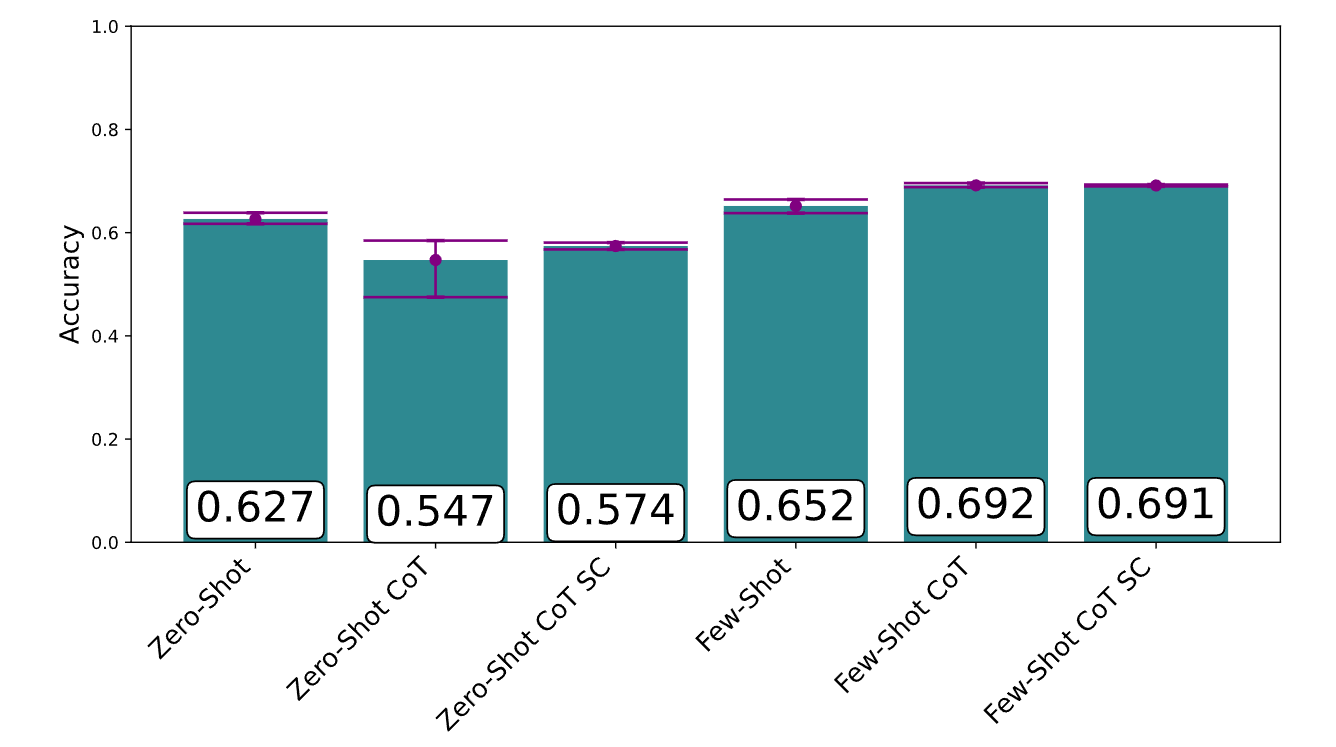
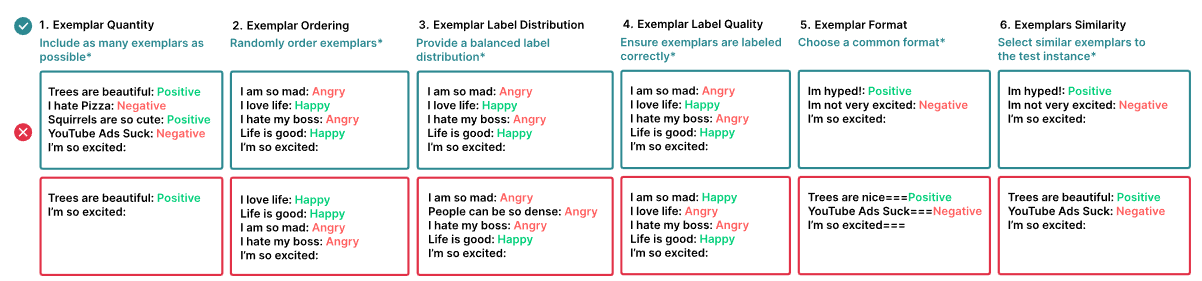
So reagieren LLMs sehr empfindlich auf die Auswahl und Reihenfolge der Beispiele. Je nach Reihenfolge kann die Leistung von weniger als 50 Prozent bis zu mehr als 90 Prozent Genauigkeit schwanken. Die Auswahl ähnlicher Beispiele für den Testfall ist in der Regel hilfreich, aber in einigen Fällen funktionieren unterschiedliche Beispiele besser.
Der Bericht zeigt auch, dass bisher nur ein kleiner Teil der Prompting-Techniken in Forschung und Industrie weitverbreitet ist, wobei Few-Shot- und Chain-of-Thought-Prompting am häufigsten vorkommen. Techniken wie Program-of-Thoughts, bei denen Code als Zwischenschritt zum Denken verwendet wird, sind vielversprechend, würden aber bisher nicht häufig eingesetzt.
Wegen der Herausforderungen beim manuellen Prompting sehen die Forscher großes Potenzial in der Automatisierung. In einer Fallstudie erzielte ein automatisierter Ansatz die besten Ergebnisse. Eine Kombination aus menschlicher Feinabstimmung und maschineller Optimierung könnte jedoch der erfolgversprechendste Weg sein, so die Forscher.
Neben der Systematisierung des Wissens wollen die Forscher eine gemeinsame Terminologie und Taxonomie erarbeiten. Sie hoffen, mit ihrer Arbeit eine Grundlage für ein besseres Verständnis, eine bessere Bewertung und eine Weiterentwicklung des Prompting zu schaffen. Sie empfehlen, sich nicht blind auf Benchmark-Ergebnisse zu verlassen, sondern Techniken gründlich in der Praxis zu testen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.