
Ein neues Training verspricht Verbesserungen bei der Auswertung großer Datenmengen durch Sprachmodelle (LLMs). Außerdem wurde die Leistung großer Kontextfenster von Technologieunternehmen bisher nur unzureichend gemessen.
Das sogenannte Lost-in-the-Middle-Phänomen gehört derzeit zu den gewichtigsten Problemen großer Sprachmodelle (LLMs).
Es beschreibt, dass LLMs zwar Informationen am Anfang und Ende eines langen Kontextes verstehen, aber Schwierigkeiten haben, Informationen in der Mitte des Kontextes zu verarbeiten. Das macht LLMs unzuverlässig bei der Auswertung großer Datenmengen. Genau hier liegt jedoch der Vorteil eines großen Ausgabekontextfensters.
Forscherinnen und Forscher von Microsoft, der Universität Peking und der Xi'an Jiaotong Universität haben nun einen rein datenbasierten Ansatz zur Lösung dieses Problems vorgestellt: das INformation-INtensive (IN2) Training.
Dabei wird ein synthetischer Datensatz verwendet, in dem die Antwort auf eine Frage Informationen aus kurzen Segmenten erfordert, die zufällig in einem langen Kontext platziert sind.
Die Forschenden vermuten, dass die Ursache des Mitten-Problems in einer unbeabsichtigten Verzerrung der Trainingsdaten liegt. Beim Vortraining wird die Vorhersage des nächsten Tokens vor allem durch nahe Tokens beeinflusst und nicht durch weit entfernte Tokens.
Beim Fine-Tuning steht die Systemanweisung, die die Antwortgenerierung stark beeinflusst, meist am Anfang des Kontexts. Das Training führt somit unbewusst einen Positionsbias ein, der suggeriert, dass wichtige Informationen immer am Anfang und am Ende des Kontextes stehen.
IN2 verwendet daher synthetische Frage-Antwort-Daten, um dem Modell explizit zu zeigen, dass wichtige Informationen an jeder Position im Kontext stehen können. Der lange Kontext (4K-32K Tokens) wird mit vielen kurzen Segmenten (128 Tokens) gefüllt. Die Fragen zielen auf Informationen ab, die in diesen zufällig platzierten Segmenten enthalten sind.
Die Forscherinnen und Forscher verwendeten zwei Arten von Trainingsfragen: Fragen, die nach Details in genau einem Segment fragten, um ein detailliertes Informationsbewusstsein zu trainieren, und Fragen, die die Integration und Schlussfolgerung von Informationen aus mehreren Segmenten erforderten.

Mitten-Problem wird gemildert
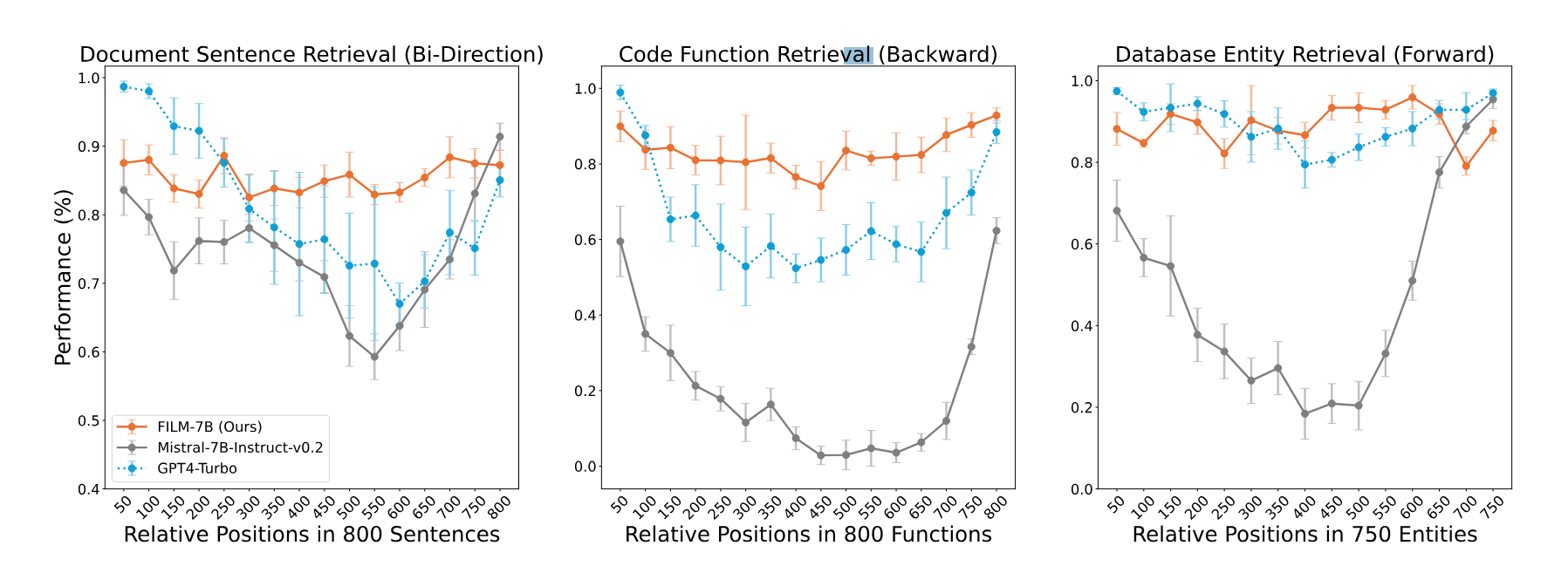
Die Forschenden wendeten IN2 auf Mistral-7B an. Das daraus resultierende FILM-7B (FILl-in-the-Middle) wurde an drei neuen, speziell für lange Kontexte konzipierten Extraktionsaufgaben getestet, die verschiedene Kontexttypen (Dokument, Code, strukturierte Daten) und Suchmuster (vorwärts, rückwärts, bidirektional) abdecken.
