Studie lässt (wieder) am Nutzen großer Kontextfenster zweifeln

Eine grundlegende Entscheidung beim Einsatz großer Sprachmodelle: Speichert man eigene Informationen extern und ruft sie per RAG ab oder fügt man sie dank großer Kontextfenster direkt in den Prompt ein? Eine neue Studie weist in eine klare Richtung.
Die Kontextfenster großer Sprachmodelle sind über die letzten Jahre rapide gewachsen. Während GPT-3 etwa noch nur rund 2.000 Token pro Prompt verarbeiten konnte, versteht das neuste OpenAI-Modell GPT-4o bis zu 128.000. Das Unternehmen Magic AI wirbt bei seinem kürzlich vorgestellten Modell sogar mit einem Kontextfenster von bis zu 100 Millionen Token.
Das lässt manche an der Notwendigkeit von Retrieval-Augmented Generation (RAG) zweifeln. Bei RAG werden Informationen üblicherweise zunächst in einer Vektordatenbank gespeichert und dynamisch bei jeder Anfrage abgerufen.
Eine neue Studie von Nvidia-Forschenden stellt diese Annahme, dass man RAG mit wachsenden Kontextfenstern nicht brauchen würde, in Frage. Sie zeigt, dass RAG in Kombination mit einem bestimmten Mechanismus LLMs mit großen Kontextfenstern übertreffen kann.
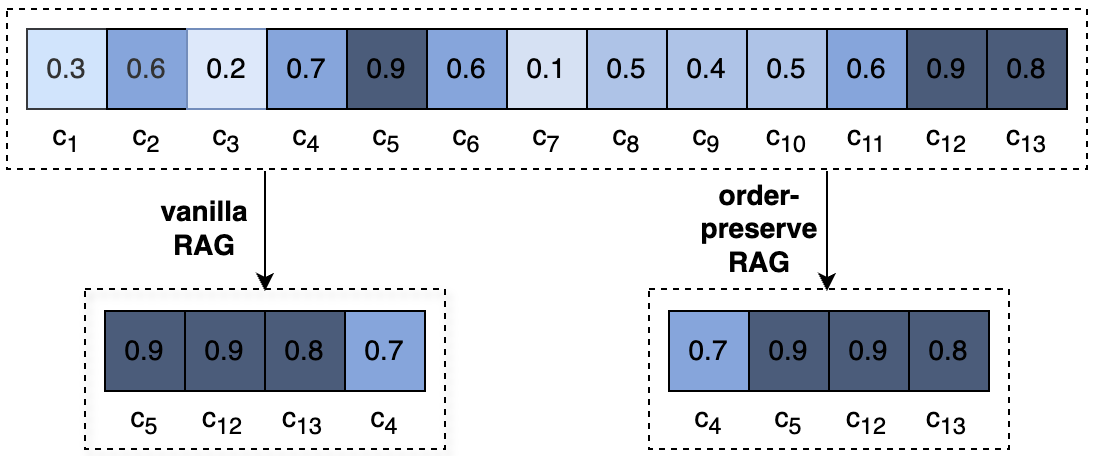
Das Paper "In Defense of RAG in the Era of Long-Context Language Models" schlägt konkret einen reihenfolgeerhaltenden RAG-Ansatz (OP-RAG, OP steht für order-preserving) vor, der die ursprüngliche Reihenfolge der abgerufenen Teile (Chunks) im LLM-Kontext beibehält. Dies steht im Gegensatz zu herkömmlichen RAG-Methoden, die die Chunks meist nach absteigender Relevanz anordnen.
