Google und Deepmind entwickeln extrem schnelle KI-3D-Szenengenerierung

Ein Team von Forschenden bei Google Research und Google DeepMind hat eine neue KI-Methode entwickelt, die in Sekundenschnelle realistische 3D-Szenen aus einzelnen oder mehreren Fotos erzeugen kann - vorausgesetzt, die Aufnahmeposition der Kamera ist bekannt.
Das "Bolt3D" getaufte System verwandelt innerhalb von nur 6,25 Sekunden auf einer Nvidia-H100-Grafikeinheit ein oder mehrere Fotos in eine vollständige, dreidimensionale Szene. Dafür muss das System wissen, von wo aus die Fotos aufgenommen wurden. Bisherige Verfahren benötigen für eine vergleichbare Aufgabe oft mehrere Minuten oder sogar Stunden.
Das System geht in zwei Schritten vor: Zunächst analysiert ein KI-Modell die Fotos und bestimmt für jeden Bildpunkt die passende Position und Farbe im dreidimensionalen Raum. Anschließend berechnet ein zweites KI-Modell, wie durchsichtig oder undurchsichtig jeder dieser Punkte sein soll und wie sie sich im Raum ausdehnen.
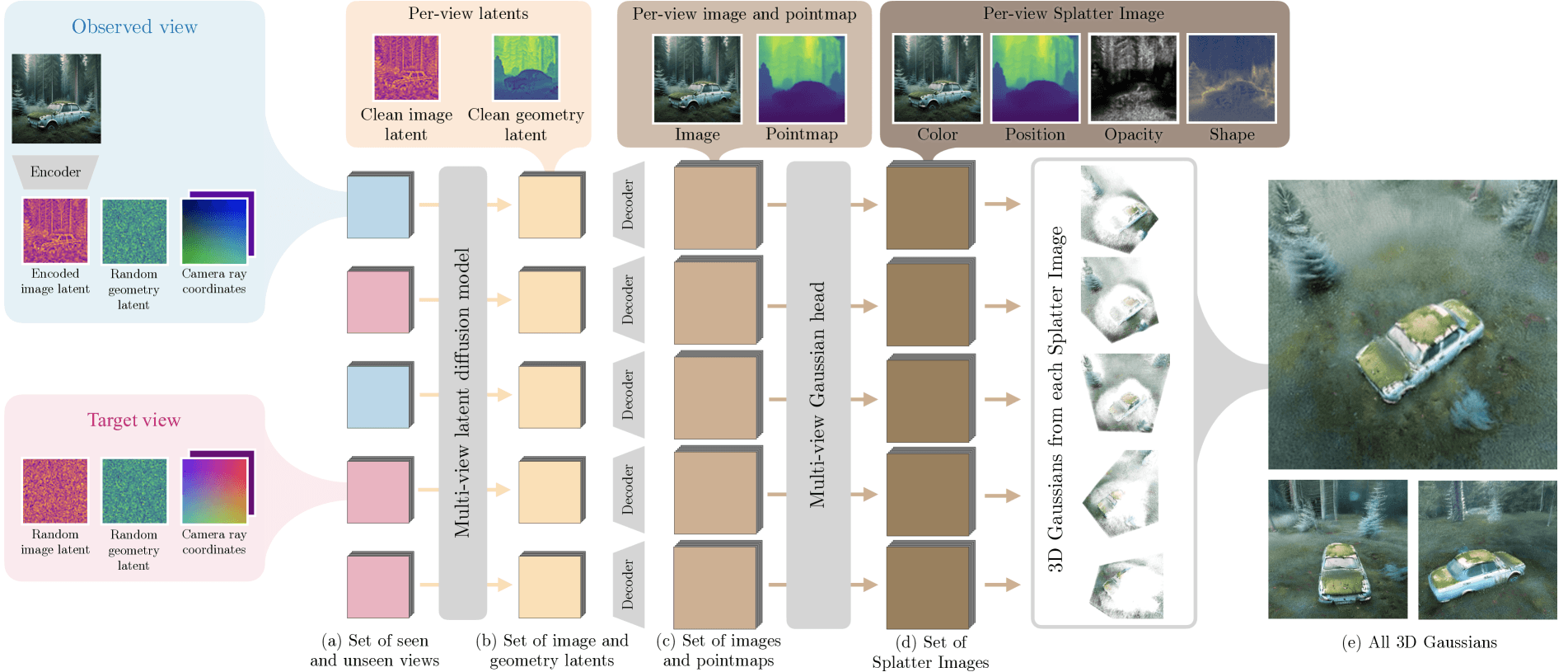
Diese Informationen werden in einem speziellen Format namens "Gaussian Splatting" gespeichert. Dabei wird die 3D-Szene durch eine Sammlung von dreidimensionalen Gauß-Funktionen dargestellt, die in mehreren 2D-Gittern organisiert sind.
