Graph RAG: Zugriff auf externe Daten wird mit Microsofts Ansatz deutlich genauer

Wer externe Daten mit einem Sprachmodell verarbeiten will, greift in der Regel auf RAG zurück. Doch wie diese Daten dem LLM zugeführt werden, spielt eine entscheidende Rolle.
In einem im April veröffentlichten Paper haben Forscher:innen von Microsoft einen Ansatz namens Graph RAG vorgestellt, der generelle Anfragen an eine große Datenbasis deutlich sinnvoller beantworten kann, anstatt nur - wie bisherige Ansätze - Textausschnitte aneinanderzureihen.
Innerhalb weniger Monate zeichnete sich ab, dass die Methode Vorteile gegenüber dem klassischen, weit verbreiteten RAG-Ansatz auf Vektorbasis bietet - und die KI-Entwicklung damit nachhaltig beeinflussen könnte.
Retrieval-Augmented Generation (RAG) ist eine etablierte Idee zur Beantwortung von Benutzerfragen über ganze Datensätze hinweg, die zu groß wären, um vollständig in ein Kontextfenster eines Sprachmodells passen würden.
Modelle wie Gemini 1.5 Pro können inzwischen zwei Millionen Token auf einmal verarbeiten. Ein RAG-Framework ruft zunächst relevante Informationen aus externen Datenquellen ab und reichert damit das Kontextfenster der ursprünglichen Abfrage eines großen Sprachmodells an.
Herkömmliches RAG auf Basis von Vektordatenbanken ist jedoch für Situationen konzipiert, in denen Antworten lokal in Textbereichen enthalten sind und deren Abruf ausreichende Grundlage für die Generierungsaufgabe bietet. Es ist weniger für abfragefokussierte Zusammenfassungen geeignet, die sich über den kompletten Korpus erstrecken.
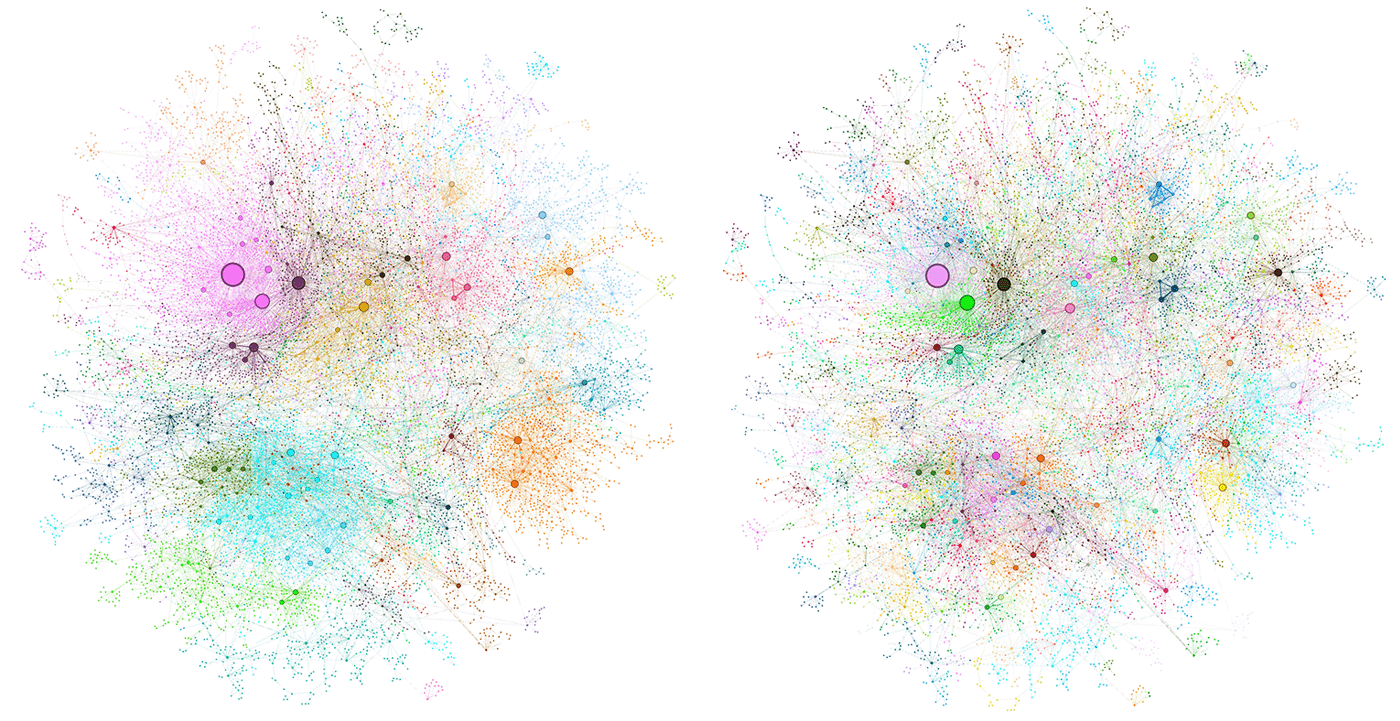
Der Graph-RAG-Ansatz unterscheidet sich von traditionellem RAG, indem er die Modularität von Wissensgraphen (Knowledge Graphs) und die Leistungsfähigkeit von LLMs miteinander kombiniert. In der Folge zeigt es sich wesentlich leistungsfähiger, etwa bei einer solchen Frage: "Welche Personen des öffentlichen Lebens werden in verschiedenen Unterhaltungsartikeln genannt?"

