KI-System rekonstruiert Sprache aus fMRT-Daten

Forschende zeigen ein KI-System, das aus fMRT-Daten semantische Inhalte in Form von Text rekonstruieren kann.
Ein Gehirn-Computer-Interface, das Sprache rekonstruiert, hätte zahlreiche Anwendungen in der Wissenschaft, Medizin und Industrie. Dass eine solche Rekonstruktion und simple Gedankensteuerung möglich ist, zeigen invasive Methoden, die Aufnahmen aus chirurgisch implantierten Elektroden verwenden.
Doch solche Eingriffe sind noch immer gefährlich, auch wenn Unternehmen wie Elon Musks Neuralink an Methoden arbeiten, solche Eingriffe möglichst harmlos und ohne Folgeschäden zu gestalten. Nicht-invasive Sprach-Decoder könnten jedoch auf breiter Basis eingesetzt werden und in Zukunft etwa Menschen helfen, technische Geräte per Gedanken zu steuern.
Forschende trainieren KI-System mit 16 Stunden fMRT-Aufnahmen pro Person
Erste Versuche, Sprach-Decoder für nicht invasive Methoden zu trainieren, gibt es etwa von einem Team um Jean-Remi King, CNRS-Forscher an der Ecole Normale Supérieure und Forscher bei Meta AI.
Sein Team zeigte Ende 2021, dass Reaktionen des menschlichen Gehirns auf Sprache anhand der Aktivierungen eines GPT-Sprachmodells vorhersagbar sind. Im Juni 2022 zeigte das Team Korrelationen zwischen einem mit Sprachaufnahmen trainierten KI-Modell und fMRT-Aufnahmen von mehr als 400 Personen, die Hörbücher hören.
Kürzlich zeigte Kings Team dann ein KI-System, das aus MEG- und EEG-Daten vorhersagen kann, welche Wörter ein Mensch gehört hat. Eine neue Arbeit von Forschenden der University of Texas at Austin reproduziert dieses Ergebnis jetzt für fMRT-Aufnahmen. In ihrer Arbeit zeigt das Team um Autor Jerry Tang einen fMRT-Decoder, der verständliche Wortfolgen von wahrgenommener Sprache rekonstruiert.
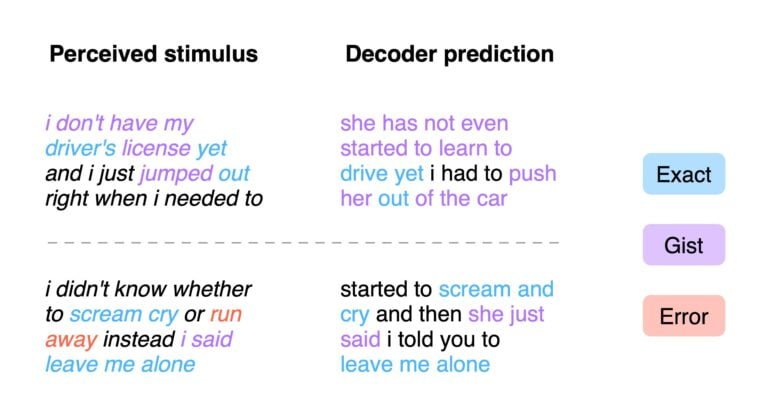
Für das Training des KI-Systems zeichnete das Team fMRT-Daten dreier Personen auf, die 16 Stunden lang Erzählungen zuhörten. Für jede Person wurde anhand der Daten ein Encoding-Modell erstellt, um die Hirnreaktionen anhand der semantischen Merkmale von Stimuluswörtern vorherzusagen.
Um Sprache aus den Gehirndaten zu rekonstruieren, sagt der Decoder eine Reihe von möglichen Wortsequenzen zu einem Dateninput vor. Werden neue Wörter in den darauffolgenden Dateneingaben erkannt, schlägt ein Sprachmodell Fortsetzungen für jede Sequenz vor. Das Encoding-Modell bewertet die Wahrscheinlichkeit der Vorhersagen. Die wahrscheinlichsten Fortsetzungen werden beibehalten.
