OpenAI nennt GPT-4 Turbo das "smarteste" Modell, aber das bedeutet nicht viel

Ist GPT-4 Turbo "smarter" als GPT-4, wie von Sam Altman angekündigt? Und was heißt das überhaupt?
OpenAIs neuestes KI-Modell GPT-4 Turbo ist als Preview über die OpenAI API und direkt in ChatGPT verfügbar. Seit der Veröffentlichung der Preview am 06. November gab es bereits ein Update des Modells.
Laut OpenAI CEO Sam Altman ist GPT-4 Turbo "viel schneller", "smarter" und vor allem billiger als GPT-4. Während Geschwindigkeit und Preis offensichtlich sind, wird die "Smartness" des neuen Modells in Foren und sozialen Medien heftig diskutiert. Einige berichten von offensichtlichen Leistungseinbußen und sehen die Fähigkeiten von GPT-4 seit der ersten Version stetig abnehmen, andere berichten von Verbesserungen, wieder andere von Gewinnen in einigen Anwendungsfällen und Verlusten in anderen.
GPT-4 vs. GPT-4 Turbo im Code-Benchmark
Beispielsweise haben die Entwickler von Mentat AI, einem KI-basierten Coding-Assistenten, das neue Modell in Coding-Aufgaben getestet. GPT-4 (gpt-4-0314) löste 86 von 122 Aufgaben, während GPT-4 Turbo (gpt-4-1106-preview) 84 von 122 Aufgaben löste. Ein genauerer Blick auf die Ergebnisse zeigte jedoch, dass GPT-4 76 Aufgaben im ersten Versuch und 10 im zweiten Versuch löste, während GPT-4 Turbo nur 56 Aufgaben im ersten Versuch und 28 im zweiten Versuch löste.
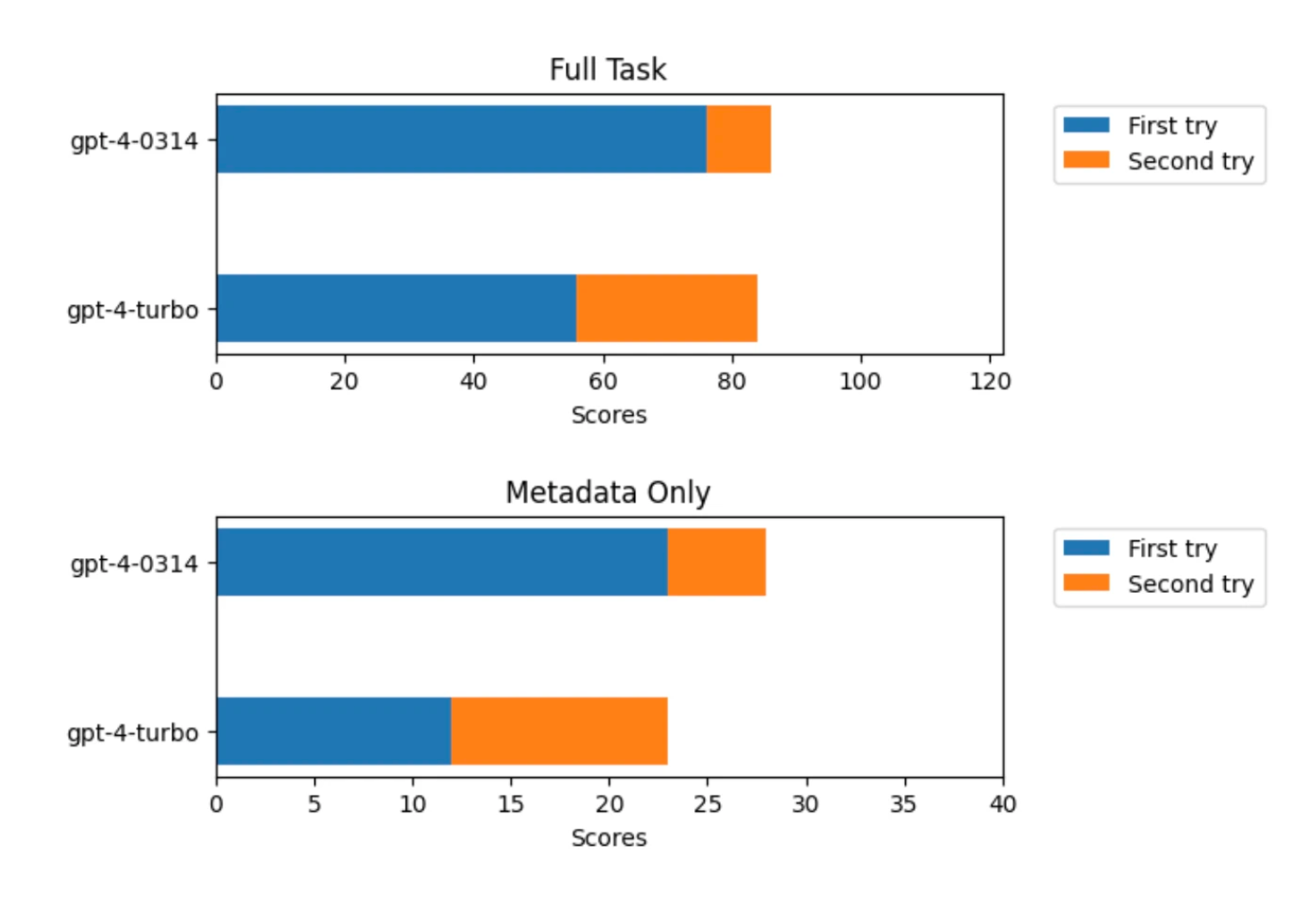