Die Vorbereitung beginnt mit der Extraktion von Textschnipseln (Chunks) aus Quelldokumenten und der Verwendung eines LLMs zur Identifizierung von Entitäten und Beziehungen innerhalb jedes Schnipsels. Eine Entität in einem Wissensgraph könnten etwa Personen, Unternehmen oder Orte sein.
Antworten werden gruppenweise vorbereitet
Um eine Nutzer:innenabfrage zu beantworten, bereitet das System gruppenweise Zusammenfassungen vor und generiert parallele Zwischenantworten für jeden Chunk. Diese Antworten reduziert es dann in einer letzten Runde der abfragefokussierten Zusammenfassung auf eine finale Antwort. Laut den Autor:innen von Microsoft ist dieser Ansatz effizienter als die direkte Zusammenfassung von Quelltexten, da jede Abfrage weniger Kontexttokens benötigt.
Auch um übergeordnete Themen in einer Datenbasis festzustellen, eignet sich Graph RAG den Tests von Microsoft nach optimal, wie das folgende Beispiel zeigt. Die Antworten sind umfangreicher als bei normalem Vektor-RAG, gleichzeitig ermöglichen Quellenangaben, die Behauptungen leichter zu evaluieren.

Vorteile für Modelle und Menschen
Großer Vorteil von Wissensgraphen gegenüber Vektordatenbanken ist außerdem, dass Menschen sie leichter erforschen und um neue Inhalte ergänzen können. Während vortrainierte Sprachmodelle gerne halluzinieren und sich nicht nachvollziehen lässt, woher welche Information stammt, könnte diese Mischung aus LLM und Wissensgraph als externe Informationsbasis einen wichtigen Beitrag dazu liefern, dass sich KI-Antworten besser überprüfen lassen.
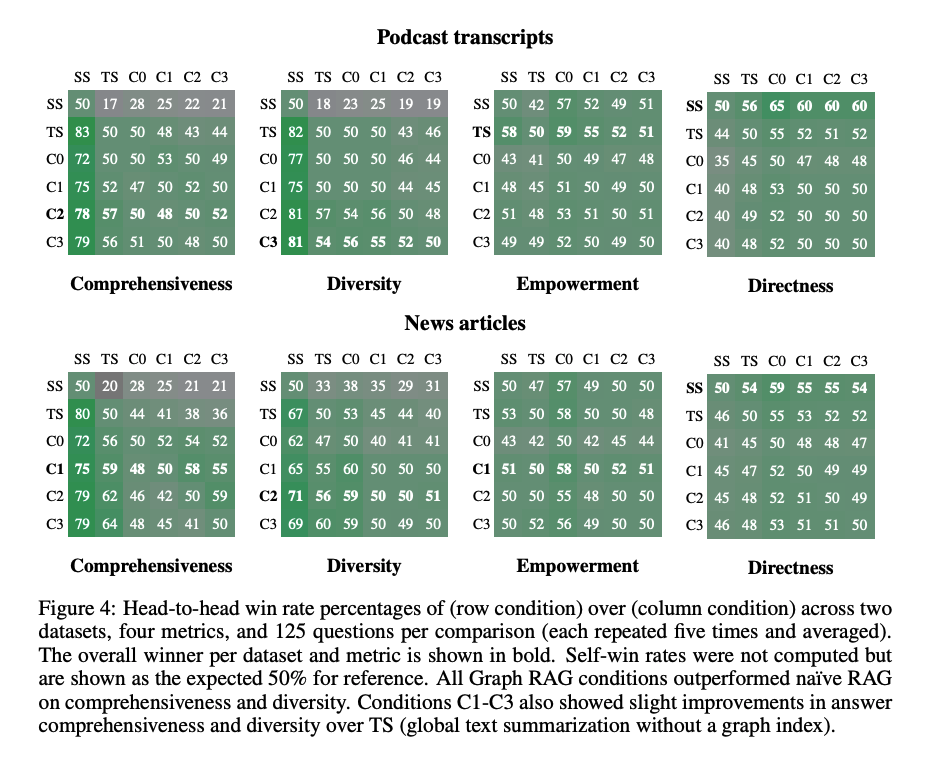
Die Forscher:innen evaluierten ihren Ansatz anhand von zwei Datensätzen, die für Korpora realer Anwendungsfälle repräsentativ sind: Podcast-Transkripte und Nachrichtenartikel. Sie generierten zunächst Fragen mit einem LLM und verglichen die Leistung von Graph RAG auf verschiedenen Zusammenfassungsebenen mit einem herkömmlichen RAG-Ansatz. Die Benchmarks zeigten, dass alle globalen Ansätze die traditionellen Methoden in Bezug auf Vollständigkeit und Vielfältigkeit übertrafen.
Graph RAG auf GitHub und Azure
Microsoft hat Graph RAG als Python-Implementierung Anfang Juli auf GitHub sowie in Azure veröffentlicht. Unabhängige, ausführliche Untersuchungen des Frameworks stehen daher noch aus. Alternativen gibt es etwa von neo4j.
Erste Tests, etwa im Rahmen des Kundensupports von LinkedIn, lassen jedoch bereits erahnen, welches Potenzial die Integration von Wissensgraphen in RAG birgt: Über einen Zeitraum von sechs Monaten sei die benötigte Zeit zum Beantworten von Supportanfragen im Schnitt um knapp 30 Prozent gesunken.
Die Microsoft-Forschenden räumten jedoch auch Einschränkungen in ihrem Evaluierungsansatz ein, da sie Graph RAG lediglich auf Korpora im Bereich von einer Million Token getestet hätten. Text in diesem Umfang hätte theoretisch auch in das Kontextfenster eines einzigen Textprompts gepasst.
Hier kämpfen Sprachmodelle allerdings noch immer mit dem als "Lost in the Middle" bekannten Problem, bei dem Informationen aus langen Dokumenten verloren gehen können. RAG-Systeme haben bereits gezeigt, dass sie dieses Problem abmildern können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.