Das "Wunder" großer KI-Modelle ist womöglich nur eine Illusion

Sind emergente Fähigkeiten in großen Sprachmodellen wie GPT-4 nur eine Illusion? Eine neue Studie zeigt: Es kommt darauf an, wie man misst.
Das Auftreten emergenter Fähigkeiten, also (vermeintlich) plötzlich, fast wundersam auftretender Eigenschaften in großen KI-Netzwerken, gilt als gesichert. Es ist ein Grund für und gegen die weitere Skalierung großer Sprachmodelle: OpenAIs GPT-3 konnte ab einer bestimmten Anzahl von Parametern einfache mathematische Aufgaben lösen, und ein Google-Forscher zählte nicht weniger als 137 emergente Fähigkeiten, die sich beispielsweise im NLP-Benchmark BIG-Bench zeigten.
Im Allgemeinen werden emergente Fähigkeiten als solche definiert, die in Modellen ab einer bestimmten Größe sprunghaft und in kleineren Modellen nicht auftreten. Das Auftreten solcher Sprünge hat zu zahlreichen Forschungsarbeiten geführt, die sich mit dem Ursprung solcher Fähigkeiten und vor allem mit ihrer Vorhersagbarkeit befassen. Denn in der Alignment-Forschung wird das sprunghafte und unvorhersehbare Auftreten von KI-Fähigkeiten als Warnsignal dafür gesehen, dass hochskalierte KI-Netzwerke eines Tages ohne Vorwarnung unerwünschte und gefährliche Fähigkeiten entwickeln.
In einer neuen Forschungsarbeit zeigen Forschende der Stanford University nun, dass Modelle wie GPT-3 zwar rudimentäre mathematische Fähigkeiten entwickeln, dass es aber von der Art der Messung abhängt, ob dies sprunghaft geschieht oder nicht.
Emergente Fähigkeiten sind ein Ergebnis einer bestimmten Metrik
"Wir stellen die Behauptung in Frage, dass LLMs über emergente Fähigkeiten verfügen, worunter wir insbesondere abrupte und unvorhersehbare Änderungen in den Modellergebnissen als Funktion der Modellgröße für bestimmte Aufgaben verstehen."
Normalerweise wird die Fähigkeit als Genauigkeit gemessen, d.h. der Anteil der richtigen Vorhersagen an der Gesamtzahl der Vorhersagen. Diese Messung ist nicht linear, und Änderungen in der Genauigkeit werden als Sprünge sichtbar, so das Team.
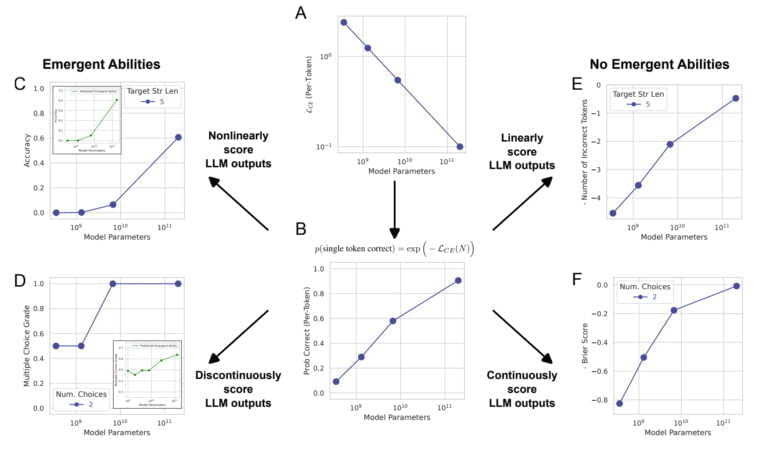
"Unsere alternative Erklärung ist, dass die emergenten Fähigkeiten Illusionen sind, die hauptsächlich darauf zurückzuführen sind, dass das Forschungsteam eine Metrik gewählt hat, die die Fehlerraten pro Token nichtlinear oder diskontinuierlich verzerrt, und dass es zum Teil zu wenige Testdaten hat, um die Leistung kleinerer Modelle genau zu schätzen (wodurch kleinere Modelle völlig unfähig erscheinen, die Aufgabe zu erfüllen), und zum Teil zu wenige große Modelle evaluiert hat", heißt es in der Arbeit.
