KI-Methode "Dream3D" erzeugt detaillierte 3D-Objekte aus Text
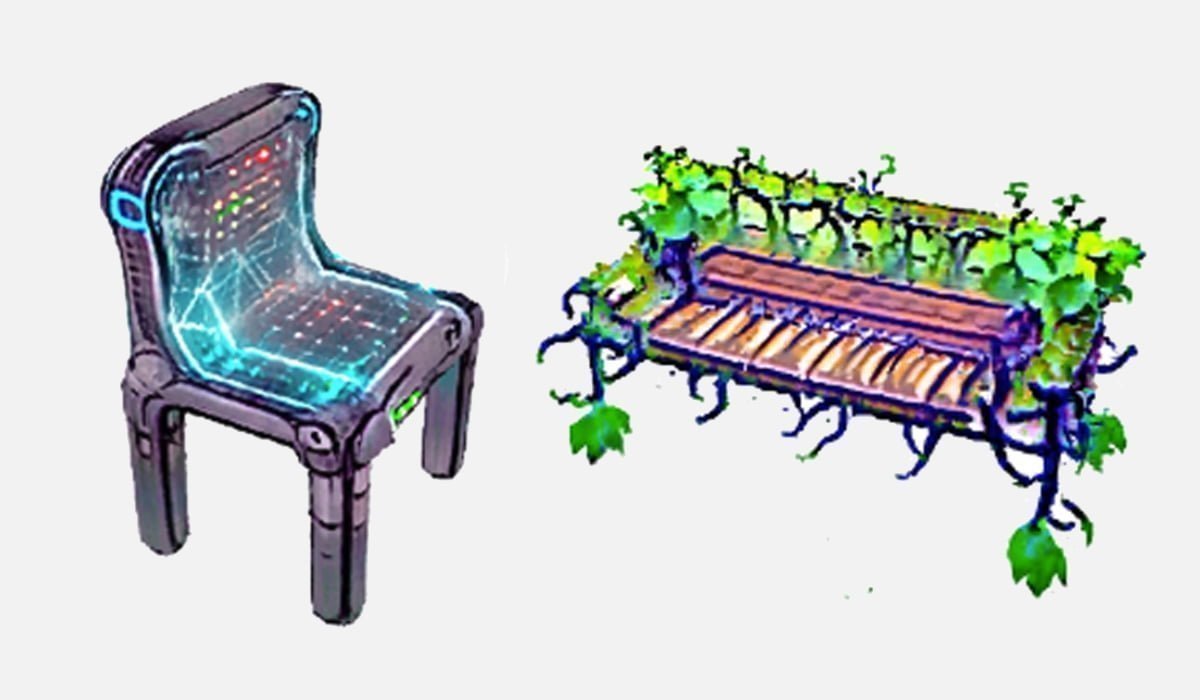
Dream3D ist ein Text-zu-3D-Modell, das mit Stable Diffusion, CLIP und NeRFs detaillierte 3D-Objekte aus Text erzeugt.
Generative KI-Modelle für 3D sind spätestens seit Ende 2021 ein wichtiger Forschungsschwerpunkt: Im Dezember 2021 zeigte Google Dream Fields, ein generatives KI-Modell, das OpenAIs CLIP mit Neural Radiance Fields (NeRF) kombiniert. Durch die Methode können aus Text-Beschreibungen 3D-Formen synthetisiert werden. CLIP leitet dafür ein zufällig initialisiertes NeRF-Netz an, eine passende interne Repräsentation der Text-Beschreibung zu bilden.
Knapp ein Jahr später zeigten Forschende der Concordia University aus Kanada die verwandte Methode CLIP-Mesh, die allerdings auf NeRFs verzichtet. Im selben Monat zeigte Google zudem Dreamfusion, eine deutlich verbesserte Version von Dream Fields, die auf Googles großes Bildmodell Imagen statt CLIP setzt. Von Nvidia gibt es GET3D und von OpenAI Point-E.
Dream3D kombiniert CLIP, Stable Diffusion und NeRFs für detaillierte Modelle
Eine neue Arbeit von Forschenden des ARC Lab, Tencent PCG, der ShanghaiTech University, des Shanghai Engineering Research Center of Intelligent Vision and Imaging und des Shanghai Engineering Research Center of Energy Efficient and Custom AI IC zeigt jetzt Dream3D, ein generatives Text-zu-3D-Modell, das CLIP, Stable Diffusion, einen 3D-Generator und NeRFs kombiniert.
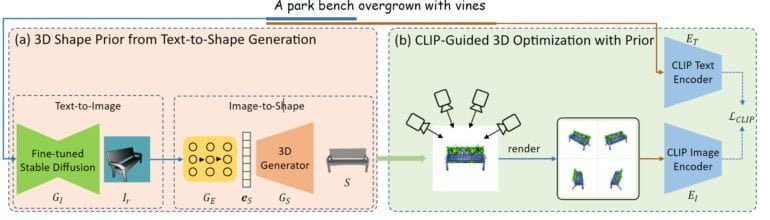
Eine Text-Eingabe wird bei Dream3D zuerst an ein feinjustiertes Stable-Diffusion-Modell weitergeleitet, um ein Bild im Rendering-Stil zu synthetisieren. Dieses Bild wird dann von einem weiteren Modell in eine 3D-Form umgewandelt.
Anders als bei anderen Methoden wird in diesem Prozess nur der für die zentrale Form relevante Teil der Text-Eingabe verwendet: Von "Eine von Ranken überwucherte Parkbank" wird etwa lediglich "Eine Parkbank" verwendet.
Die so entstandene 3D-Form wird dann für die Initialisierung des NeRF-Netzes verwendet, das anschließend wie bei anderen Methoden per CLIP-Anleitung und der kompletten Text-Eingabe optimiert wird.
Dream3D gehört zu den aktuell besten Methoden
Dream3D hängt laut des Teams ältere Methoden wie Dream Fields, PureCLIPNeRF oder CLIP-Mesh deutlich ab. Tatsächlich sind die gezeigten NeRF-Renderings detailliert und passen zu den Text-Eingaben.
"A car is burning." | Video: Xu, Wang, Gao et al.
"The Iron Throne in Game of Thrones." | Video: Xu, Wang, Gao et al.
"A minecraft car." | Video: Xu, Wang, Gao et al.
Der Vorteil, den die Initialisierung des NeRFs mit der erzeugten 3D-Form bietet, ist deutlich zu sehen. Einen direkten Vergleich mit Googles jüngster Dreamfusion-Methode nimmt das Team allerdings nicht vor.

Doch die Nutzung der 3D-Formen als Prior für das NeRF schränken Dream3D auch ein:
Trotz der starken Generierungsfähigkeit von Stable Diffusion können wir nicht verhindern, dass Bilder erzeugt werden, die außerhalb der Verteilung des 3D-Formgenerators liegen, da Stable Diffusion auf einem großen Text-Bild-Datensatz trainiert wird, während der 3D-Formgenerator nur eine begrenzte Anzahl von Formen erzeugen kann. Außerdem hängt die Qualität der Text-zu-Formen-Synthese in unserem System stark von der Generierungsfähigkeit des 3D-Generators ab.
Aus dem Paper
Die Forschenden hoffen, dass sie in Zukunft bessere 3D-Priors in das System einführen und so die Funktion von Dream3D auf mehr Objektkategorien ausweiten können. Mehr Beispiele und demnächst auch den Code gibt es auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.