KI-Modelle verstehen zwar Fotos, können aber die Uhr nicht lesen

Bei manchen Aufgaben ziehen KI-Modelle mit menschlichen Fähigkeiten gleich oder übertreffen sie sogar - bei manchen zeigen sich hingegen noch große Lücken, wie etwa dem Verständnis abstrakter Grafiken.
Große Sprachmodelle sind über die letzten Jahre zunehmend multimodal geworden, können außer reinem Text also etwa Bilder, Sprache und Videos in einem Prompt verarbeiten. Während die Modelle bei der Verarbeitung von Fotos natürlicher Szenen oder Porträts gut abschneiden, zeigen sich laut Forscher:innen der chinesischen Zhejiang Universität erhebliche Defizite beim Verständnis abstrakter Bilder wie Diagrammen oder Tabellen. Gerade diese Fähigkeit dürfte jedoch beim Einsatz generativer KI in vielen beruflichen Anwendungsfeldern nützlich sein.
Die Forschenden haben eine "multimodale Self-Instruct"-Strategie entwickelt, um einen vielfältigen Datensatz von 11.193 abstrakten Bildern und zugehörigen Fragen zu synthetisieren, die acht gängige Szenarien abdecken: Dashboards, Straßenkarten, Diagramme, Tabellen, Flussdiagramme, Beziehungsgraphen, visuelle Rätsel und 2D-Grundrisse. Damit Fragen und Grafiken möglichst genau zusammenpassen, nutzten sie einen codezentrierten Ansatz zur Visualisierung mithilfe von Python-Bibliotheken wie Matplotlib.
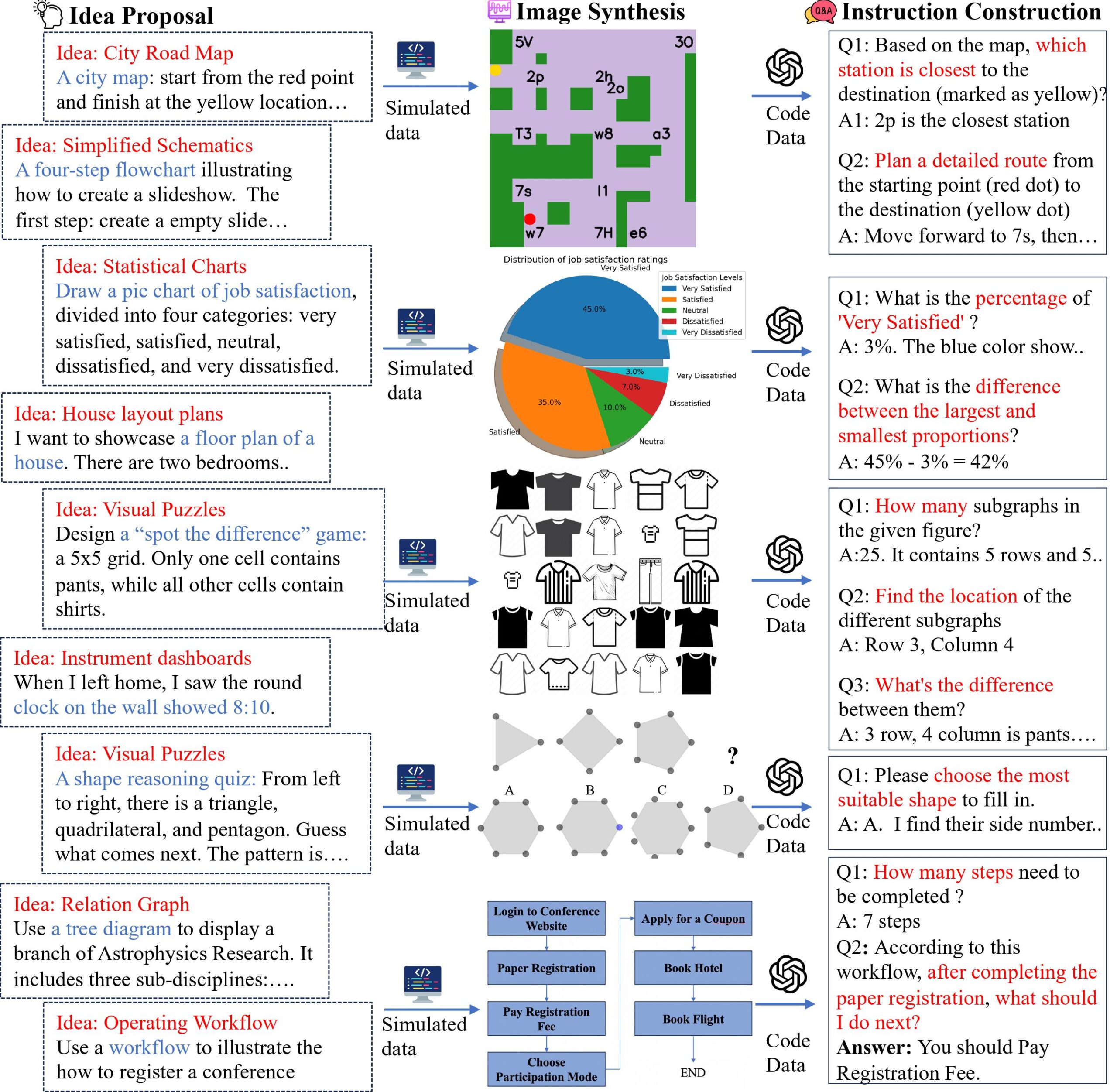
Beim Benchmarking gegen diesen Datensatz erreichten selbst fortschrittliche LMMs wie GPT-4o und Claude 3.5 Sonnet im Durchschnitt nur eine Genauigkeit von 64,7 Prozent oder 59,9 Prozent bei allen Aufgaben - deutlich unter der menschlichen Leistung von (immerhin) 82,1 Prozent. GPT-4o und Claude 3.5 stellen aktuellen Tests zufolge die beiden besten Sprachmodelle mit visuellem Verständnis dar.
"Weit von menschlicher Leistung entfernt"
"Unsere Benchmarks zeigen, dass die aktuellen LMMs weit von menschlicher Leistung entfernt sind", konkludieren die Forscher:innen. "Sie scheitern sogar bei der Bewältigung einfacher täglicher Aufgaben, etwa dem Ablesen der Uhrzeit auf einer Uhr oder der Planung einer Route anhand einer Karte."

