Google Gemini Pro wird laut Studie vom kostenlosen ChatGPT abgehängt
Eine aktuelle Studie von KI-Forschern der Carnegie Mellon University (CMU) zeigt, dass Googles großes Sprachmodell Gemini Pro im Benchmark-Vergleich hinter GPT-3.5 und weit hinter GPT-4 zurückliegt.
Die Ergebnisse widersprechen den Angaben von Google bei der Vorstellung von Gemini. Sie unterstreichen die Notwendigkeit neutraler Benchmarking-Institutionen oder -Verfahren.
Gemini Pro verliert gegen GPT-3.5 in Benchmarks
Google DeepMinds Gemini ist das neueste Modell in einer Reihe großer Sprachmodelle. Das Gemini-Team behauptet, dass die "Ultra"-Version bei verschiedenen Aufgaben besser abschneidet als GPT-4. Allerdings hat Google bereits bei der Darstellung der Ultra-Ergebnisse getrickst.
Gemini Pro soll mit GPT-3.5 vergleichbar sein. Die CMU-Studie zeigt jedoch, dass Gemini Pro im Vergleich zu OpenAI GPT-3.5 Turbo bei allen Aufgaben zum Testzeitpunkt eine geringere Leistung aufwies.
Diskrepanzen bei Benchmarks
Einige Diskrepanzen könnten auf die Schutzmechanismen von Google zurückzuführen sein, die dazu führten, dass das Modell einige Fragen der MMLU-Bewertung nicht beantwortete. Diese fehlenden Antworten wurden für jedes Modell als falsch gewertet.
Die Forscher stellten jedoch auch fest, dass Gemini Pro im Bereich des grundlegenden mathematischen Denkens, das für Aufgaben in den Bereichen formale Logik und elementare Mathematik erforderlich ist, schlechter abschnitt.
In den Themenkategorien schlug Gemini Pro GPT-3.5 nur in den Kategorien Security Studies und Highschool Microeconomics. In allen anderen Kategorien lag das Modell zurück.

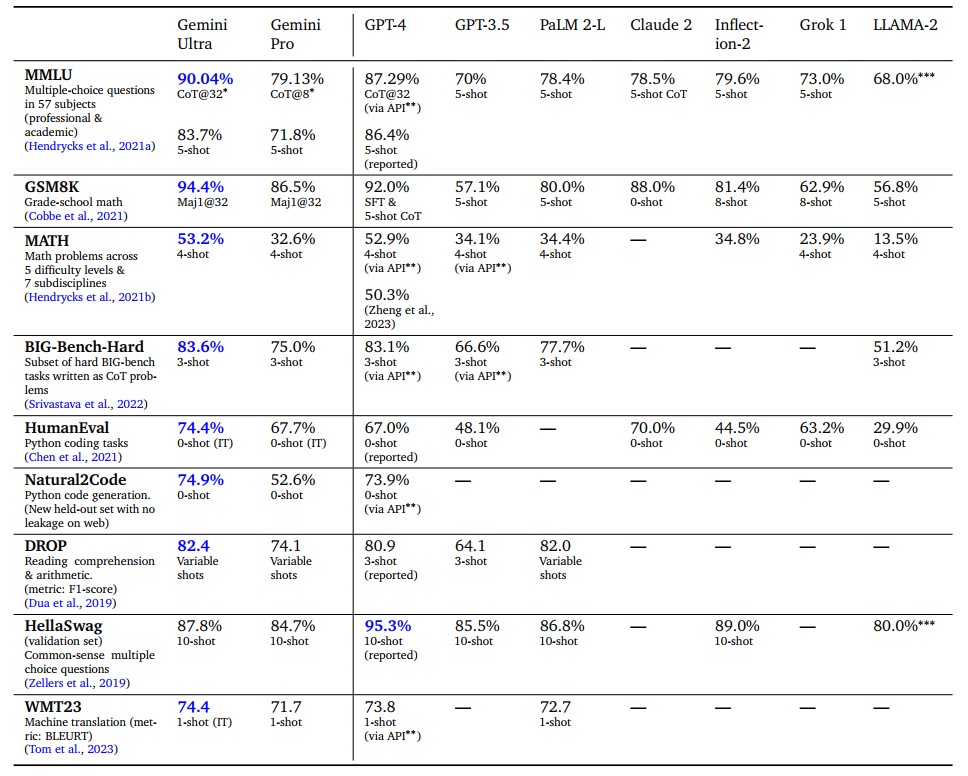
Google gab die MMLU 5-Shot und Chain of Thought (CoT) Werte von Gemini Pro mit 71,8 bzw. 79,13 an, während die CMU-Forscher 64,1 bzw. 60,6 ermittelten. Der von Google gemeldete Big Bench Hard Benchmark-Wert lag bei 75,0, während die CMU-Forscher ihn mit 65,6 ermittelten. Das sind signifikante Unterschiede, deren Ursprung noch ungeklärt ist.
Bedarf an neutralem Modell-Benchmarking
Die Ergebnisse der Studie zeigen, dass die ausschließliche Verwendung von selbstberichteten Benchmark-Werten großer Unternehmen keine zuverlässige Messung der Leistung von LLMs darstellt.
Sie zeigen auch, dass OpenAI mit GPT-3.5, dem Modell hinter dem freien ChatGPT, immer noch komfortabel vor Google und damit Google Bard liegt. Und sie sind kein gutes Omen für die ersten neutralen Benchmarks von Gemini Ultra, das - laut Google - besser als GPT-4 sein soll.
Für die KI-Branche ist es jedenfalls keine gute Nachricht, dass Google trotz großer Anstrengungen nicht einmal OpenAI zuverlässig einholen konnte.
Googles Gemini Pro, das in Bezug auf Modellgröße und Klasse mit GPT 3.5 Turbo vergleichbar ist, erreicht im Allgemeinen eine mit GPT 3.5 Turbo vergleichbare Genauigkeit, ist aber etwas schlechter als GPT 3.5 Turbo und deutlich schlechter als GPT 4. Es übertrifft Mixtral bei allen untersuchten Aufgaben.
Gemini Pro war im Durchschnitt etwas schwächer als GPT 3.5 Turbo, vor allem aber hatte es Probleme mit der Antwortreihenfolge bei Multiple-Choice-Fragen (Anm.: Bei Auswahl A, B, C und D wählte es meistens D), mathematischen Berechnungen mit großen Zahlen, vorzeitigem Beenden von Agent-Aufgaben und fehlgeschlagenen Antworten aufgrund aggressiver Inhaltsfilterung.
Auf der anderen Seite gab es aber auch Lichtblicke: Gemini schnitt bei besonders langen und komplexen Denkaufgaben besser ab als GPT 3.5 Turbo und war auch bei Aufgaben, bei denen die Antworten nicht gefiltert wurden, mehrsprachig besser.
Aus dem Paper
Die Studie zeigt vermutlich auch den ersten MMLU-Benchmark für GPT-4 Turbo. Demnach liegt das neueste OpenAI-Modell im wichtigen Sprachverständnis-Benchmark deutlich hinter dem ursprünglichen GPT-4 (80,48 GPT-4 Turbo vs. 86,4 GPT-4).
Dieses Ergebnis wird teilweise durch die ersten Berichte aus der realen Nutzung bestätigt. Andererseits ist der GPT-4-Turbo derzeit das mit Abstand am besten bewertete Modell in der Chatbot-Arena. Das zeigt, dass Benchmarks nur bedingt aussagekräftig sind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.