Die Ergebnisse zeigen, dass IN2 das "Lost-in-the-Middle"-Problem des ursprünglichen Mistral-Modells signifikant reduziert. Darüber hinaus erreicht FILM-7B als wesentlich kleineres Modell eine vergleichbare oder sogar robustere Leistung als proprietäre Modelle wie GPT-4 Turbo mit 128K.
Darüber hinaus verbessert sich FILM-7B auch signifikant bei realen Aufgaben mit langem Kontext, wie Zusammenfassungen langer Texte. Das Training mit synthetischen Daten scheint also gut auf reale Szenarien übertragbar zu sein. Gleichzeitig bleiben die Fähigkeiten von FILM-7B bei Aufgaben mit kurzem Kontext auf dem Niveau des ursprünglichen Modells.
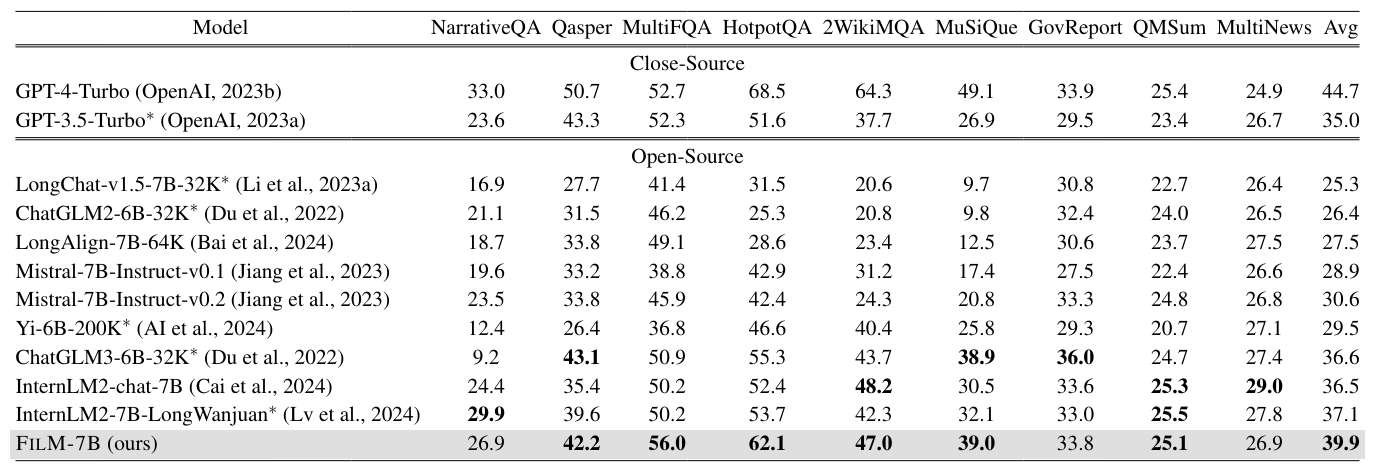
Das Lost-in-the-Middle-Problem ist damit nicht gelöst, wie die Benchmark-Ergebnisse zeigen. GPT-4 Turbo bleibt das stärkste Modell im Kontext-Benchmark, hat aber erhebliche Probleme mit langen Kontexten. Die Frage ist nun, wie gut die IN2-Methode insgesamt und in Bezug auf größere Modelle skaliert und weiterentwickelt werden kann.
Die Forschenden beschreiben auch, dass der weitverbreitete "Needle in the Haystack"-Test, mit dem Firmen wie Microsoft, Google oder OpenAI die Funktion des Kontextfensters demonstrieren wollen, die Kontextfähigkeiten der Modelle falsch darstellt.
Der Test verwende einen dokumentartigen Kontext, mit dem die LLMs durch das Training an Textkorpora sehr vertraut seien. Außerdem vereinfache die vorwärtsgerichtete Informationssuche im Test die Schwierigkeit der Informationssuche in einem langen Kontext, so die Forscher. Der im Paper vorgestellte VAL-Probing-Ansatz sei für die Bewertung der Kontextleistung eines Sprachmodells besser geeignet.