Beispielsweise erreichte GPT-4o bei der Dashboard-Aufgabe, bei der das Modell Uhren und Messgeräte ablesen sollte, nur eine Genauigkeit von 54,8 Prozent. Die Modelle hatten auch Schwierigkeiten mit räumlichen Beziehungen in Grundrissen und machten Fehler im Umgang mit abstrakten Konzepten in Diagrammen und Graphen.
Open-Source-Modelle noch weiter abgeschlagen
Der Benchmark offenbarte außerdem eine große Leistungslücke zwischen geschlossenen Modellen wie GPT-4 und quelloffenen LMMs, die bei visuellen Reasoning-Aufgaben besonders ausgeprägt war. Bei den Aufgaben zur Straßenkartennavigation und zu visuellen Puzzles, die dynamische Wegplanung und Musterinduktion erforderten, erzielten Modelle wie Claude 3.5 Sonnet eine Genauigkeit von bis zu 62 Prozent. Kleinere, quelloffene Modelle erreichten hingegen weniger als 20 Prozent.
Um zu testen, ob synthetische Daten die Leistung von LMMs verbessern können, haben die Forscher das Open-Source-Modell Llava-1.5-7B auf 62.476 Diagramm-, Tabellen- und Straßenkartenanweisungen verfeinert. Dadurch erhöhte sich seine Genauigkeit bei der Straßenkartenaufgabe auf 67,7 Prozent und übertraf damit GPT-4V mit 23,3 Prozent.
Der entwickelte Ansatz ist auf geschlossene Modelle wie GPT-4o angewiesen, um hochwertige Referenzdaten zu synthetisieren, was zu hohen Kosten führt. In Zukunft wolle man jedoch auf quelloffene LLMs wie LLaMA 3 oder DeepSeek-V2 setzen.
Neben den acht Szenarien von Dashboard bis Grundriss wollen die Forschenden außerdem weitere Anwendungsfelder erschließen. Schließlich sehen sie eine starke Beschränkung der multimodalen Sprachmodelle in der Auflösung des visuellen Encoders, die die Wissenschaftler:innen künftig erhöhen wollen.
Nicht nur dieser Test zeigt, dass die Bildverarbeitung von großen Sprachmodellen teilweise noch unzureichend ist. Insbesondere das Herausfiltern bestimmter Bilddaten aus großen Bildmengen stellt eine Herausforderung dar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.