Das Team vermutet daher, dass GPT-4 einen großen Teil der Trainingsaufgaben auswendig gelernt hat und dieses Wissen bei GPT-4 Turbo durch Optimierungen wie Destillation verloren gegangen sein könnte. Um diese Theorie zu testen, wiederholte das Team die Benchmarks, ohne den Modellen die Instruktionen für jede Aufgabe zu zeigen, sondern nur die Namen der Aufgaben, die Funktionen und einen Hinweis auf die Quelle der Tests. Ohne die Instruktionen kann ein KI-Modell die Aufgaben nur lösen, wenn es sie auswendig gelernt hat.
GPT-4 konnte fast 60 Prozent der Aufgaben lösen, GPT-4 Turbo nur 30 Prozent. Das Team interpretiert diese Ergebnisse als klaren Hinweis darauf, dass GPT-4 mehr Aufgaben auswendig gelernt hat als GPT-4 Turbo. Nach diesen Ergebnissen könnte GPT-4 also eine Art "Gedächtnisbonus" haben, der dem Modell in einigen Benchmarks - und in der Praxis - einen Vorteil verschafft. In anderen Anwendungsfällen könnte dies natürlich auch ein Nachteil sein, z.B. wenn es gespeicherte Codeblöcke ausspuckt, anstatt nach einer effizienteren Lösung zu suchen.
Aider, ein weiterer KI-Assistent für die Coding, hat das neue Modell ebenfalls mit Coding-Aufgaben getestet. Demnach ist GPT-4 Turbo erwartungsgemäß deutlich schneller als die bisherigen GPT-4-Modelle. Genaue Messungen sind aufgrund der derzeitigen Einschränkungen von OpenAI noch nicht möglich. Außerdem scheint es besser darin zu sein, beim ersten Versuch korrekten Code zu erzeugen. Es löst 53 % der Codeaufgaben, während frühere Modelle nur 46-47 % der Aufgaben beim ersten Versuch lösen. Zudem scheint GPT-4 Turbo im Allgemeinen ähnlich gut zu funktionieren (~62 %) wie die alten Modelle (63-64 %), nachdem sie eine zweite Chance zur Fehlerkorrektur erhalten haben, indem sie die Fehlerausgabe der Testsuite überprüfen.
