
Google stellt ein neues Text-zu-Video-Modell vor, das alternative Modelle übertrifft und als neuer Standard angesehen werden kann.
Google-Forscher haben ein neues Text-to-Video (T2V) Diffusionsmodell namens Lumiere entwickelt, das in der Lage ist, realistische KI-Videos zu erzeugen, die viele Probleme alternativer Ansätze hinter sich lassen.
Lumiere verwendet eine neue Space-Time U-Net (STUNet) Architektur, die die Erzeugung von Videos mit kohärenten Bewegungen und hoher Qualität ermöglicht. Die Methode unterscheidet sich grundlegend von früheren Ansätzen, die auf einer Kaskade von Modellen basierten, die nur Teilbereiche des Videos gleichzeitig verarbeiten konnten.
Lumiere kann auch für andere Anwendungen wie Video-Inpainting, Bild-zu-Video-Generierung und stilisierte Videos verwendet werden. Das Modell wurde mit 30 Millionen Videos trainiert und zeigt im Vergleich zu anderen Methoden konkurrenzfähige Ergebnisse in Bezug auf Videoqualität und Textübereinstimmung. Das Modell wurde mit 30 Millionen Videos mit zugehörigen Text-Untertiteln trainiert. Die Videos haben eine Länge von 80 Frames bei 16 Frames pro Sekunde (fps) und dauern jeweils 5 Sekunden. Als Basis dient ein vortrainiertes, eingefrorenes Text-zu-Bild-Modell, das um weitere Schichten für videorelevante Aspekte wie die zeitliche Dimension erweitert wurde.
Googles Lumiere setzt auf räumliches und zeitliches Down- und Up-Sampling
Im Gegensatz zu früheren T2V-Modellen, die zunächst Keyframes generieren und dann die fehlenden Bilder zwischen diesen Keyframes mithilfe von Temporal Super-Resolution (TSR)-Modellen einfügen, generiert Lumiere die gesamte Videosequenz auf einmal. Dies ermöglicht kohärentere und realistischere Bewegungen im gesamten Video.
Ermöglicht wird dies durch die STUNet-Architektur, die nicht nur wie bestehende Verfahren die räumliche Auflösung runter- und anschließend hochrechnet, sondern auch die zeitliche Auflösung. Dabei wird die Anzahl der Bilder pro Sekunde in einem Video reduziert und anschließend wieder hochgerechnet. Durch das Downsampling verarbeitet das Modell das Video in dieser reduzierten zeitlichen Auflösung, betrachtet aber weiterhin die gesamte Länge des Videos - nur mit weniger Frames. Auf diese Weise lernt das Modell, wie sich Objekte und Szenen über diese reduzierte Anzahl von Frames hinweg bewegen und verändern.
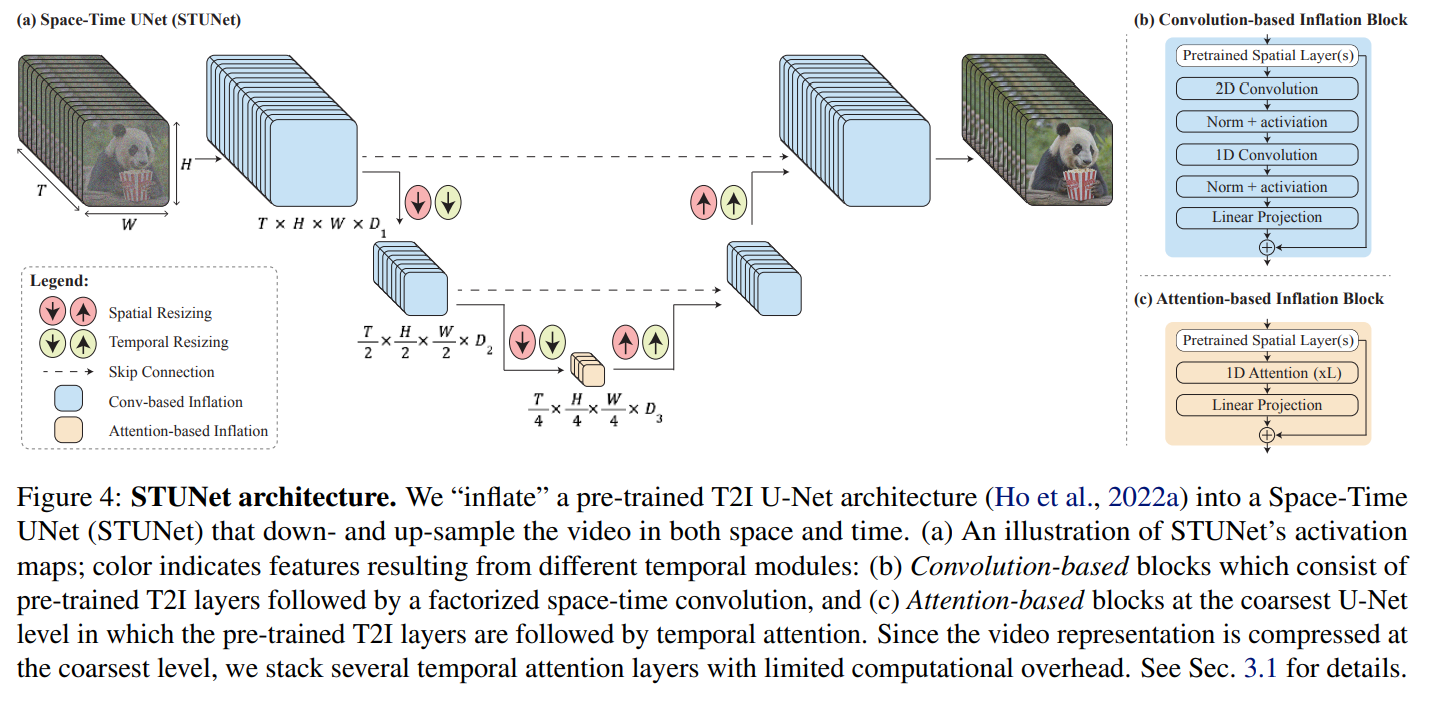
Nachdem das Modell die grundlegenden Bewegungsmuster in dieser reduzierten Auflösung gelernt hat, kann es darauf aufbauen, um die endgültige Videoqualität in voller zeitlicher Auflösung zu verbessern. Dieser Prozess ermöglicht eine effizientere Handhabung des Videos, ohne die Qualität der erzeugten Bewegungen und Szenen zu beeinträchtigen.
Nachdem das Video in dieser niedrigeren zeitlichen und räumlichen Auflösung generiert wurde, verwendet Lumiere Multidiffusion für räumliche Superauflösung (SSR). Dabei wird das Video in sich überlappende Segmente unterteilt und jedes Segment einzeln verbessert, um die Auflösung zu erhöhen. Anschließend werden diese Segmente zu einem kohärenten, hochauflösenden Video zusammengefügt. Dieser Prozess ermöglicht es, Videos in hoher Qualität zu produzieren, ohne die enormen Ressourcen zu benötigen, die für eine direkte Produktion in hoher Auflösung erforderlich wären.
Laut Google übertraf Lumiere in einer Benutzerstudie bestehende Text-zu-Video-Modelle wie Imagen Video, Pika, Stable Video Diffusion und Gen-2. Trotz seiner Stärken bleibt noch viel zu tun: Auch Lumiere ist nicht darauf ausgelegt, Videos mit mehreren Szenen oder Übergängen zwischen Szenen zu erzeugen, was eine Herausforderung für zukünftige Forschung darstellt.

Mehr Beispiele und Informationen gibt es auf der Projektseite von Lumiere.