Bolt3D bringt 3D-Daten in 2D-Gitter. | Video: Szymanowicz et al.
Jede dieser Funktionen speichert neben Position, Farbe und Transparenz auch Informationen darüber, wie sie sich im Raum ausdehnt. Damit ermöglicht das Format die Darstellung der 3D-Szene aus verschiedenen Blickwinkeln in Echtzeit. Um die Dateigröße zu optimieren, werden vollständig transparente Bereiche entfernt und die Daten effizient komprimiert.
Bessere Ergebnisse als bisherige KI-Methoden
In Tests hat Bolt3D bestehende schnelle Verfahren wie Flash3D und DepthSplat deutlich übertroffen. Ein wichtiger Vorteil: Während diese Verfahren Bereiche, die auf den Originalfotos nicht zu sehen sind, nur unscharf darstellen können, ergänzt Bolt3D auch verborgene Teile einer Szene realistisch.
Besonders glänzt Bolt3D in Bereichen der Szene, die im Eingangsbild nicht gut zu erkennen sind. | Video: Szymanowicz et al.
Entscheidend für die hohe Qualität ist ein speziell entwickeltes KI-Modell zur Verarbeitung der räumlichen Informationen. Die Forschenden zeigen, dass herkömmliche, nur auf Fotos trainierte Modelle für diese Aufgabe ungeeignet sind, da sie die besonderen Eigenschaften dreidimensionaler Daten nicht berücksichtigen können.
Umfangreiches Training mit 3D-Daten
Um das System zu trainieren, nutzten die Forscher:innen etwa 300.000 dreidimensionale Szenen aus verschiedenen Datensätzen. Diese Szenen wurden aus vielen Einzelfotos mit speziellen 3D-Rekonstruktionsverfahren erstellt. Zusätzlich wurden computergenerierte 3D-Modelle verwendet. Diese große Datenmenge ermöglicht es dem System, auch unvollständig fotografierte Szenen plausibel zu ergänzen.
Die Forschenden räumen ein, dass das System noch Schwächen hat: Sehr feine Strukturen, die auf den Fotos weniger als acht Pixel breit sind, kann es nicht zuverlässig erkennen. Auch transparente Oberflächen wie Glas und stark reflektierende Materialien bereiteten noch Probleme. Außerdem reagiere das Modell empfindlich darauf, wie die Szene fotografiert wurde und wie groß sie dargestellt werden soll.
Trotz dieser Einschränkungen könnte die neue Technologie einen wichtigen Schritt zur effizienten Erstellung von 3D-Inhalten darstellen. Da sie um ein Vielfaches schneller ist als bisherige Verfahren, ermöglicht sie laut Paper die Generierung von 3D-Szenen in großem Maßstab.
In eine ähnliche Richtung gehen die kürzlich vorgestellten Entwicklungen von Stability AI.SPAR3D erzeugt ebenfalls in Sekundenbruchteilen 3D-Objekte aus einzelnen Eingabebildern. Im Gegensatz zu einzelnen Objekten beherrscht Bolt3D jedoch die Generierung ganzer Szenen.
Ob und wie das vorgestellte Modell Bolt3D der Öffentlichkeit zugänglich gemacht werden soll, geht aus dem Paper nicht hervor. Es existiert jedoch eine Projektwebsite, auf der weitere Visualisierungen und interaktive Demos zu finden sind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.