KI-Fortschritt: Gehen uns die Benchmarks aus?

Benchmarks sind in der KI-Forschung eine wichtige Methode, um Fortschritt zu messen - doch Künstliche Intelligenz erzielt stetig neue Bestwerte. Gehen uns die KI-Benchmarks aus?
Benchmarks für Künstliche Intelligenz sind eng mit der KI-Forschung verknüpft: Sie stellen Mess- und Vergleichbarkeit her und werden in vielen Fällen sogar zum Forschungsziel. KI-Benchmarks steuern so - zumindest teilweise - den KI-Fortschritt.
Erfolge von künstlichen neuronalen Netzen im ImageNet-Benchmark gelten etwa als Auslöser des KI-Booms der letzten Jahre: Die Ergebnisse zeigten das Potenzial der Technologie und führten zu verstärkten Investitionen in weitere Forschung. Sie sind also ein zentrales Element für die weitere Entwicklung Künstlicher Intelligenz.
Was tun, wenn die Benchmarks ausgehen?
Noch heute nimmt der ImageNet-Benchmark eine zentrale Rolle in der Forschung ein: Neue Modelle, wie Googles Vision Transformer, die auf Transformer-Architekturen und selbstüberwachtes Lernen für die Bildanalyse setzen, werden mit ImageNet-Methoden verglichen.
Diese Abhängigkeit von Benchmarks zur Fortschrittsbestimmung wird dann ein Problem, wenn in einem Benchmark laufend Bestwerte erzielt werden und es keinen qualitativ hochwertigen Nachfolge-Benchmark gibt.
Ein Beispiel für die rasante Geschwindigkeit in der KI-Forschung lieferten Google und Microsoft Anfang 2021: Forschende unter anderem von Deepmind und Facebook stellten im August 2019 den Sprach-Benchmark SuperGLUE vor, der den bereits überholten GLUE-Benchmark ablösen sollte.
Nur knapp ein Jahr später erreichten KI-Systeme von Google und Microsoft Bestwerte noch über den menschlichen Vergleichswerten. Effektiv ist der SuperGLUE-Benchmark somit überholt.
33 Prozent der KI-Benchmarks werden nicht genutzt
Forschende der Medizinischen Universität Wien und der University of Oxford zeigen nun in einer Meta-Studie über KI-Benchmarks, dass gesättigte oder stagnierende Benchmarks häufig vorkommen. Die Forschenden untersuchten 1.688 Benchmarks mit 406 Aufgaben in den Bereichen Computer Vision und der Verarbeitung natürlicher Sprache seit 2013. Sie ziehen folgende Schlüsse:
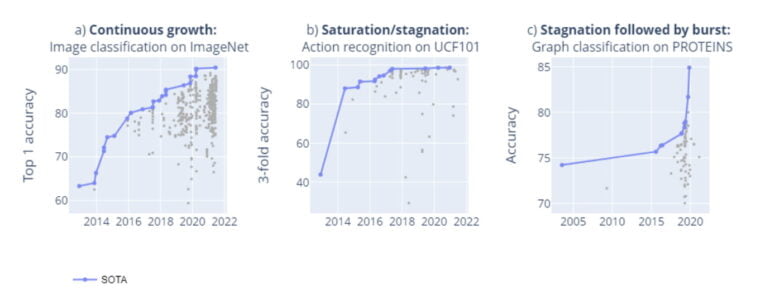
- In einigen Fällen gäbe es ein kontinuierliches Wachstum, wie etwa im ImageNet-Benchmark.
- Ein Großteil aller Benchmarks erreiche jedoch schnell eine technologische Stagnation oder Sättigung.
- In einigen Fällen sei auch mangelndes Forschungsinteresse für eine Stagnation ursächlich. Als Beispiel für eine Sättigung nennen die Forschenden etwa den UCF101-Benchmark zur Aktionserkennung.
- Die Dynamik der Leistungssteigerung folgt jedoch keinem klar erkennbaren Muster: In einigen Fällen folgen auf Phasen der Stagnation unvorhersehbare Sprünge. So geschehen im PROTEINS-Benchmark.
Von 1.688 Benchmarks weisen darüber hinaus nur 66 Prozent mehr als drei Ergebnisse zu verschiedenen Zeitpunkten auf - in der Praxis werden daher 33 Prozent aller KI-Benchmarks nicht genutzt und sind daher nutzlos. Das weise auf den Trend der letzten Jahre hin, dass Benchmarks tendenziell von Datensätzen dominiert werden, die von etablierten Institutionen und Unternehmen erstellt werden.
Qualität statt Quantität für KI-Benchmarks
Während Benchmark-Erfolge für Computer Vision die erste Hälfte des letzten Jahrzehnts bestimmten, sei in der zweiten Hälfte ein Boom bei der maschinellen Verarbeitung natürlicher Sprache festzustellen.
2020 sei die Anzahl neuer Benchmarks zurückgegangen und neue Tests fokussierten sich verstärkt auf höherwertige Aufgaben, die etwa die Fähigkeit zum Schlussfolgern testen sollen. Ein Beispiel für solche Benchmarks sind etwa Googles BIG-bench oder FAIRs NetHack-Challenge.
Der Trend zu Benchmarks von etablierten Institutionen auch aus der Industrie werfe auf der einen Seite Bedenken hinsichtlich Bias und der Repräsentativität der Benchmarks auf.
Gleichzeitig lege jedoch die Kritik an der Gültigkeit vieler Benchmarks zur Erfassung der Leistung von KI-Systemen unter realen Bedingungen nahe, dass die Entwicklung weniger, aber qualitätsgesicherter Benchmarks, die mehrere KI-Fähigkeiten abdecken, wünschenswert sein könne, so die Forschenden.
Neue Benchmarks sollten in Zukunft von großen, kooperativen Teams aus vielen Institutionen, Wissensbereichen und Kulturen entwickelt werden, um eine hohe Qualität der Benchmarks zu gewährleisten und eine Zersplitterung der Benchmark-Landschaft zu vermeiden.
Wer mehr über die Rolle von Benchmarks in der KI-Forschung lernen will, kann sich unseren DEEP MINDS KI-Podcast anhören: In Folge #1 sprechen wir mit Tim Rocktäschel von Meta AI über Reinforcement Learning und die NetHack-Challenge, in Folge #5 mit Sebastian Riedel von Meta AI über Sprache und den Turing-Test.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.