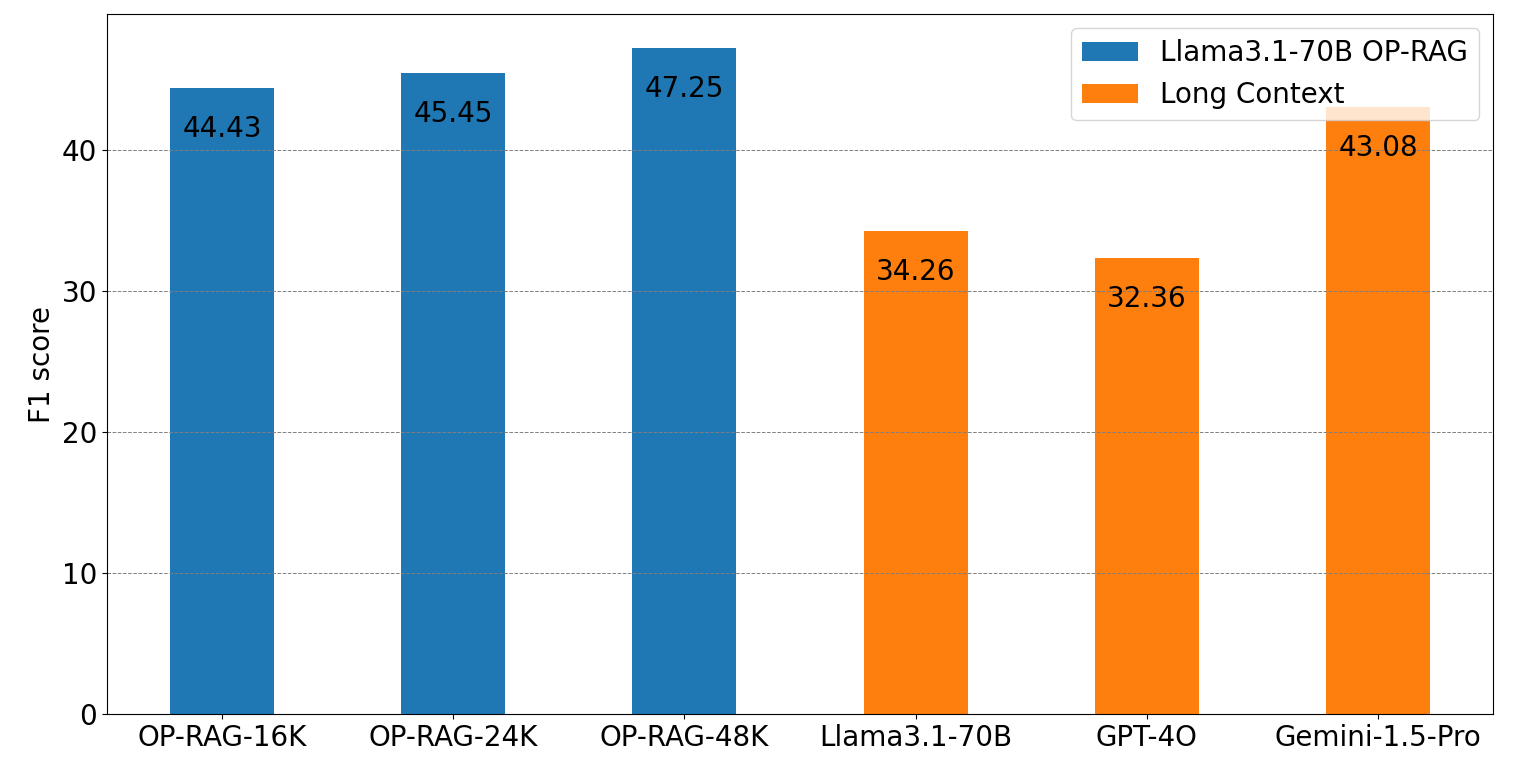
RAG übertrifft langen Kontext deutlich
Die Forschenden bewerteten ihren OP-RAG-Ansatz anhand der En.QA- und En.MC-Datensätze des ∞Bench-Benchmarks. Dieser ist speziell für Frage-Antwort-Aufgaben mit langem Kontext konzipiert. Sie fanden heraus, dass OP-RAG mit dem LLaMA-3.1-70B-Modell einen F1-Score von 44,43 erreichte, während nur 16.000 abgerufene Token verwendet wurden.
Der F1-Score ist ein Maß im maschinellen Lernen, das Genauigkeit (Precision) und die Fähigkeit, bestimmte Informationen abzurufen (Recall), ausbalanciert. Im Vergleich dazu erzielte dasselbe Modell ohne RAG mit seinem vollen 128.000-Token-Kontextfenster nur einen Wert von 34,32. GPT-4o und Gemini-1.5-Pro erreichten ohne RAG F1-Scores von 32,36 bzw. 43,08.
