KI als Schreibassistenz: Meta will Mensch-Maschine-Kollaboration verbessern

Metas PEER soll die Zusammenarbeit zwischen Mensch und großen Sprachmodellen vereinfachen und diese so für gemeinschaftlich geschriebene Texte erschließen.
Große Sprachmodelle wie OpenAIs GPT-3 zeigen beeindruckende generative Fähigkeiten: Sie können Prosa, Poesie, HTML-Code oder Excel-Tabellen schreiben und ihre Ergebnisse sind teils nicht mehr von menschlichen Texten zu unterscheiden. Solche KI-Modelle generieren ihren Output dabei von links nach rechts - sie ergänzen von Menschen vorgegebenen Input-Text nach gelernten Wahrscheinlichkeiten.
Über den Input-Text lassen sich die Modelle anstoßen: Übersetzungsbeispiele führen zu weiteren Übersetzungen, ein angefangenes Gedicht wird poetisch vollendet und eine Geschichte über die Spannungen zwischen Anarcho-Syndikalismus und klassischen Monarchien wird thematisch fortgeführt.
Große Sprachmodelle sind schwer zu kontrollieren, Meta PEER soll das ändern
Abseits dieses simplen Anstoßes sind die Möglichkeiten, den Output der Modelle zu steuern, stark eingeschränkt. Eine Überprüfung der generierten Texte ist schwierig, da die Modelle oft Inhalte halluzinieren und nicht erklären können, warum sie bestimmte Aussagen produzieren.
Unternehmen wie OpenAI, Google, Meta und andere suchen daher nach Ansätzen, die die Modelle zuverlässiger machen. Google setzt gegen KI-Nonsens etwa auf Faktentraining und OpenAI experimentiert mit Suchmaschinenzugriff.
Trotz solcher Versuche sind aktuelle Sprachmodelle Solisten. Eine Text-Kollaboration mit menschlichen Autor:innen ist nur eingeschränkt möglich.
KI-Forschende von Meta wollen das ändern und stellen jetzt PEER vor. Das Akronym steht für "Plan, Edit, Explain, Repeat" und benennt ein neues kollaboratives Sprachmodell, das mit Bearbeitungsverläufen etwa aus Wikipedia trainiert wurde.
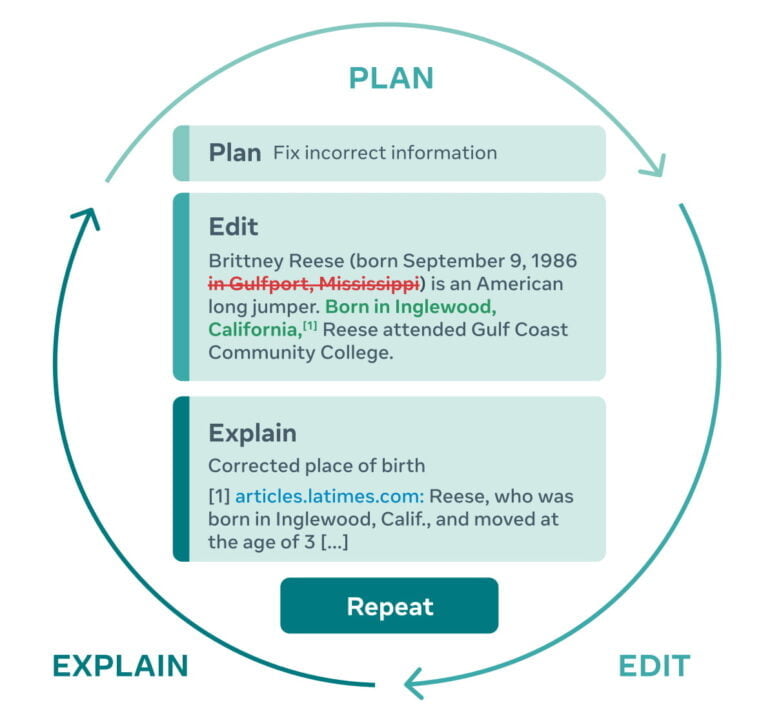
PEER soll so den gesamten Schreibprozess abdecken und etwa Texte editieren und vorgenommene Veränderungen erklären können.
Meta zeigt, wie Kollaboration zwischen Mensch und PEER aussehen könnte
PEER arbeitet dafür in mehreren Schritten, die laut Meta den menschlichen Schreibprozess spiegeln sollen. Für einen gegebenen Text kann ein Mensch oder das KI-Modell einen Plan erstellen, beispielsweise per Text-Eingabe.
Ein solcher Plan kann etwa die Korrektur von im Text enthaltenen Falschinformationen, das Hinzufügen von Quellenangaben oder Formatierungsveränderungen umfassen.
Das Modell kann diese Veränderungen anschließend erklären, etwa mit einem Hinweis auf eine Quelle. Dafür wird jeder Input-Text mit möglicherweise relevanten Hintergrundinformationen versehen, bevor er von PEER weiter verarbeitet wird.

Dieser Prozess kann anschließend beliebig oft von menschlichen Autor:innen wiederholt werden. Dieser iterative Ansatz unterteile die komplexe Aufgabe, einen konsistenten und sachlichen Text zu verfassen, in mehrere einfachere Unteraufgaben, in denen Menschen zudem zu jeder Zeit eingreifen und steuern können.
PEER lernt mit Wikipedia - und ist für Meta erst der Anfang
Für das KI-Training greift Meta auf Wikipedias umfassenden Datensatz von Text-Bearbeitungen und zugehörigen Kommentaren zurück, die oft Erklärungen für diese Veränderungen erhalten.
Damit PEER auch außerhalb von Wikipedia-ähnlichen Texten nützlich ist, lernen Varianten von PEER zudem aus einem fertig editierten Text und dafür relevanten Dokumenten den ursprünglichen, nicht editierten Text zu rekonstruieren. Mit dieser Methode produziert Meta ein KI-Modell, das auch außerhalb der Wikipedia-Domäne nützlich sein soll.
Das drei Milliarden Parameter große PEER schneidet als Schreibassistent besser ab als andere und deutlich größere Sprachmodelle wie GPT-3 oder Metas OPT. Dennoch seien PEERs Fähigkeiten als kollaboratives Sprachmodell bisher nur oberflächlich erkundet worden, so Meta. In Zukunft will das Team komplette Sitzungen von zahlreichen KI-Mensch-Interaktionen sammeln und so PEER verbessern.
Dafür muss das Team zunächst weitere Einschränkungen des Modells lösen. Es muss etwa den Zugang zu einer Retrieval-Engine ermöglichen, die relevante Dokumente selbstständig finden kann. Zudem müssen die Forschenden Methoden zur Auswertung von Texten, die von Menschen und Sprachmodellen gemeinsam verfasst wurden, entwickeln und PEER effizienter machen, um so die Verarbeitung ganzer Dokumente zu ermöglichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.