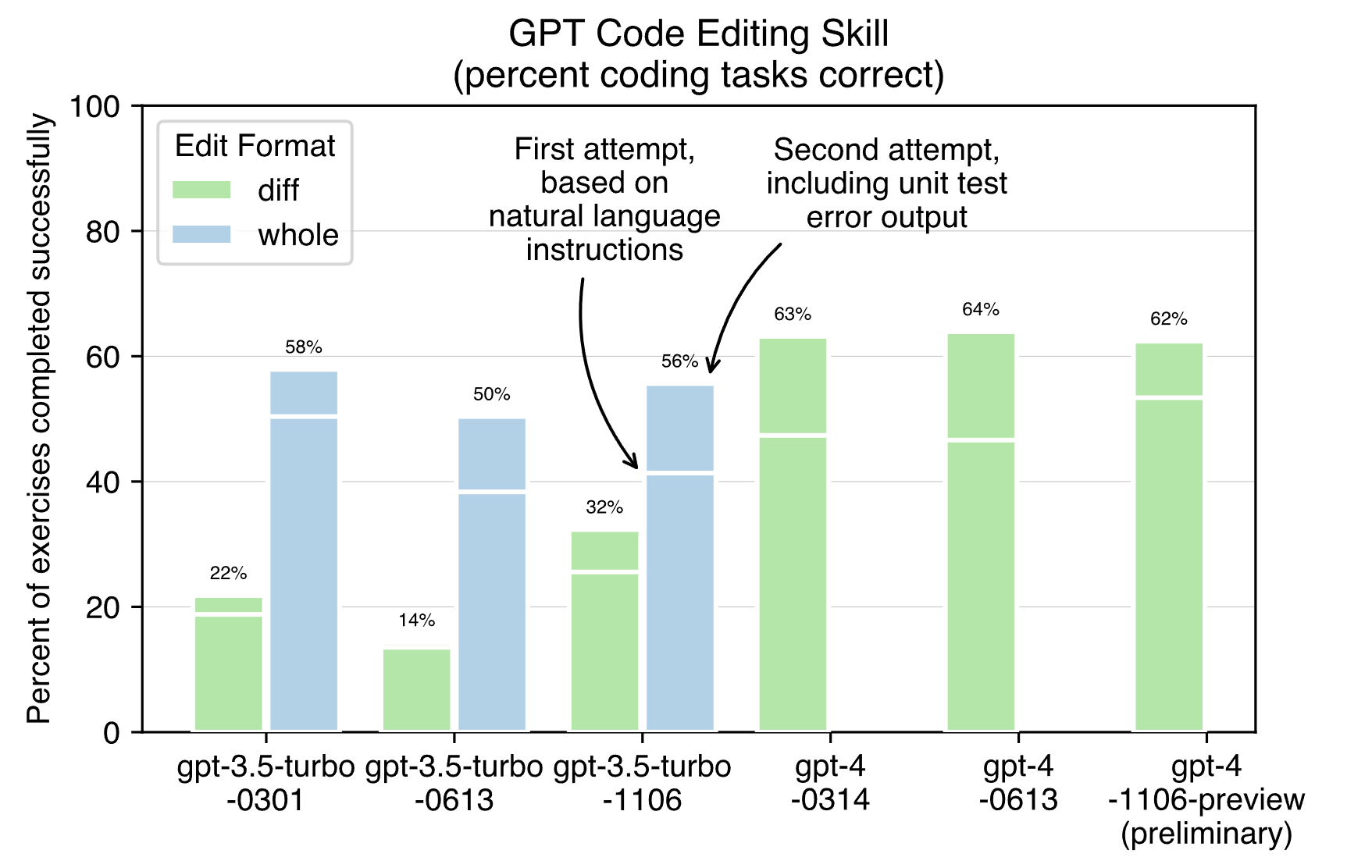
Das getestete GPT-4-Modell wird voraussichtlich im Juni 2024 außer Betrieb genommen.
GPT-4 Turbo nutzt wohl Chain-of-Thought
In einem weiteren Test zeigt der X-Benutzer Vlad, CEO von KagiHQ, die Leistung der beiden Modelle im PyLLM-Benchmark. Den Ergebnissen zufolge hat GPT-4 Turbo eine Genauigkeit von 87 % gegenüber 52 % bei GPT-4 und ist mit 48 gegenüber 10 Token pro Sekunde fast fünfmal schneller. Zudem ist GPT-4 Turbo in der Praxis um 30 % billiger. Laut Vlad könnte es sogar noch billiger sein - aber die Ausgabe ist im Durchschnitt 2 mal wortreicher als die von GPT-4. Eine mögliche Erklärung für diesen Leistungssprung hat ein anderer Nutzer, der darauf hinweist, dass GPT-4 Turbo im Hintergrund automatisch Chain-of-Thought-Prompting zu verwenden scheint - was auch die längeren Ausgaben erklären würde. Aber selbst mit CoT liegt die Genauigkeit von GPT-4 nur bei knapp 60 Prozent.