KI-System kann semantische Inhalte von Stummfilmen rekonstruieren
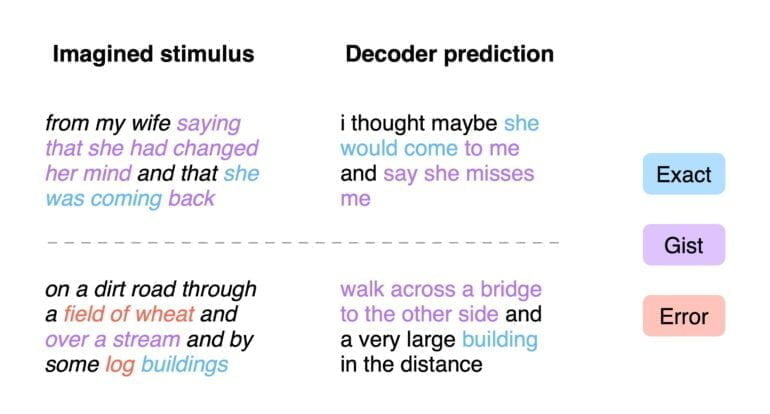
Die Forschenden testeten ihr System neben der Rekonstruktion von wahrgenommener Sprache auch mit der Rekonstruktion interner Sprache: Die Versuchspersonen erzählten sich selbst im Kopfe eine kurze Geschichte, die das KI-System rekonstruieren sollte. In beiden Tests lag die Qualität der Vorhersagen deutlich über Zufall.
"Die Ergebnisse zeigen, dass die dekodierten Wortfolgen nicht nur die Bedeutung der Stimuli wiedergeben, sondern oft sogar die exakten Wörter und Phrasen wiederherstellen", so das Team.
Die Qualität der Vorhersage blieb auch über verschiedene gemessene Hirnareale stabil. Laut den Forschenden ist das ein Hinweis, dass das Gehirn die semantischen Informationen an mehreren Stellen verarbeitet.
Um die Grenzen des Ansatzes zu testen, zeigte das Team den Versuchspersonen einen Film ohne Audio und ließ das KI-System die gemessene Aktivität in Sprache übersetzen. Die so vom System wiedergegebenen semantischen Inhalte weisen eine hohe Übereinstimmung mit den auf dem Bildschirm sichtbaren Ereignissen auf.
we pushed the limits of this zero-shot transfer by testing the decoder on brain responses while subjects watched silent movies, and found that the decoder accurately described many movie events. this suggests that our decoder can transfer to non-linguistic semantic tasks! (5/7) pic.twitter.com/z2wyWiOqv5
— Jerry Tang (@jerryptang) September 30, 2022
Respektiert ein Gehirnlese-System Privatsphäre?
Von einer perfekten Rekonstruktion der semantischen Inhalte oder gar der Sprache ist das KI-System des Teams noch weit entfernt. Die Forschenden spekulieren, dass in der Zukunft bessere Decoder die Ungenauigkeiten auflösen könnten. Sie könnten etwa durch eine Kombination aus semantischen Merkmalen und Merkmalen auf niedrigerer Ebene wie Phonemen oder Akustik Sprachstimuli modellieren.
Ein Kandidat für eine bessere Decoder-Leistung sei zudem Subjekt-Feedback: "In früheren invasiven Studien wurde ein Dekodierungsparadigma mit geschlossenem Regelkreis verwendet, bei dem die Dekodierungsvorhersagen der Versuchsperson in Echtzeit angezeigt werden", heißt es im Paper. "Dieses Feedback ermöglicht es der Versuchsperson, sich an den Decoder anzupassen, und gibt ihr mehr Kontrolle über die Decoderausgabe."
In einem Teil der Arbeit setzt sich das Team zudem mit Gefahren der Technologie auseinander. In ihren Experimenten konnten sie zeigen, dass die gezeigte Methode die Kooperation der Testpersonen für Training und auch Nutzung des Decoders benötigt.
Zukünftige Entwicklungen könnten es jedoch Decodern ermöglichen, diese Anforderungen zu umgehen, warnen die Forschenden. Zusätzlich könnten auch ungenaue Ergebnisse absichtlich für böswillige Zwecke fehlinterpretiert werden.
Es sei daher von entscheidender Bedeutung, das Bewusstsein für die Risiken solcher Dekodierungstechnologien für das menschliche Gehirn zu schärfen und Maßnahmen zu ergreifen, die die mentale Privatsphäre jedes Einzelnen schützen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.