Microsoft zeigt multimodalen KI-Assistent für die Biomedizin

Forschende von Microsoft zeigen mit LLaVA-Med einen multimodalen KI-Assistenten für die Biomedizin, der neben Text auch Bilder verarbeiten kann.
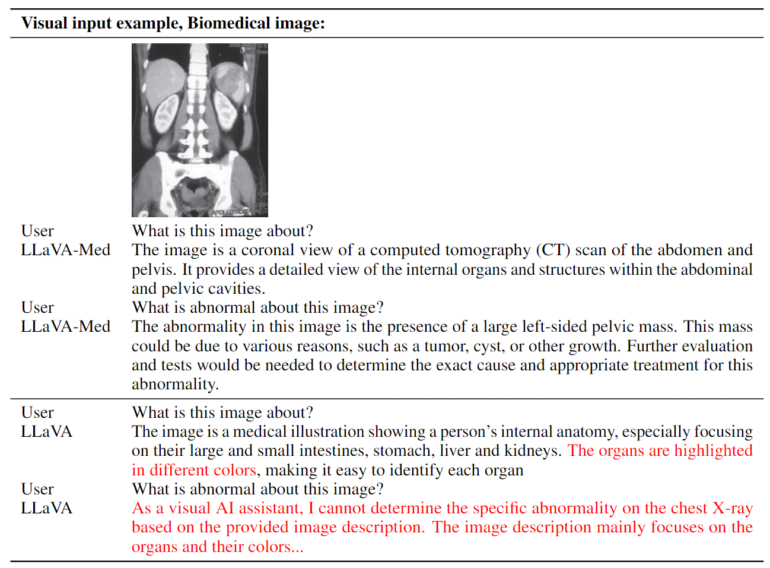
Für das Training des multimodalen KI-Modells wurde ein umfangreicher Datensatz biomedizinischer Bild- und Textpaare verwendet. Der Datensatz umfasst unter anderem Thorax-Röntgenbilder, MRT, Histologie, Pathologie und CT-Bilder. Zunächst lernt das Modell, den Inhalt solcher Bilder und damit wichtige biomedizinische Konzepte zu beschreiben. Anschließend wurde LLaVA-Med (Large Language and Vision Assistant for BioMedicine) mit einem von GPT-4 generierten Instruktionsdatensatz verfeinert.
Dieser Datensatz wird von GPT-4 auf der Basis von biomedizinischen Texten erstellt, die alle Informationen zu den jeweiligen Bildern enthalten und somit zur Generierung von Frage-Antwort-Paaren zu den Bildern verwendet werden können. In der Feinabstimmung wird LLaVA-Med dann mit den Bildern und den entsprechenden GPT-4 Beispielen trainiert.

Das Ergebnis ist ein Assistent, der Fragen zu einem biomedizinischen Bild in natürlicher Sprache beantworten kann.
LLaVA-Med wurde in 15 Stunden trainiert
Das verwendete Trainingsverfahren ermöglichte es, LLaVA-Med in weniger als 15 Stunden auf acht Nvidia A100-Grafikprozessoren zu trainieren. Als Basis dienen ein Vision Transformer und das Sprachmodell Vicuna, das wiederum auf Metas LLaMA aufbaut. Dem Team zufolge verfügt das Modell über "ausgezeichnete multimodale Gesprächsfähigkeiten". In drei biomedizinischen Standarddatensätzen zur Beantwortung visueller Fragen übertrifft LLaVA-Med frühere State-of-the-Art-Modelle in einigen Metriken.
Multimodale Assistenten wie LLaVA-Med könnten eines Tages in verschiedenen biomedizinischen Anwendungen eingesetzt werden, etwa in der medizinischen Forschung, bei der Interpretation komplexer biomedizinischer Bilder und als Gesprächsunterstützung im Gesundheitswesen.
Aber die Qualität ist noch nicht gut genug: "Obwohl wir glauben, dass LLaVA-Med ein wichtiger Schritt auf dem Weg zu einem nützlichen biomedizinischen visuellen Assistenten ist, stellen wir fest, dass LLaVA-Med durch Halluzinationen und schwache logische Fähigkeiten, die vielen großen Sprachmodellen eigen sind, eingeschränkt ist", so das Team. Zukünftige Arbeiten werden sich auf die Verbesserung der Qualität und Zuverlässigkeit konzentrieren.
Mehr Informationen gibt es auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.