Kann Künstliche Intelligenz das Training neuronaler Netze übernehmen? Eine neue Forschungsarbeit zeigt, wie diese Zukunft aussehen könnte.
Um eine Künstliche Intelligenz für eine bestimmte Aufgabe einzusetzen, wählen Forschende
- eine Netzwerkarchitektur,
- eine Lernmethode
- und trainieren das neuronale Netz.
In den letzten Jahren fanden verschiedene Varianten einer automatisierten Architektursuche Einzug in diesen Prozess. Dabei suchen Algorithmen, Deep-Learning-Systeme oder Graphennetzwerke nach passenden Netzwerkarchitekturen für eine bestimmte Aufgabe.
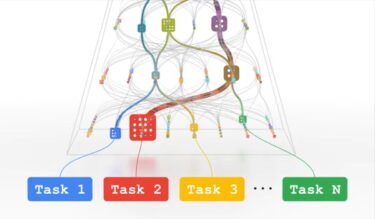
2018 stellten Forschende etwa ein Graphen-Hypernetzwerk (GHN) vor, das ausgehend von einer Reihe Kandidatennetzwerken die beste Architektur für eine Aufgabe wie die Bildanalyse findet. Graphennetzwerke verwenden Graphen statt nacheinander angeordnete Schichten. Die Graphen bestehen aus mehreren Knoten, die miteinander verbunden sind.
Im Hypernetzwerk des Teams um Mengye Ren repräsentiert ein Knoten in der Regel eine ganze Schicht eines neuronalen Netzes und die Verbindungen repräsentieren, wie diese Einheiten miteinander verbunden sind. Trainiert wird das Hypernetzwerk in zahlreichen Durchgängen, in denen es immer neue Netzwerkarchitekturen für eine Ausgabe ausprobiert. Deren Leistung dient als Trainingsfeedback für das Netzwerk.
Können Hypernetzwerke Parameter vorhersagen?
In einer neuen Forschungsarbeit knüpfen Forschende der Universität Guelph, des Vector Institute for AI, Canda CIFAR AI, McGill University und Facebook AI Research nun an Rens Arbeiten an. Die Forschenden erweitern die Fähigkeiten des Hypernetzwerks: Statt ausschließlich Architekturen vorherzusagen, soll das sogenannte GHN-2 auch die Parameter neuronaler Netze prognostizieren.
Neuronale Netze werden zum Beginn ihres Trainings üblicherweise zufällig initialisiert, die Gewichtungen im Netz erhalten so zufällige Werte. Im Laufe des KI-Trainings werden diese Parameter angepasst, bis das System seine Aufgabe zufriedenstellend erfüllt. GHN-2 soll diese Parameter direkt vorhersagen und so den Lernprozess überflüssig machen oder stark verkürzen. Dafür wurde GHN-2 mit einem Datensatz (DeepNets-1M) einer Million verschiedener Netzwerkarchitekturen trainiert.
Für das Training initialisiert GHN-2 die Parameter für einige mögliche Netzwerkarchitekturen für die Bildanalyse. Die Bildanalyse-Systeme werden anschließend mit Bildern getestet.
Doch statt das Testfeedback zu nutzen, um die Parameter des Bildanalyse-Systems zu aktualisieren, aktualisieren die Forschenden stattdessen direkt die Parameter des Hypernetzwerkes, das anschließend erneut die Parameter des Bildanalyse-Systems initialisiert. So lernt GHN-2 im Laufe des Trainings, immer besser zu initialisieren und das für zahlreiche Architekturvarianten.
GHN-2 verkürzt den Trainingsprozess
Die Forschenden testeten GHN-2 für die CIFAR-10- und ImageNet-Bildanalyse mit 500 Netzwerkarchitekturen, darunter solche, die nicht im Trainingsdatensatz enthalten sind. Bei CIFAR-10 erreichten Architekturen, die GHN-2 bereits kennt, nach der Initialisierung und ohne weiteres Training eine Genauigkeit von 66,9 Prozent. Netzwerke, die ohne GHN-2 komplett neu trainiert wurden, erreichten nach 2.500 Iterationen eine Genauigkeit von 69,2 Prozent. Für bisher ungekannte Architekturen wie ResNet-50 erreichte GHN-2 im Schnitt knapp 60 Prozent Genauigkeit.
Im ImageNet-Benchmark schnitt GHN-2 deutlich schlechter ab: Im Schnitt lag die Genauigkeit bei 27,2 Prozent, in Einzelfällen auch bei knapp 50 Prozent. Doch auch neu trainierte Systeme benötigen etwa 5000 Iterationen für eine Genauigkeit von 25,6 Prozent. Beide Systeme lassen sich mit weiterem Training auf die üblichen Genauigkeiten jenseits der 90 Prozent heben.
Auch wenn das Hypernetzwerk klassisches Training bisher nicht ersetzen kann, zeigen die Ergebnisse, dass der Ansatz funktioniert und bereits jetzt Zeit und Energie spart: GHN-2 sagt passende Parameter in unter einer Sekunde hervor, selbst auf einer CPU. Vergleichbare Ergebnisse etwa in ImageNet könne auf einer GPU mehrere Stunden benötigen.
Die Forschenden wollen den Ansatz jetzt ausbauen und ein Hypernetzwerk mit noch mehr Aufgaben wie Sprachverarbeitung und weiteren Architekturen trainieren. Langfristig könne das Projekt so Deep Learning auch für Forschende ohne Zugriff auf massig Rechenleistung ermöglichen, so das Team.
Vortrainierte GHN-2-Modelle und den DeepNets-1M-Datensatz gibt es auf Github.