Verwendet man stattdessen eine lineare Messmethode, wie die Token Edit Distance, eine Metrik, die die minimale Anzahl einzelner Tokenänderungen (Einfügungen, Löschungen oder Ersetzungen) berechnet, die notwendig sind, um eine Tokensequenz in eine andere umzuwandeln, ist kein Sprung mehr sichtbar - stattdessen ist eine "glatte, kontinuierliche und vorhersagbare" Verbesserung mit steigender Anzahl von Parametern zu beobachten.
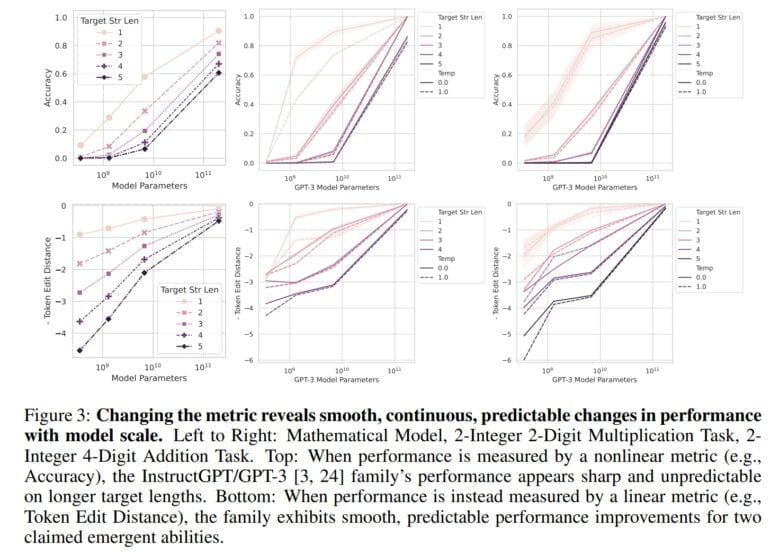
Das Team zeigt in seiner Arbeit, dass die emergenten Fähigkeiten von GPT-3 und anderen Modellen, zum Beispiel in BIG-Bench, auf solche nichtlinearen Messungen zurückgeführt werden können und dass bei einer linearen Messung keine drastischen Sprünge erkennbar sind. Darüber hinaus reproduzieren die Forschenden diesen Effekt mit Computer-Vision-Modellen, in denen bisher keine emergenten Fähigkeiten gemessen wurden.
Emergente Fähigkeiten sind "wahrscheinlich eine Illusion"
"Die wichtigste Schlussfolgerung ist, dass Forschende für eine bestimmte Aufgabe und eine bestimmte Modellfamilie eine Metrik wählen können, die eine emergente Fähigkeit erzeugt, oder eine Metrik wählen können, die eine emergente Fähigkeit unterdrückt", so das Team. "Folglich können emergente Fähigkeiten das Ergebnis von Entscheidungen der Forschenden sein und nicht eine grundlegende Eigenschaft der Modellfamilie für eine bestimmte Aufgabe."
Das Team betont jedoch, dass diese Arbeit nicht so interpretiert werden sollte, dass große Sprachmodelle wie GPT-4 keine emergenten Fähigkeiten haben können. "Unsere Botschaft ist vielmehr, dass die früher behaupteten emergenten Fähigkeiten wahrscheinlich eine Illusion sind, die durch die Analyse der Forschenden hervorgerufen wurde".
Für die Alignment-Forschung könnte diese Arbeit eine gute Nachricht sein, da sie die Vorhersagbarkeit von Fähigkeiten in großen Sprachmodellen zu belegen scheint. Auch OpenAI hat in einem Bericht über GPT-4 gezeigt, dass es die Leistung von GPT-4 in vielen Benchmarks genau vorhersagen kann.
Da das Team jedoch die Möglichkeit des Auftretens emergenter Fähigkeiten nicht ausschließt, stellt sich die Frage, ob solche Fähigkeiten bereits existieren. Ein Kandidat könnte das "Few-Shot-Learning" oder "In-Context-Learning" sein, dass das Team in dieser Arbeit nicht untersucht. Diese Fähigkeit wurde erstmals bei GPT-3 im Detail nachgewiesen und bildet die Grundlage für das heute so verbreitete Prompt-Engineering.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.