Die Studie untersuchte auch den Einfluss der Kontextlänge auf die Leistung von OP-RAG. Die Ergebnisse zeigten, dass die Antwortqualität mit zunehmender Kontextlänge zunächst verbessert, dann aber abnahm.
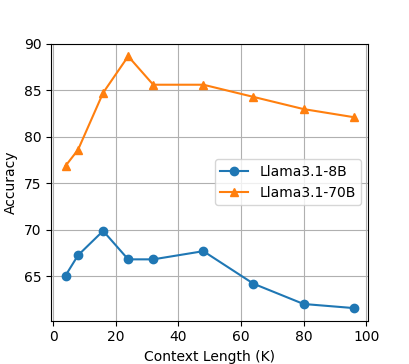
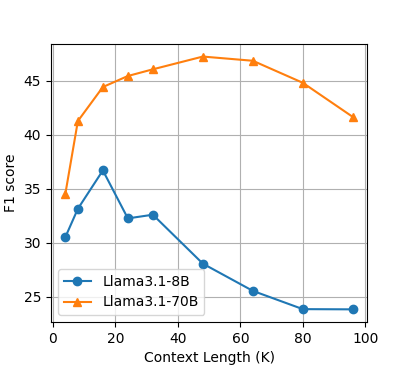
Die Forscher:innen führen dies auf den Kompromiss zwischen dem Abruf potenziell relevanter Informationen und der Einführung irrelevanter oder ablenkender Informationen zurück. Sie fanden heraus, dass die optimale Balance die Antwortqualität maximiert. Über diesen Punkt hinaus verschlechtert die Einbeziehung zu vieler irrelevanter Informationen die Leistung des Modells.
Richtige Reihenfolge verbessert RAG-Abruf
Darüber hinaus verglichen die Forschenden OP-RAG mit herkömmlichem RAG. Sie stellten fest, dass OP-RAG bei einer großen Anzahl abgerufener Chunks deutlich besser abschnitt. Beim En.QA-Datensatz erreichte OP-RAG beispielsweise einen F1-Score von 44,43 beim Abruf von 128 Chunks, während herkömmliches RAG nur einen Score von 38,40 erzielte.
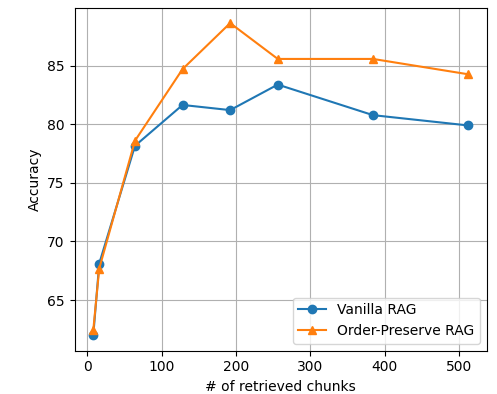
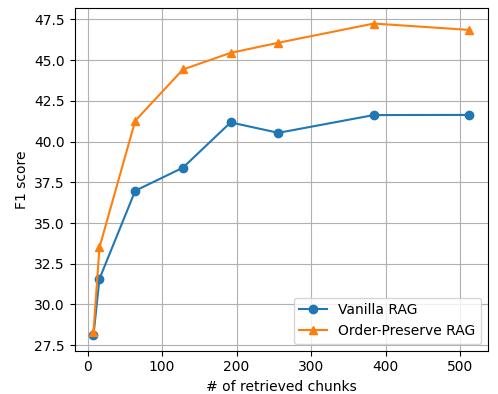
Die Ergebnisse weisen in die entgegengesetzte Richtung als vorherige Forschungen. Paper wie jenes von Li et al. aus dem Juli 2024 argumentierten, dass Long-Context-LLMs RAG-Ansätze in Bezug auf die Antwortqualität durchweg übertreffen würden.
Die Einführung von Sprachmodellen mit großen Kontextfenstern ging ohnehin immer mit Kritik einher. Auch wenn Modelle theoretisch hunderttausende Token als Prompt akzeptieren, gehen Informationen aus der Mitte häufig verloren: das sogenannte "Lost in the Middle"-Phänomen.
Trotz Fortschritten auf diesem Gebiet scheint das Problem noch nicht vollständig gelöst zu sein. Modelle mit kleineren Kontextfenstern punkten außerdem unter anderem mit geringerem Energieverbrauch.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.