GPT-4 Turbo vs GPT-4 tests fresh from the oven
GPT-4 Turbo has record accuracy (87% vs 52% of GPT-4 on PyLLMs benchmark), it is almost 5x faster with 48 vs 10 tokens/sec). And it is also 30% cheaper in practice (would be more, but it is 2x wordier in output compared to GPT-4) pic.twitter.com/1fjqKpehrD
— Vlad (@vladquant) November 6, 2023
Der X-Benutzer Jeffrey Wang, Mitbegründer von Metaphor Systems, testete das neue Modell mit SAT-Lesetests, bei denen das Modell Antworten auf Texte geben muss. Seinen Ergebnissen zufolge macht GPT-4 Turbo deutlich mehr Fehler als GPT-4 und erzielt daher eine niedrigere Punktzahl.
OpenAI claims GPT4-turbo is “better” than GPT4, but I ran my own tests and don’t think that's true.
I benchmarked on SAT reading, which is a nice human reference for reasoning ability. Took 3 sections (67 questions) from an official 2008-2009 test (2400 scale) and got the… pic.twitter.com/LzIYS3R9ny
— Jeffrey Wang (@wangzjeff) November 7, 2023
OpenAIs Mangel an Transparenz könnte eine Chance für die Konkurrenz sein
Ist GPT-4 Turbo also "smarter"? Eine klare Antwort gibt es noch nicht - zumindest nicht, wenn man "smarter" als "besser" versteht. Ein deutlicher Leistungssprung ist jedoch bisher nicht zu erkennen. Die offene Wortwahl - "smart" kann vieles bedeuten, auch eine höhere Ressourceneffizienz im Verhältnis zur Leistung - ist also bewusst gewählt. Altman hätte wahrscheinlich gesagt, dass GPT-4 Turbo intelligenter oder leistungsfähiger als GPT-4 ist, wenn dies eindeutig der Fall wäre.
Der Fokus der Präsentation lag daher auf den neuen "smarten" Features: GPT-4 Turbo kann mehr Text verarbeiten, hat einen JSON-Modus und mehr Modalitäten integriert, kann Funktionen zuverlässiger aufrufen und hat aktuelleres Wissen.
Zudem hat OpenAI im Gegensatz zu GPT-4 für GPT-4 Turbo bisher keine Modellkarte oder Benchmarks veröffentlicht - ein Trend, der bereits mit dem letzten Update von GPT-4 begann, dessen Fähigkeiten ebenfalls immer wieder in der Kritik standen. Diese Intransparenz führt dazu, dass es der Community überlassen bleibt, herauszufinden, welches Modell für welche Aufgaben am besten geeignet ist und wie es am genauesten gesteuert werden muss. Die hier angeführten Beispiele sind dafür aufgrund der geringen Stichprobengröße nicht ausreichend. Noch komplizierter wird es bei ChatGPT, wo OpenAI weitere Systeme zwischenschaltet.
Die Frage, welches Modell nun besser und nicht nur "smarter" ist, bleibt also offen - ebenso wie die Frage, ob sie überhaupt mit Benchmarks beantwortet werden kann. Denn inwieweit diese immer die Erfahrungen im praktischen Einsatz widerspiegeln, ist ebenfalls zumindest unklar. Für die Endkunden wäre es dennoch wünschenswert, wenn OpenAI etwas offener über die konkreten Verbesserungen und Fähigkeiten der neuen Modelle sprechen würde, damit sie eine informierte Entscheidung treffen können. Wenn OpenAI diese Rolle nicht übernimmt, könnte die Konkurrenz, etwa von Google, diese Aufgabe übernehmen. Die mangelnde Transparenz könnte eine Chance für Google sein, mit Gemini klare Vorteile gegenüber dem Angebot von OpenAI herauszustellen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.