Inception Labs präsentiert diffusionsbasierte Sprachmodelle "Mercury"

Das Start-up Inception Labs kündigt mit den Mercury-Modellen eine neue Generation von Large Language Models an, die auf der Diffusionstechnologie basieren und eine Geschwindigkeitssteigerung um den Faktor 10 versprechen. Die ersten Modelle sind auf Coding spezialisiert.
Im Gegensatz zu aktuellen Large Language Models, die Text autoregressiv, das heißt, sequentiell von links nach rechts generieren, arbeiten Diffusionsmodelle mit einem "grob-zu-fein"-Ansatz. Dabei wird die Ausgabe ausgehend von reinem Rauschen über wenige Verfeinerungsschritte generiert.
Für die gleiche Aufgabe benötigt Mercury Coder im Vergleich zu einem autoregressiven Modell deutlich weniger Durchläufe. | Video: Inception Labs
Dieser nicht-sequentielle Ansatz ermögliche es laut Inception Labs Diffusionsmodellen, besser zu schlussfolgern, ihre Antworten zu strukturieren und Fehler zu korrigieren. In anderen Bereichen wie Bild- und Videogenerierung ist Diffusion bereits der Standard, nur bei Text und Audio konnte sich der Ansatz bisher nicht durchsetzen.
Über chat.inceptionlabs.ai lässt sich Mercury Coder kostenfrei ausprobieren. Prompts werden innerhalb weniger Augenblicke umgesetzt, in einer Seitenleiste erscheint parallel eine interaktive Vorschau der generierten Software.
Beeindruckende Ergebnisse in Standardtests
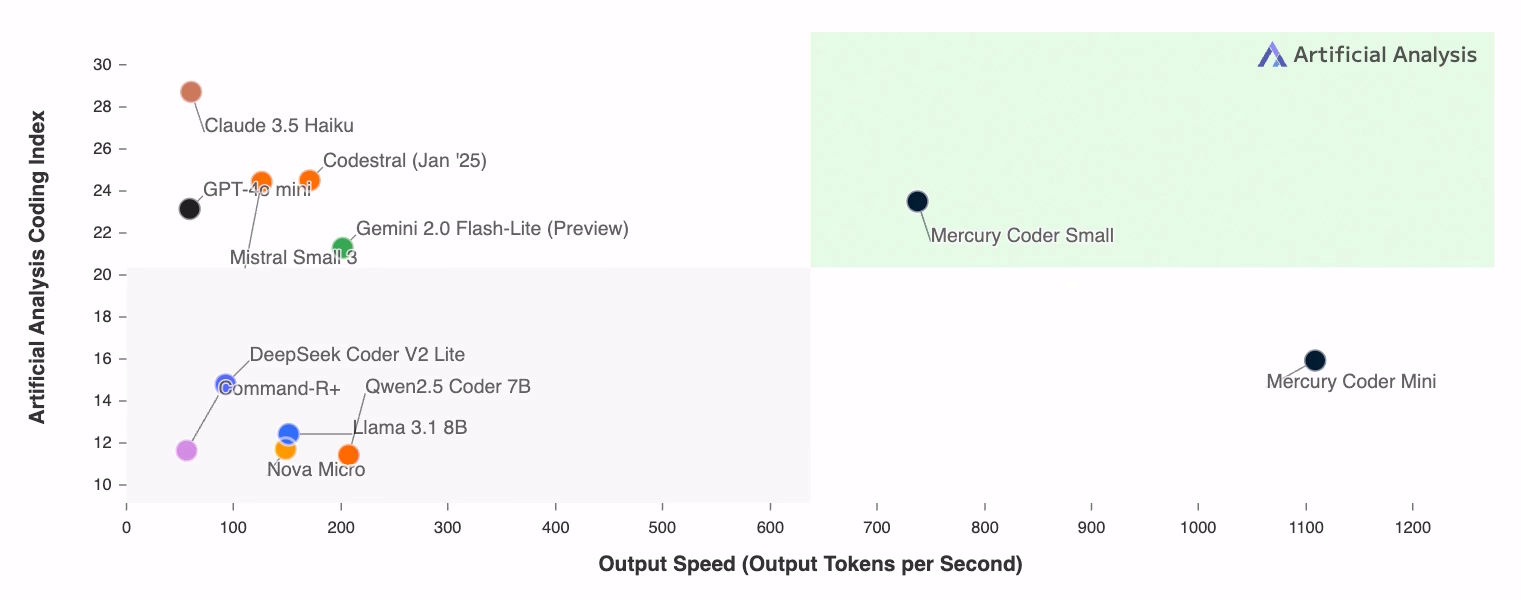
In Standardtests zur Codegenerierung ist Mercury Coder auf einer Ebene mit der Leistung von autoregressiven Modellen wie Gemini 2.0 Flash-Lite oder GPT-4o-mini, aber selbst auf handelsüblichen Nvidia-H100-GPUs um ein Vielfaches schneller. Sie erreichen teilweise Ausgaben mit mehr als 1.000 Token pro Sekunde.
Diese Geschwindigkeiten waren zuvor mit autoregressiver Architektur nur mit für die KI-Inferenz optimierten Chips wie solchen von Groq erreichbar. Auch Entwickler:innen bevorzugen laut Inception Labs die Code-Vervollständigungen von Mercury im Vergleich zu existierenden Code-Modellen.
Das Unternehmen sieht großes Potenzial für dLLMs in Bereichen wie Kundensupport, Codegenerierung und Unternehmensautomatisierung. Erste Anwender:innen würden bereits erfolgreich ihre bisherigen autoregressiven Basismodelle erfolgreich durch Mercury ersetzen. Ein Chat-Modell befindet sich in der geschlossenen Betaphase.
KI-Experte Karpathy zeigt sich überrascht
Der renommierte KI-Experte und ehemals hochrangiger OpenAI-Forscher Andrej Karpathy zeigt sich auf X beeindruckt von Mercury. Warum Text und manchmal auch Audio-Token einen autoregressiven Ansatz bevorzugen, während Bilder und Videos auf Diffusion setzen, sei für ihn und viele andere bisher ein Rätsel gewesen.
"Wenn man genau hinschaut, tauchen viele interessante Verbindungen zwischen den beiden auf", schreibt Karpathy. Das Mercury-Modell habe das Potenzial, anders zu sein und möglicherweise eine neue, "einzigartige Psychologie oder neue Stärken und Schwächen zu zeigen".
Das zur Codegenerierung optimiertes Modell namens Mercury Coder ist bereits in einem Playground verfügbar. Unternehmenskund:innen erhalten auf Anfrage Zugriff auf Mercury Coder Mini und Mercury Coder Small über eine API oder Deployment über ihre lokale Infrastruktur. Die Preisgestaltung ist noch nicht öffentlich bekannt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.